
The controversy surrounding Meta's Llama 4 'herd': Examining the AI
In the fast-evolving realm of artificial intelligence, one piece of recent news has captured the industry's attention: Meta's launch of its Llama 4 'herd' over the weekend. This new suite promises cutting-edge generative AI capabilities through three interconnected models, Behemoth, Scout, and Maverick. However, the rollout was met with mixed responses—prompting concerns surrounding what some label as ‘AI contamination’ and questions regarding the performance claims made by Meta. As whispers of potential unrest within the company circulated, the Llama 4 launch turned into a cautionary tale, demonstrating the delicate balance between ambition and integrity in AI advancements.
Dissecting Llama 4's Debut
In this article, we will dissect the implications of Llama 4's debut, explore the allegations of performance manipulation, and place this controversy in the broader context of the evolving AI landscape—a space where reputations can waver with the slightest tremor.
The Three Tiers of Llama 4
Meta's Llama 4 models are categorized into three tiers: Behemoth, Scout, and Maverick. The Behemoth model, still under development, is touted to wield a staggering two trillion parameters—making it the flagship of the herd denoted as “one of the smartest LLMs in the world.” The ambition encapsulated in this claim resonates with increasing trends of large language models (LLMs), where the sheer size and complexity of models are often seen as markers of prowess.
Scout and Maverick, the two smaller models, implement a method known as "distillation," allowing them to benefit from Behemoth's computational power while being more efficient. This strategy aligns with an industry-wide trend aiming for greater performance with minimized resource expenditures.
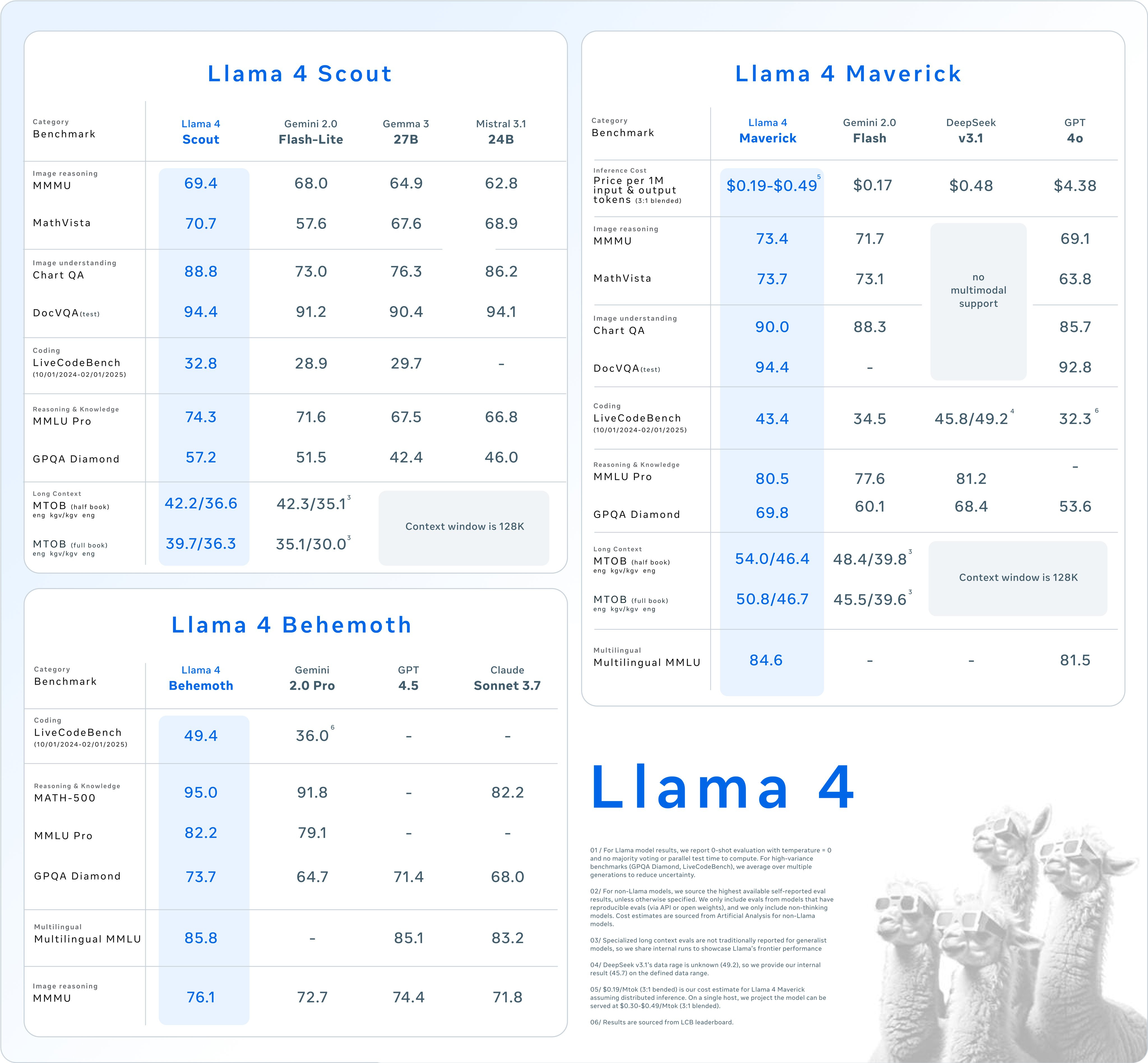
Controversy Erupts
Despite the impressive specifications, immediately following the announcement of Llama 4, controversy erupted. Soon after the models debuted, a wave of skepticism began to circulate. Central to this was the emergence of an anonymous posting claiming that members of Meta's AI development team were discontented with Llama 4's performance compared to “state-of-the-art” models.
Allegations of Performance Manipulation
Gary Marcus, a well-known AI scholar and critic, amplified these concerns via his Substack newsletter. He highlighted a fundamental problem many modern AI companies, including OpenAI, are encountering: a phenomenon known for years as diminishing returns. This speaks to an inherent issue where expanding the size or complexity of models does not yield commensurate improvements in performance.
The anonymous claims focused on what’s termed ‘contamination’—the problem of using data that may have been derived from the same training sets as the benchmarking tests. In response, Ahmad Al-Dahle, Meta's vice president of generative AI, categorically denied these claims, asserting that the company “would never train on test sets.”
User Experiences and Criticisms
The controversy amplified when Llama 4's purported achievements were juxtaposed alongside user experiences. Shortly after launching, Llama 4 was celebrated by LMArena, a site hosting various AI chatbot benchmarks, which designated it the “number one open model, surpassing DeepSeek.” While this accolade suggested a mark of excellence, many users reported performance inconsistencies—a variance categorized as variable quality.
Evolving Landscape of AI
The Llama series, including the newly launched fourth generation, is part of a broader narrative that encapsulates the evolution of AI over the last decade. Starting from the relatively primitive language models of earlier years, the industry has seen transformative advancements reflecting an insatiable hunger for greater capability.
Future Implications
As the Meta Llama 4 controversy simmers, industry observers are compelled to ask questions about the future of AI development. Will companies rectify their training processes to support ethical standards, or will they continue to push forward at any cost? The current environment has not only illuminated potential pitfalls in model evaluations but has also challenged industry leaders to reassess what makes AI inherently valuable.
Conclusion
As Meta moves forward, the company must navigate the criticism and adjust its strategy to manage brand reputation, transparency, and efficacy. It remains to be seen how the echoes of these controversies will shape the scope of AI research, development, and deployment practices in the months and years to come.



















