
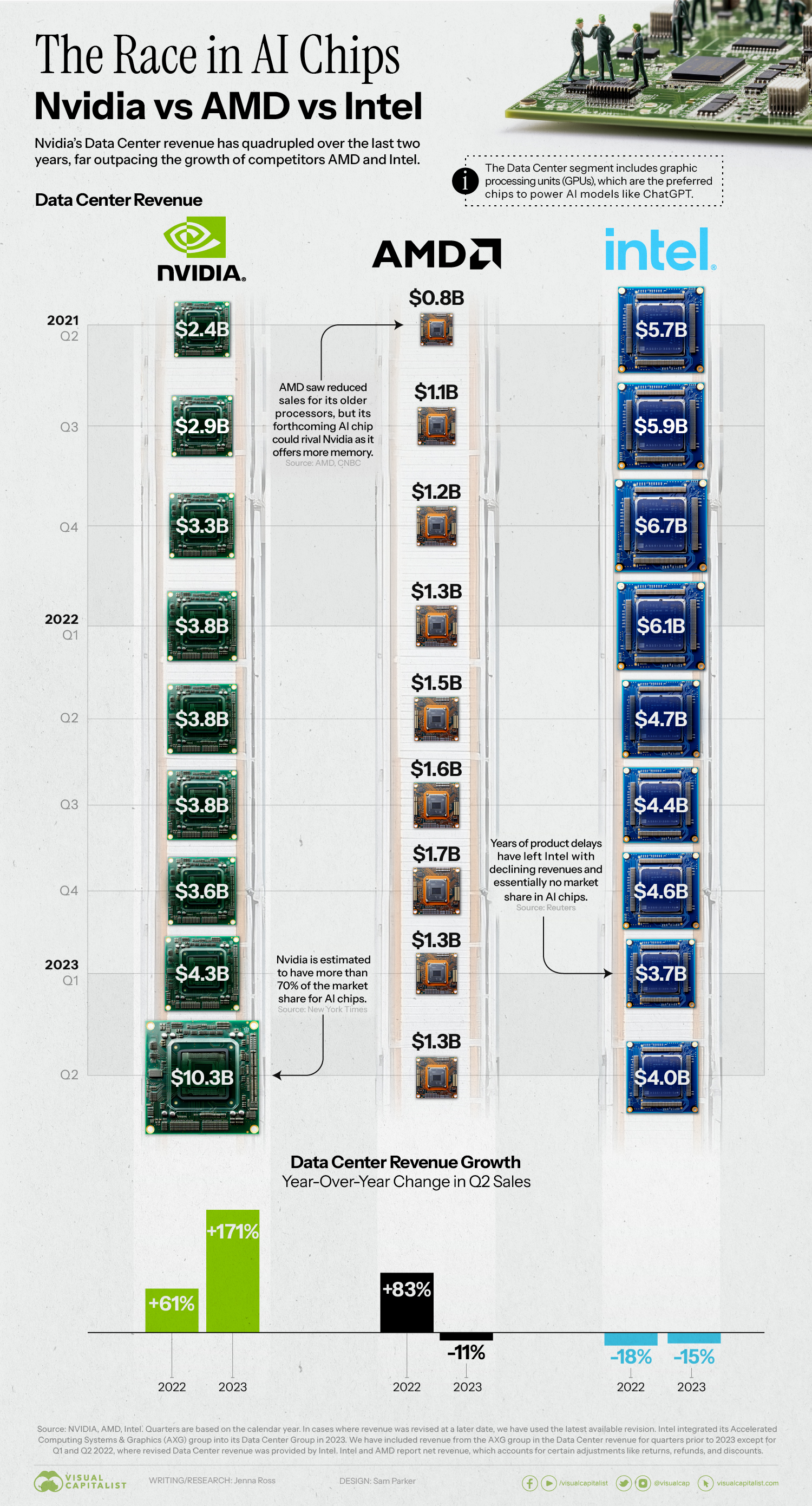
Daniel D. Gutierrez, Principal Analyst & Resident Data Scientist ...

May 14Posted by Daniel D. Gutierrez, Principal Analyst & Resident Data Scientist
The NR1® AI Inference Appliance, powered by the first true AI-CPU, now comes pre-optimized with Llama, Mistral, Qwen, Granite, and other generative and agentic AI models – making it 3x faster to deploy with far better price/performance results.
NeuReality, a pioneer in reimagining AI inferencing architecture for the demands of today’s AI models and workloads, announced that its NR1 Inference Appliance now comes preloaded with popular enterprise AI models, including Llama, Mistral, Qwen, Granite1, plus support for private generative AI clouds and on premise clusters. Up and running in under 30 minutes, the generative and agentic AI-ready appliance delivers 3x better time-to-value, allowing customers to innovate faster.
The NR1 Chip
Inside the appliance, the NR1® Chip is the first true AI-CPU purpose built for inference orchestration – the management of data, tasks, and integration – with built-in software, services, and APIs. It not only subsumes traditional CPU and NIC architecture into one but also packs 6x the processing power onto the chip to keep pace with the rapid evolution of GPUs, while removing traditional CPU bottlenecks.
A Breakthrough in Cost Efficiency

The NR1 Chip pairs with any GPU or AI accelerator inside its appliance to deliver breakthrough cost, energy, and real-estate efficiencies critical for broad enterprise AI adoption. For example, comparing the same Llama 3.3-70B model and the identical GPU or AI accelerator setup, NeuReality’s AI-CPU powered appliance achieved a lower total cost per million AI tokens versus x86 CPU-based systems.
“No one debates the incredible potential of AI. The challenge is how to make it economical enough for companies to deploy AI inferencing at scale. NeuReality’s disruptive AI-CPU technology removes the bottlenecks allowing us to deliver the extra performance punch needed to unleash the full capability of GPUs, while orchestrating AI queries and tokens that maximize performance and ROI of those expensive AI systems,” said Moshe Tanach, Co-founder and CEO at NeuReality.
“Now, we are taking ease-of-use to the next level with an integrated silicon-to-software AI inference appliance. It comes pre-loaded with AI models and all the tools to help AI software developers deploy AI faster, easier, and cheaper than ever before, allowing them to divert resource to applying AI in their business instead of in Infrastructure integration and optimizations,” continued Tanach.
AI Adoption Trends
A recent study found that roughly 70% of businesses report using generative AI in at least one business function, showing increased demand. Yet only 25% have processes fully enabled by AI with widespread adoption and only one-third have started implementing limited AI use cases according to Exploding Topics.
NeuReality's Solution
Already deployed with cloud and financial services customers, NeuReality’s NR1 Appliance was specifically designed to accelerate AI adoption through its affordability, accessibility, and space efficiency for both on-premises and cloud inference-as-a-service (IaaS) options. Along with new pre-loaded generative and agentic AI models, with new releases each quarter, it comes fully optimized with preconfigured software development kits and APIs for computer vision, conversational AI or custom requests that support a variety of business use cases and markets (e.g. financial services, life sciences, government, cloud service providers).
The first NR1 Appliance unifies NR1® Modules (PCIe cards) with Qualcomm® Cloud AI 100 Ultra accelerators. More information on the NR1 Appliance, Module, Chip, and NeuReality® Software and Services please visit: https://www.neureality.ai/solution.1
AI models pre-loaded and pre-optimized for enterprise customers include: Llama3.3 70B, Llama 3.1 8B (with Llama 4 series coming soon); Mistral7B, Mistral 8x7B and Mistral Small; Qwen 2.5 including Coder (with Qwen 3 coming soon); DeepSeek R1–Distill-Llama 8B, R1 Distill-Llama 70b; and Granite3, 3.1 8B (with Granite 3.3 coming soon).
Posted in AI, GenAI, Hardware, News, Uncategorized









