
Introduction
OpenAI has unveiled its latest innovation, the multi-agent retriever augmented generation system, which eliminates the need for chunking and embeddings by utilizing long context models like GPT 4.1.
Document Processing Simplified
The system simplifies the document processing phase by selecting relevant chunks, dividing them into sub-sections, and evaluating their significance at various levels to produce precise answers.
Architecture Breakdown
The system's architecture breakdown includes the utilization of long context LM models such as GPT 4.1 for reasoning, verification, and validating answers to ensure accuracy.
System Workflow and Chunking Process
The workflow of the system involves processing documents into chunks, selecting individual sentences, and generating responses by further breaking down subchunks to pinpoint specific answers.
Implementation Details and Recursive Division
An insightful look into the system's implementation reveals the use of a recursive decomposition function for dividing documents, selecting pertinent chunks, and validating responses for accuracy and confidence scoring.
Cost Analysis and Use Cases
The system's costs are analyzed in terms of fixed and variable expenses, along with its applications in legal documents, trade-offs in different scenarios, and the advantages it offers in latency and scalability considerations.
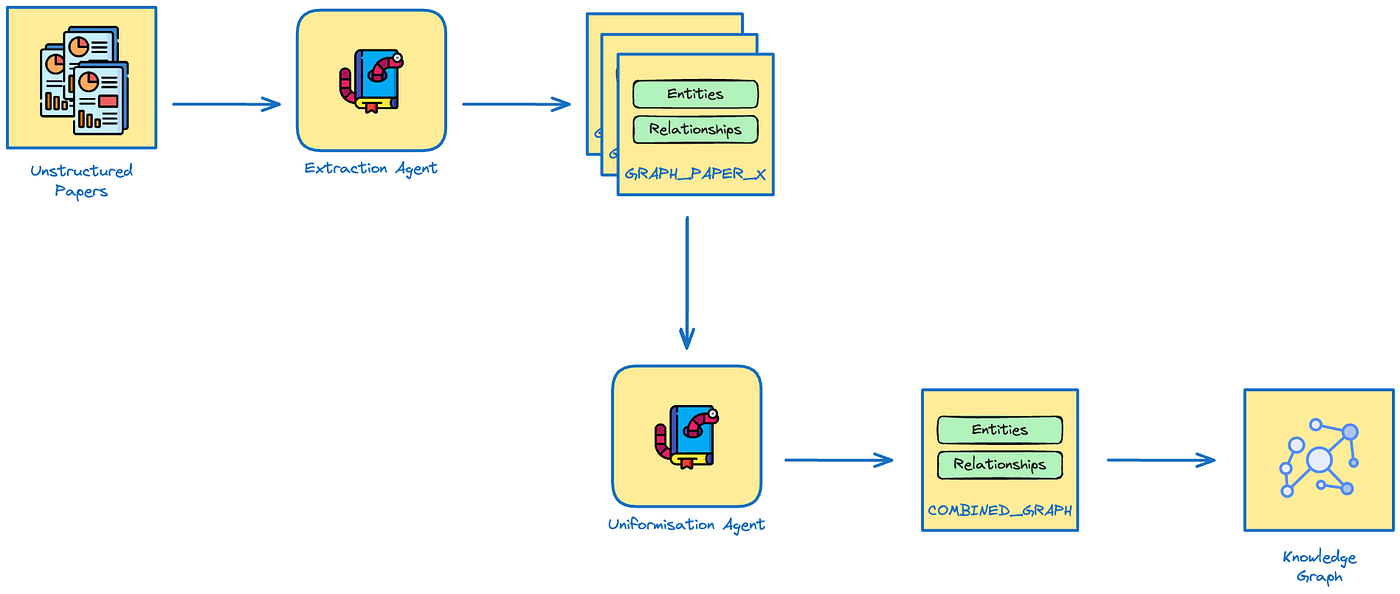
Knowledge Graphs and Information Enhancement
The system also leverages knowledge graphs to incorporate relevant information based on user queries, influencing depth in legal document processing, and enhancing relationships and citations.
FAQ
Q: What is the main purpose of OpenAI's multi-agent retriever augmented generation system?
A: The system aims to simplify the chunking strategy by executing indexing free retrieval through long context models like GPT 4.1 for accurate answers.
Feel free to explore the groundbreaking technology introduced by OpenAI in the multi-agent retriever augmented generation system. Stay ahead of the curve and witness the future of document processing and information retrieval.









