
Canonical AI | LinkedIn
Canonical AI has developed a context-aware semantic cache aimed at reducing latency and cost for LLM applications. The initial focus was on Voice AI developers, as low latency is crucial for optimal user experience. After engaging with numerous individuals involved in building voice or multimodal interactive AI agents, it became apparent that the primary concern was getting the AI agent to function correctly rather than addressing latency and cost issues.

Mixpanel for Interactive AI Agents
Recognizing the need in the market, Canonical AI decided to pivot and create a Mixpanel for voice and multimodal interactive AI agents. This innovative platform offers developers detailed insights into user journeys, identifies reasons behind call failures, and provides both conversational and technical metrics for individual calls.
Voice AI Monitoring and Evaluation
One common challenge in Voice AI applications is the manual process of listening to recordings and analyzing transcripts to troubleshoot issues. To address this, Canonical AI introduced a VoiceAI monitoring and evaluation platform. This platform assists developers in enhancing the quality of their Voice AI agents.
Find out more about the Voice AI monitoring and evaluation platform here.
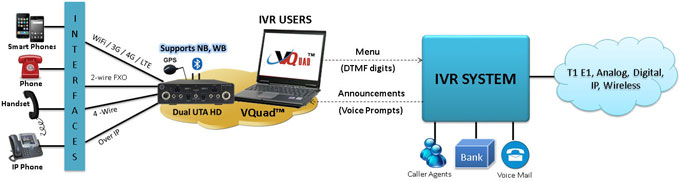
Semantic Caching and Application Optimization
For developers utilizing Generative AI applications with Retrieval Augmented Generation (RAG), Canonical AI offers a context-aware semantic cache. By leveraging this technology, developers can potentially save over 30% of their Large Language Model (LLM) requests.

To learn more about semantic caching and its benefits, visit the link here.
Improved Application Performance
Implementing semantic caching can significantly enhance the performance of Interactive Voice Response (IVR) systems at a more efficient cost compared to traditional LLM approaches. Developers can explore the advantages of semantic caching by visiting this link.
For further information on Canonical AI and their groundbreaking solutions, visit their LinkedIn page here.









