
Google launches 'implicit caching' to make accessing its latest AI models more cost-effective
Google is introducing a new feature in its Gemini API called "implicit caching," designed to reduce costs for third-party developers utilizing its latest AI models. This feature, according to Google, can provide up to 75% savings on repetitive context passed to models through the Gemini API. It is compatible with Google's Gemini 2.5 Pro and 2.5 Flash models.
Cost Savings for Developers
For developers, particularly those using cutting-edge models like Gemini 2.5 Pro, the cost of implementing high-end AI models continues to rise. Implicit caching aims to address this issue by leveraging a practice widely adopted in the AI industry - caching. By reusing frequently accessed or pre-computed data from models, caching helps reduce computing requirements and overall expenses.
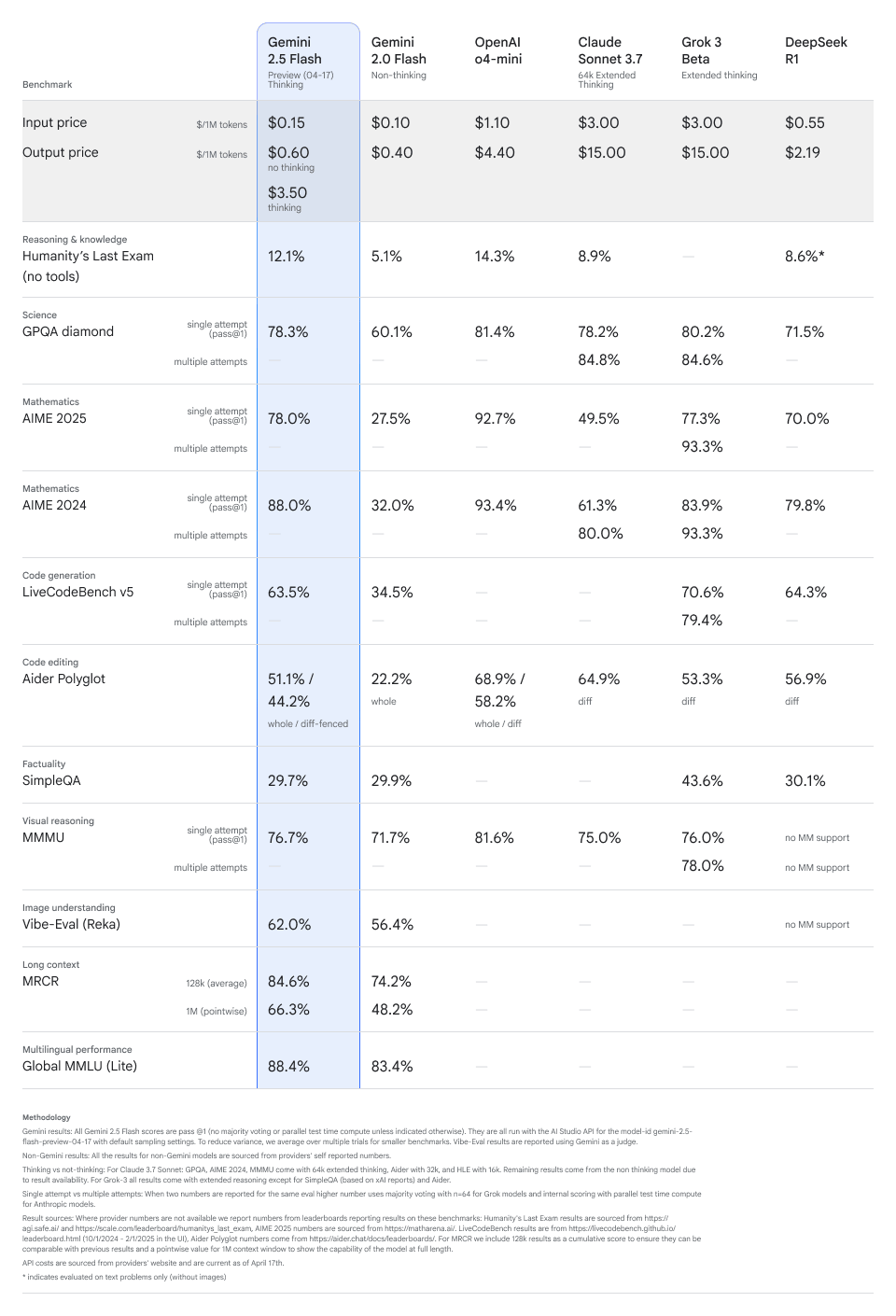
Previously, Google offered model prompt caching, but it required explicit definition by developers of their highest-frequency prompts. While cost savings were promised, the manual effort involved in explicit caching was often significant.
Transition to Implicit Caching
In response to feedback from developers, Google has shifted to implicit caching, which is automatic and enabled by default for Gemini 2.5 models. With implicit caching, if a request to a Gemini 2.5 model matches a previous request, cost savings are automatically applied.
Considerations and Recommendations
In response to feedback from developers, Google has shifted to implicit caching, which is automatic and enabled by default for Gemini 2.5 models. With implicit caching, if a request to a Gemini 2.5 model matches a previous request, cost savings are automatically applied.









