
Extract any Document with Gemini 2.0 | Dec, 2024 - Towards AI
In this article, we’ll explore how Google’s Gemini 2.0 models supercharge Intelligent Document Processing (IDP) when combined with ExtractThinker — an open-source framework designed to orchestrate OCR, classification, document splitting, and data extraction pipelines. We’ll cover how Google Document AI fits in, and the new features of Gemini 2.0 Flash, and we’ll wrap it all up with code examples and pricing insights.
Intelligent Document Processing (IDP)
Intelligent Document Processing (IDP) is a critical workflow for turning unstructured data (like invoices, driver’s licenses, and reports) into structured, actionable information. Although Large Language Models (LLMs) can now directly process images and PDFs, it’s often not enough to simply feed an image into an LLM and hope for perfect results. Instead, a robust IDP pipeline combines:

ExtractThinker is a library that handles these steps out-of-the-box, letting you seamlessly integrate them with the brand-new Gemini 2.0 models from Google.
Google Document AI
Google Document AI is a solution from Google Cloud that provides OCR, structural parsing, classification, and specialized domain extractors (e.g., invoice parsing, W2 forms, bank statements, and more).
Gemini 2.0
Google’s Gemini 2.0 is the next evolution of their multimodal model family, supporting text, images, audio, plus advanced “agentic” features. Within Gemini 2.0, there are multiple variants:
- Gemini 2.0 Flash
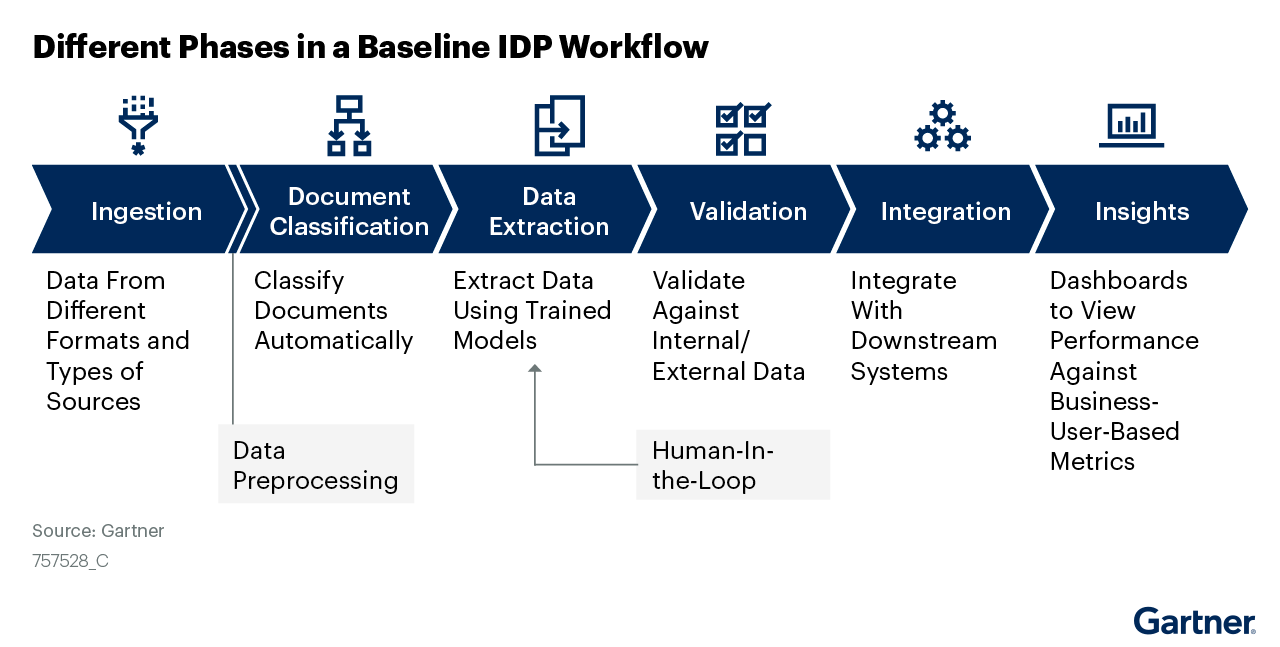
At runtime, EAGER splitting will scan the entire document, detect logical boundaries (based on content differences), and create smaller “sub-documents,” each of which can then be classified and extracted.
You can load a file, split it, and extract it all in one chained call:
To put it all together you need:
Google Document AI also provides a Splitter processor that identifies sub-document boundaries and assigns each segment a confidence score. It outputs structured JSON (entities listing page ranges, classification labels, etc.). However, it has notable constraints — for example, splitting large (over 30 pages) logical documents is unsupported, and the splitter only breaks documents at page boundaries without actually splitting the PDF for you.









