
The Ultimate Guide to Building Your Startup on Google Gemini APIs
If you haven’t logged into LMSys recently - the de facto source for LLM leaderboards thanks to their user-generated blind comparison methodology - you might be surprised to find the 3rd model on the leaderboards is Google Gemini: And, technically, it’s tied for number 2 with Claude-3.5 Sonnet. Google is playing to compete in the LLM market. It went from unranked to 2nd place in less than 6 months. On top of that: maybe you want to build with video? This is where Gemini shines. For example, here’s the difference between GPT-4o, Sonnet-3.5, and Gemini-1.5 Pro in analyzing my most recent YouTube video: GPT-4o just hallucinated, Claude couldn’t do the task, but Gemini could. It’s this combination of power, multimodality, and cost that makes Gemini so interesting for all the AI hackers out there (and if you aren’t one, why not?).
Overview of Gemini Models and Their Pricing
Gemini is Google’s family of natively multimodal Large Language Models (LLMs). They’re trained on TPUs. Here’s Sundar and Demis, the two leaders behind them: These models can see images and videos, hear audio and understand text with a massive 1, sometimes 2, million context window. They come in a few flavors: Gemini Ultra - The largest model for the most complex tasks. This isn’t available in the API, but is what you interact with if you pay for Gemini advanced as a consumer. Gemini Pro - The best model for general-purpose applications across a wide range of tasks. This has a 2 million context window and the one you’ll want to develop on. Gemini Flash - The fastest and most affordable model for most tasks designed for efficiency. This is the one you want to scale up on. Gemini Nano - Extremely quick and primarily used for on-device tasks such as within Chrome or Android. This one has zero cost to the developer.
- The fastest and most affordable model for most tasks designed for efficiency. This is the one you want to scale up on. Gemini Nano - Extremely quick and primarily used for on-device tasks such as within Chrome or Android. This one has zero cost to the developer.
In-Depth Comparison: Gemini vs OpenAI vs Anthropic vs Meta
Let’s compare the price of Gemini models vs similar models in the market:
- Pricing for the most intelligent, advanced models
- Pricing for fast, cost-effective models
As you can see, Gemini Flash is very competitively priced. Before 4o mini’s release, it was the cheapest option in output $ per 1m. Now, 4o mini is a very enticing option. We’ll see what Google does to compete. This space is always changing.
Key Takeaway for Builders
Ultimately, I see the teams at Google and Deepmind working hard on making models which are easy to use for developers and solve hard problems that we didn’t think were possible. — Liam Bolling, PM on Gemini APIs
Every foundational model company is trying to differentiate compared to the pack. Here is how Gemini compares to OpenAI, Anthropic, and Meta right now: The leading benchmark for text LLM performance is MMLU. There, Gemini Flash performs very well. Into GPT-4o mini and LLaMa-3.1 70B released this week, it actually led in this area. And this is just the overall model performance. For developers, that’s not exactly what’s relevant. When you train two models with RAG and other fine-tuning, those adjustments can matter quite a bit. So of two similarly performing models, it can make sense to try both. Multi-modal performance is an area that we saw from the introduction, Gemini models do well on (especially video). This is clear in the data. Meta didn’t even release MMMU benchmarks for LLaMa-3.1. It’s an area Google has invested in from the beginning and is one of the most compelling reasons to build on Gemini instead of an alternative. The next area that may or may not be important for your app, but generally is if you want to create ‘AI agentic’ behavior, is code performance. This is the area where Gemini Flash currently underperforms its competition. So the model may not be a fit for you. GPT-4o mini has substantially better CODE scores than the rest. The Gemini API is generally priced competitive against comparable models, and we can expect Google’s leadership to continue to price that way. Gemini also offers a less known feature that stands out from the crowd; Context Caching. If you’re using the same system instruction or prompt repeatedly, Google will cache those tokens and give you a massive +75% discount.
The next area that may or may not be important for your app, but generally is if you want to create ‘AI agentic’ behavior, is code performance. This is the area where Gemini Flash currently underperforms its competition. So the model may not be a fit for you. GPT-4o mini has substantially better CODE scores than the rest. The Gemini API is generally priced competitive against comparable models, and we can expect Google’s leadership to continue to price that way. Gemini also offers a less known feature that stands out from the crowd; Context Caching. If you’re using the same system instruction or prompt repeatedly, Google will cache those tokens and give you a massive +75% discount.
Example: Non-cached tokens per 1 million cost $0.35 on Gemini Flash With Context caching, it costs $0.0875 per 1 million on Flash That’s a 75% reduction in price, and one of the most exciting uses to choose Gemini.
For the truly nerdy out there, each of these 4 models has a different architecture as well: Gemini: Uses a mixture-of-experts (MoE) architecture, allowing for efficient scaling. It's trained on TPUs, which are optimized for tensor operations. GPT-4o : Uses a dense transformer architecture. OpenAI hasn't disclosed many details about its specific implementation. Claude (Anthropic): Uses constitutional AI training, which involves training the model to follow specific rules and behaviors. LLaMA (Meta): Uses a standard transformer architecture but with optimizations for efficiency, allowing it to achieve strong performance with fewer parameters. While Gemini shows impressive gains, each model has its strengths. Developers should benchmark against their specific use cases—AI Developer at Apollo.io Aakash worked withGemini is being leveraged by enterprise companies across a variety of industries and use cases: Walmart uses Gemini to make changes to their millions of product listing pages. Gemini acts as the tool to improve their product listing pages at scale. Shoppers on Victoria’s Secret can upload photos of their fit and Gemini will create recommendations of other products they should buy. Goldman Sachs uses Gemini to increase their developer efficiency by 40% by generating test cases, complete functions, and generating new code based on a prompt. Wayfair uses Gemini to make coding faster for their engineering by writing entire functions.
: Uses a dense transformer architecture. OpenAI hasn't disclosed many details about its specific implementation. Claude (Anthropic): Uses constitutional AI training, which involves training the model to follow specific rules and behaviors. LLaMA (Meta): Uses a standard transformer architecture but with optimizations for efficiency, allowing it to achieve strong performance with fewer parameters. While Gemini shows impressive gains, each model has its strengths. Developers should benchmark against their specific use cases—AI Developer at Apollo.io Aakash worked withGemini is being leveraged by enterprise companies across a variety of industries and use cases: Walmart uses Gemini to make changes to their millions of product listing pages. Gemini acts as the tool to improve their product listing pages at scale. Shoppers on Victoria’s Secret can upload photos of their fit and Gemini will create recommendations of other products they should buy. Goldman Sachs uses Gemini to increase their developer efficiency by 40% by generating test cases, complete functions, and generating new code based on a prompt. Wayfair uses Gemini to make coding faster for their engineering by writing entire functions.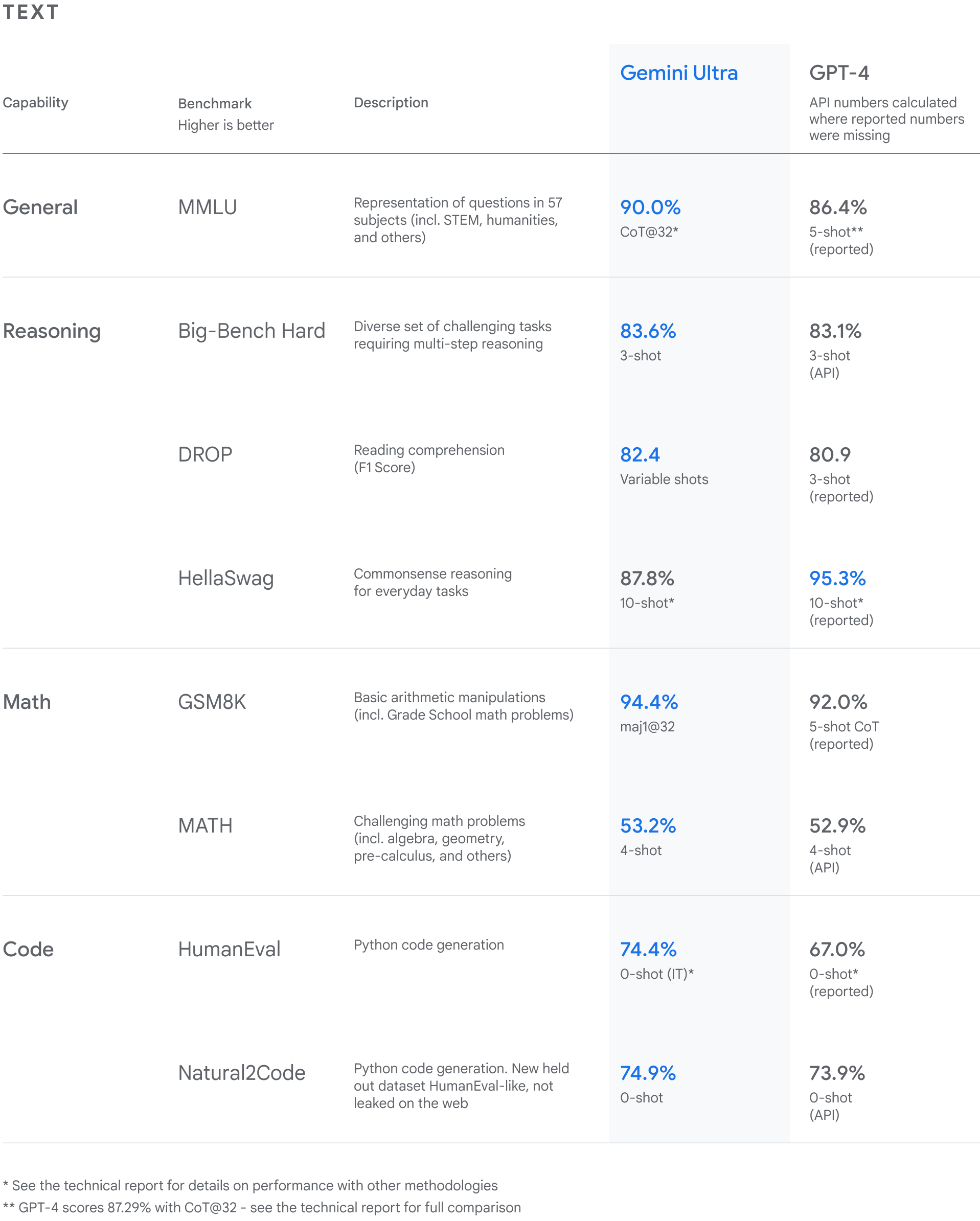 Six Flags uses Gemini to chat with customers answering 30% of guest questions. Uber uses Gemini to increase the throughput of human customer support agents by summarizing documents and suggesting next steps. Patreon uses Gemini to summarize unread messages in your messages inbox.
Six Flags uses Gemini to chat with customers answering 30% of guest questions. Uber uses Gemini to increase the throughput of human customer support agents by summarizing documents and suggesting next steps. Patreon uses Gemini to summarize unread messages in your messages inbox.
So that should give you an idea of what Gemini’s models are capable of. Now read on for all the technical setup and product guidance you need to get started…









