
Mapping the Mind of a Large Language Model - Grapevine
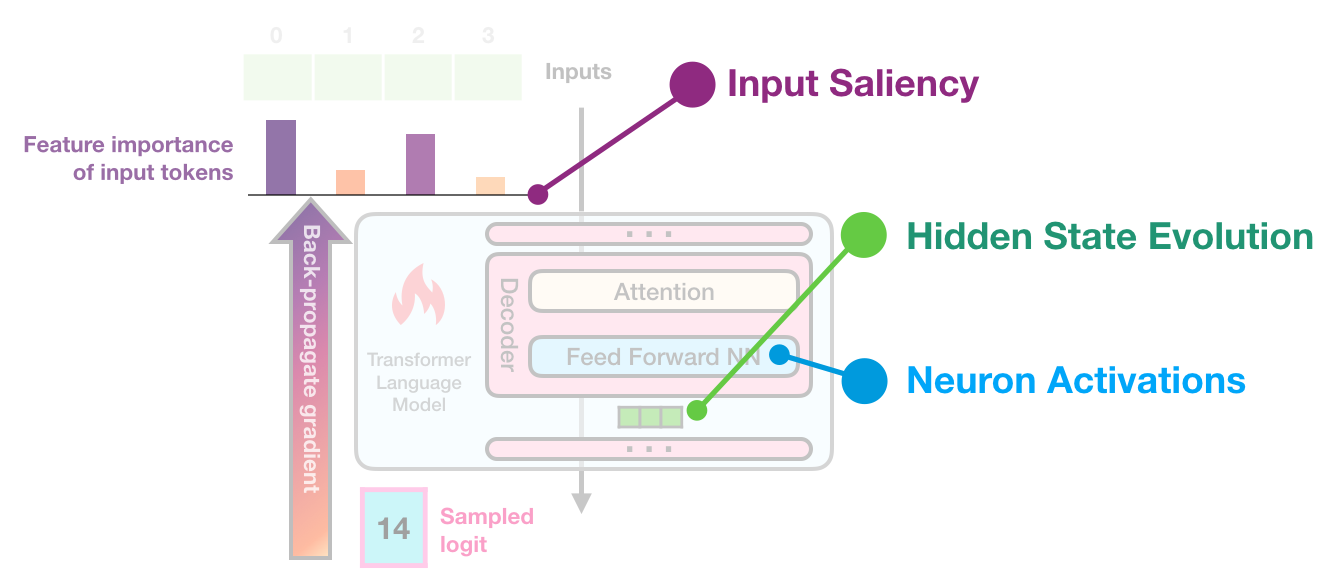
Recently, Anthropic released a groundbreaking paper titled "Scaling Monosemanticity" which delves into the inner workings of Claude 3 Sonnet, their mid-sized production model. The researchers utilized sparse autoencoders (SAEs) to decode the activities within the model, revealing millions of interpretable features that have logical meaning to humans.
The Coolest Findings
One of the most fascinating discoveries was the ability to extract millions of interpretable features from Claude 3 Sonnet using sparse autoencoders. These features ranged from identifying code bugs to uncovering traits related to deception and self-representation.

Significance for AI Safety
This advancement holds significant implications for AI safety. While it provides valuable insights into the functioning of these models, it also raises concerns about the vast amount of knowledge, including potentially risky information, embedded within them.
Limitations to Consider
Despite the excitement surrounding this breakthrough, it is crucial to acknowledge the limitations inherent in the research findings.
Personal Perspective
From a personal standpoint, this development represents a major stride towards truly comprehending the operations of language models. It signifies a shift from mere speculation to actual visualization of the concepts employed by the model. However, the realization of the extent of sensitive information contained within these models also evokes a sense of unease.
For more information, you can read the full paper here.
As we delve deeper into the capabilities of these large language models, the implications for AI safety become both exciting and daunting. The journey towards understanding and harnessing their potential continues to unfold, paving the way for a future where the landscape of technology and development may undergo significant transformations.









