
What are transformers in AI? | ITPro
Transformer models are driving a revolution in AI, powering advanced applications in natural language processing, image recognition, and more.
The Rise of Transformer Models in AI
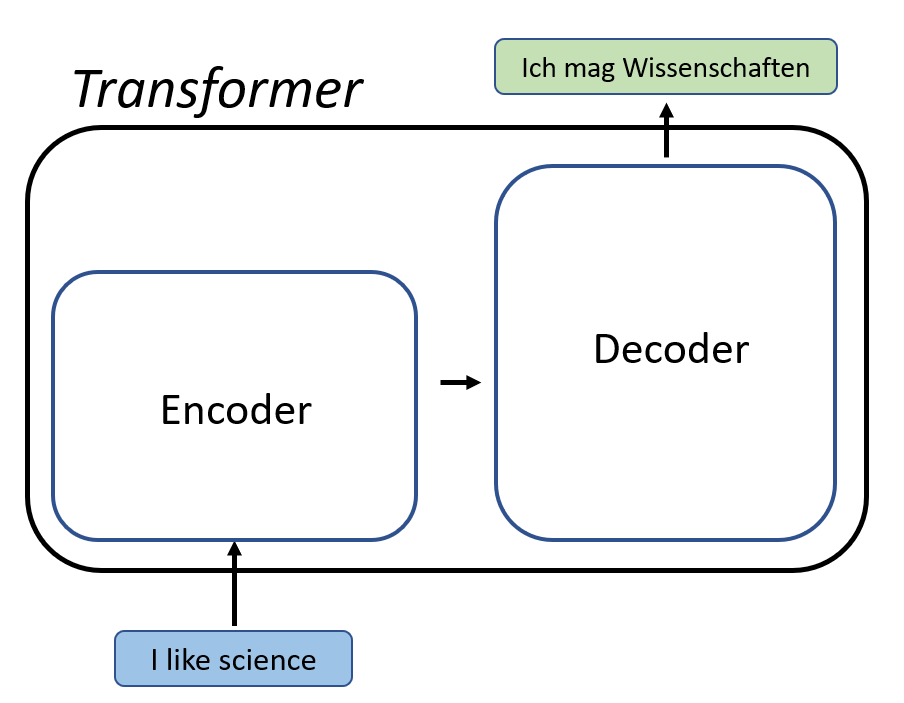
AI has revolutionized numerous industries, and the AI transformer model is at the core of many groundbreaking advancements. Initially introduced in 2017 by researchers at Google in their paper Attention Is All You Need, this model architecture has become foundational for large language models (LLMs) and other generative AI systems. From natural language processing (NLP) to image recognition and even music generation, transformer models have emerged as an essential part of deep learning.
Understanding Transformer Models
A transformer model is a neural network architecture primarily designed to process sequential data, such as text or speech. Unlike earlier neural networks like recurrent neural networks (RNNs), which handle data step-by-step, transformers process entire sequences of data simultaneously. This parallel processing allows them to handle larger datasets more efficiently and enables faster training and inference.
The Core Components of Transformer Models
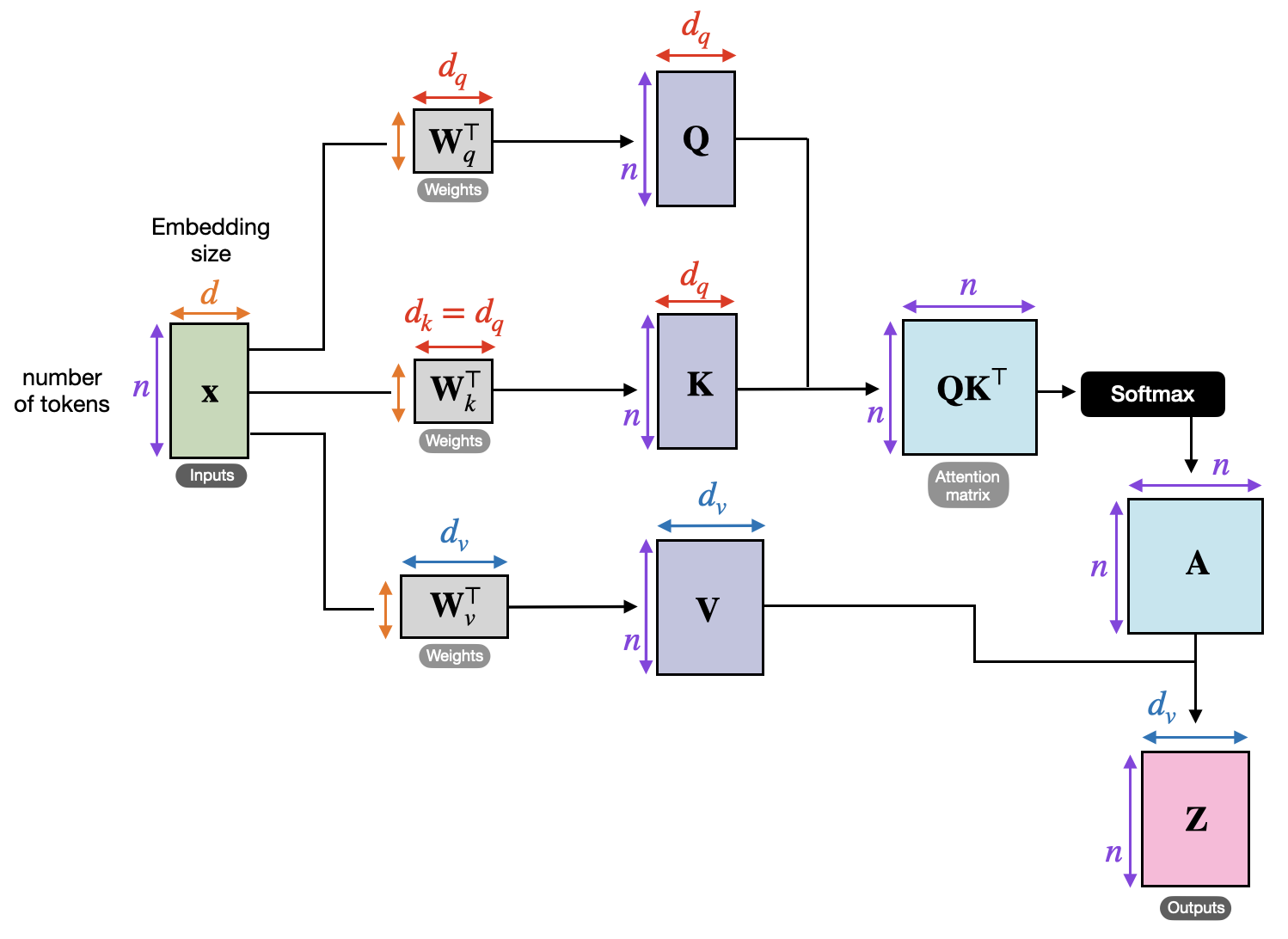
At a high level, transformer models are composed of layers that process input data in stages. Each layer has two core components: the attention mechanism (or self-attention) and a feed-forward neural network.
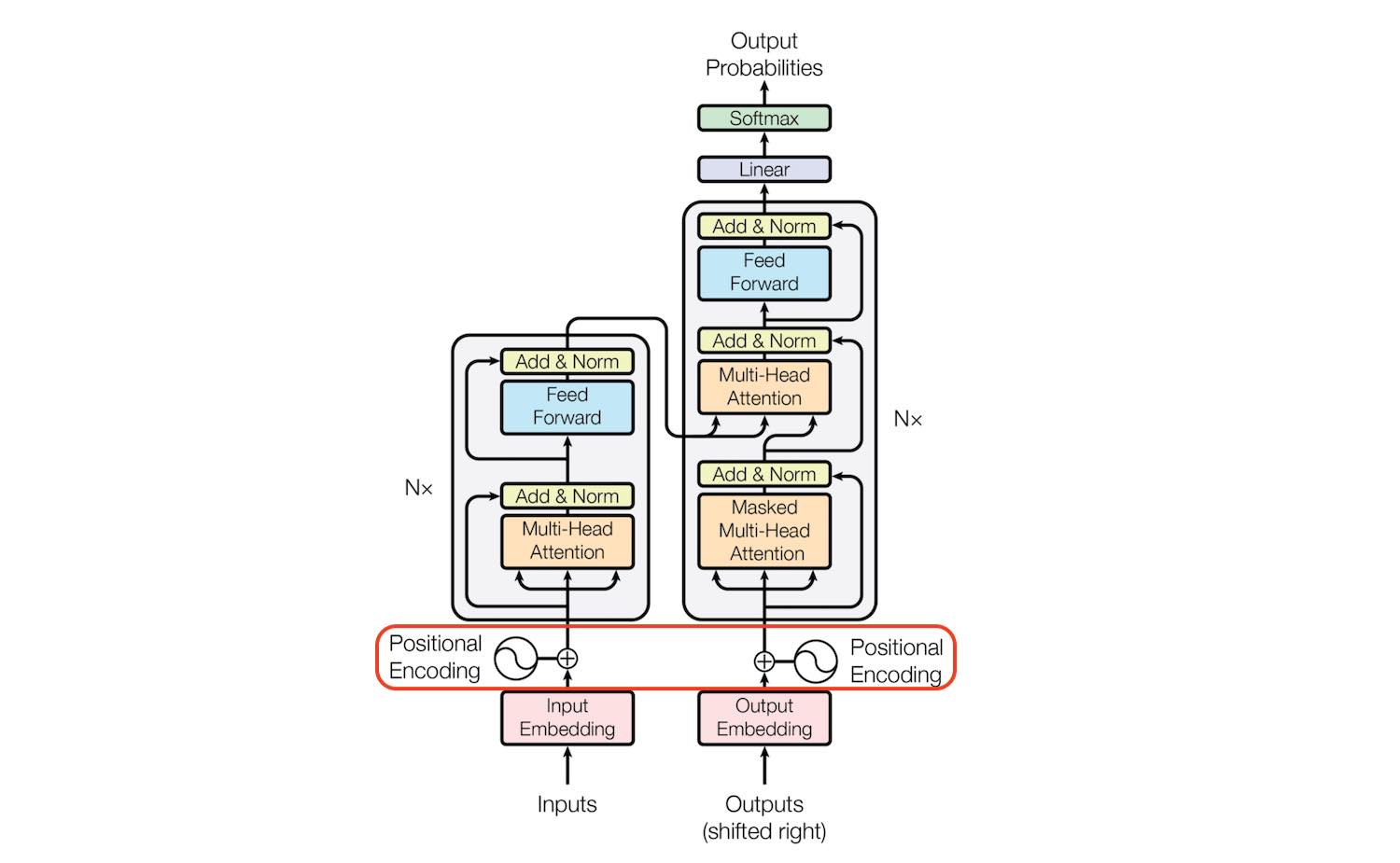
While transformers process data in parallel, they still need a way to recognize the order of the input sequence. This is where positional encoding comes into play. By adding a unique encoding to each position in the sequence, transformers maintain the order of the data, ensuring that they understand the relationships between elements such as individual words based on their positions.
After the attention mechanism has processed the input, the data is passed through a feed-forward neural network, refining the information further. This process is repeated across multiple layers, with the model learning more complex data representations at each stage.
Challenges and Future Developments
While transformer models have achieved remarkable success, research is ongoing into new architectures that may surpass transformers in the future. One area of focus is improving transformer efficiency, particularly for tasks that require massive computational power. Some researchers are exploring hybrid models that combine the strengths of transformers with other architectures, while others are looking into entirely new models that may push the boundaries of what is possible in AI.
Notable Transformer-Based AI Models
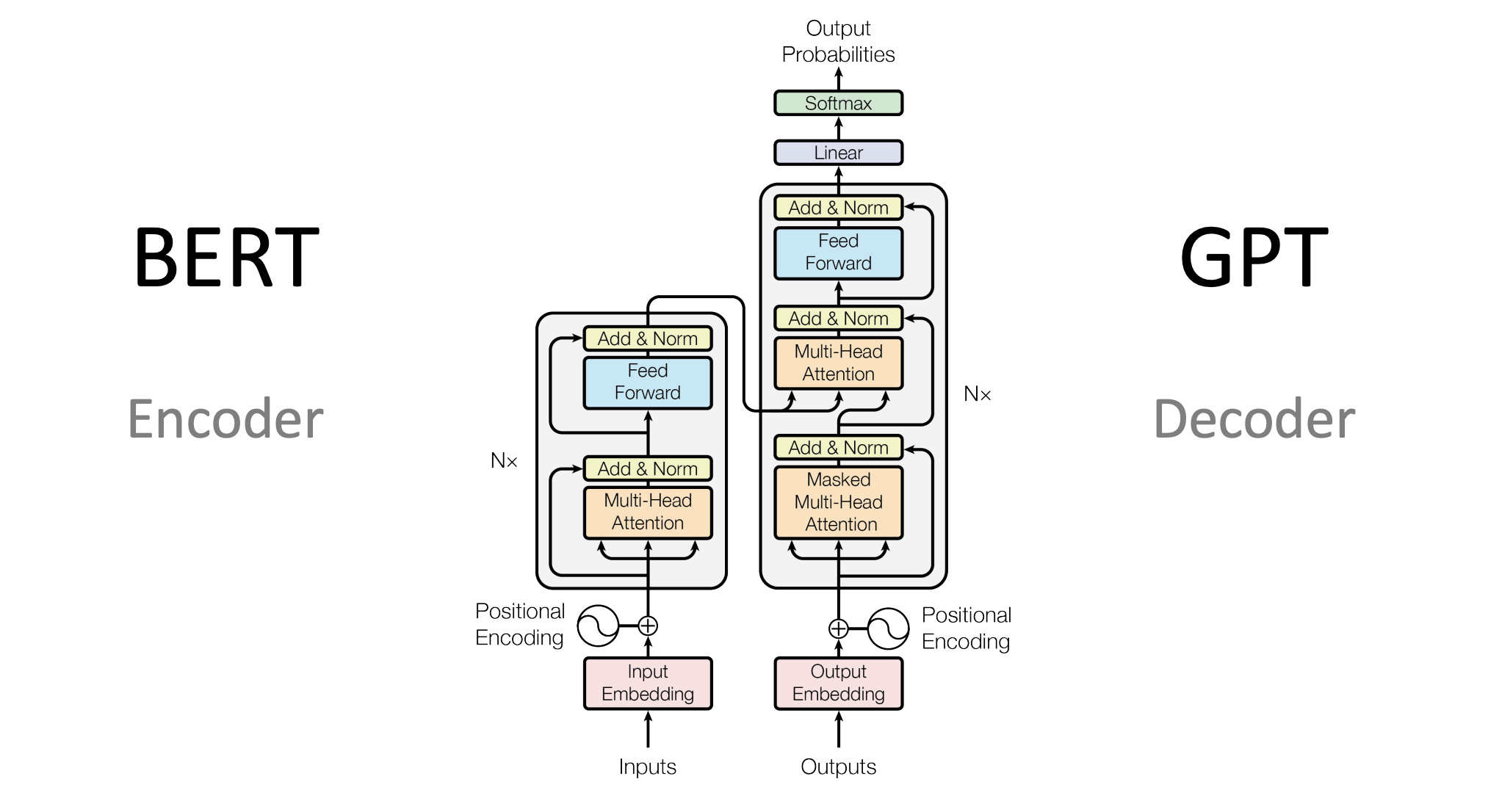
Transformers have become the foundation for many of today's most advanced AI models. Examples include OpenAI's GPT models, Google's BERT, and T5. These models have been instrumental in tasks like language translation, content creation, and search result ranking.
While transformers were initially developed for NLP tasks, their success has also extended to computer vision and other domains, showcasing their versatility and potential for driving further AI advancements.









