
Demystifying DeepSeek | Thoughtworks Ecuador
On January 10, 2025, DeepSeek launched an LLM, R1, that the startup claimed is on par with Open AI’s ChatGPT o1 for reasoning tasks. The app topped the App Store charts in record time, capturing the imagination of not just the tech industry but the wider world too. One claim was particularly startling: that the model had been trained for under $6m (as opposed to the $100m spent on GPT-4 by OpenAI). This created waves in the stock market and the news media.
A Closer Look at DeepSeek
Founded in May 2023, DeepSeek is a Chinese AI startup based in Hangzhou and Beijing. It’s backed by the Chinese Hedgefund High-Flyer located in Hangzhou. Both High-Flyer and DeepSeek were founded by Liang Wenfeng.
DeepSeek built two types of models and apps to use them. The latest versions of the two types of models are V3 and R1. V3, as the name suggests, is version 3 of a general purpose language model and R1 is a reasoning model on top of V3-Base. They also provide distilled versions of their models so they can fit on your laptop.
Analysis of DeepSeek
A few of us at Thoughtworks used DeepSeek via the company’s website, while others used ollama to get an R1 distilled model running on their laptop. We then spent some time using the model as you would other models — for tasks ranging from coding to reasoning questions.
Based on our experience in recent days, here are some of our initial impressions and thoughts:
- Multilingual performance showed good results in English and Mandarin but was less smooth in French, with unintended Chinese or Arabic characters appearing and occasional reversion to English during complex reasoning.
- Its reasoning style can be overly verbose — sometimes it went in circles when we were using it.
- We’d like to learn more about how DeepSeek is thinking about security and privacy aspects — particularly from a user perspective.
DeepSeek's Model Details
Cloud Service Providers have also jumped on this. You can deploy DeepSeek models on GCP Vertex AI, AWS Bedrock and Azure AI Foundry.

DeepSeek’s models are certainly intriguing enough to consider adding to your AI platform’s toolbox along with other open-weight models, as application builders will want to experiment with or use different models for different purposes.
DeepSeek’s results have not yet been reproduced. We are closely following Huggingface’s attempt to reproduce it at openR1.
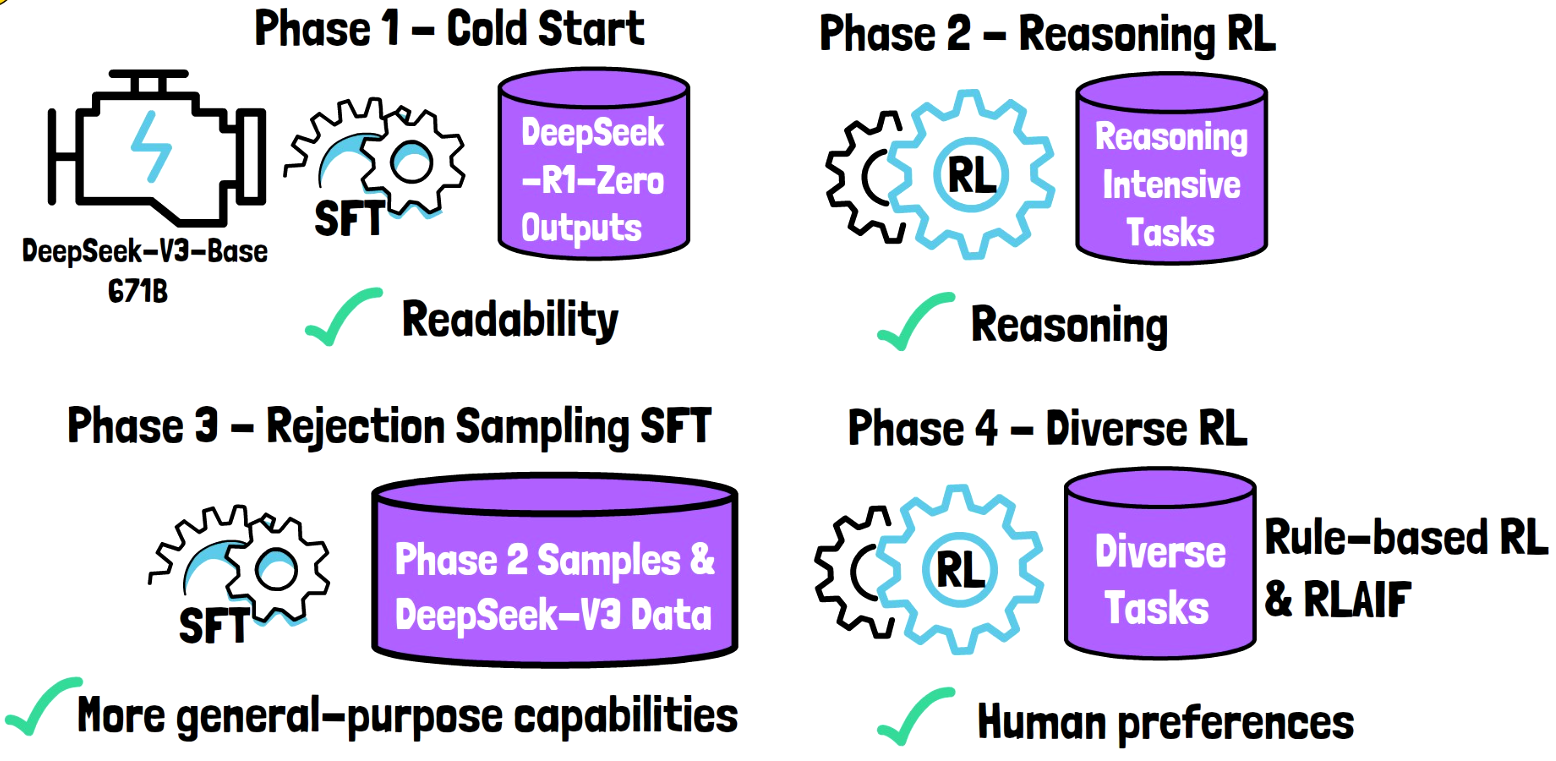
Training and Techniques
R1 was trained using a combination of SFT and RL on V3-Base. They’re transformers that have been highly optimized for specific hardware/software frameworks based on the limitations imposed by the environment. DeepSeek has also used a combination of new and old techniques in some interesting ways.
V3-Base uses a strong mixture-of-experts approach. This is similar to Mixtral but more efficient.
R1 was built on V3-Base using supervised fine-tuning (SFT) as well as reinforcement learning (RL) to build reasoning into the model.
Conclusion
DeepSeek’s models have brought a new perspective to the AI landscape, and their innovative approach to training and reasoning models is worth exploring further. As the technology evolves, it will be interesting to see how DeepSeek continues to push the boundaries of AI development.



















