Announcing the General Availability of GPT-4 Turbo with Vision on Azure OpenAI Service
We are thrilled to announce the general availability (GA) of GPT-4 Turbo with Vision on the Azure OpenAI Service. The GA model, gpt-4-turbo-2024-04-09, is a multimodal model that can process both text and image inputs to generate text outputs. This model replaces the preview models that were previously available.
Our customers and partners have been leveraging GPT-4 Turbo with Vision to revolutionize their processes, improve efficiencies, and drive innovation within their organizations. Use cases vary from retailers enhancing the online shopping experience to media and entertainment companies enriching digital asset management, and various organizations gaining insights from charts and diagrams. Detailed case studies highlighting these applications will be presented at the upcoming Build conference.
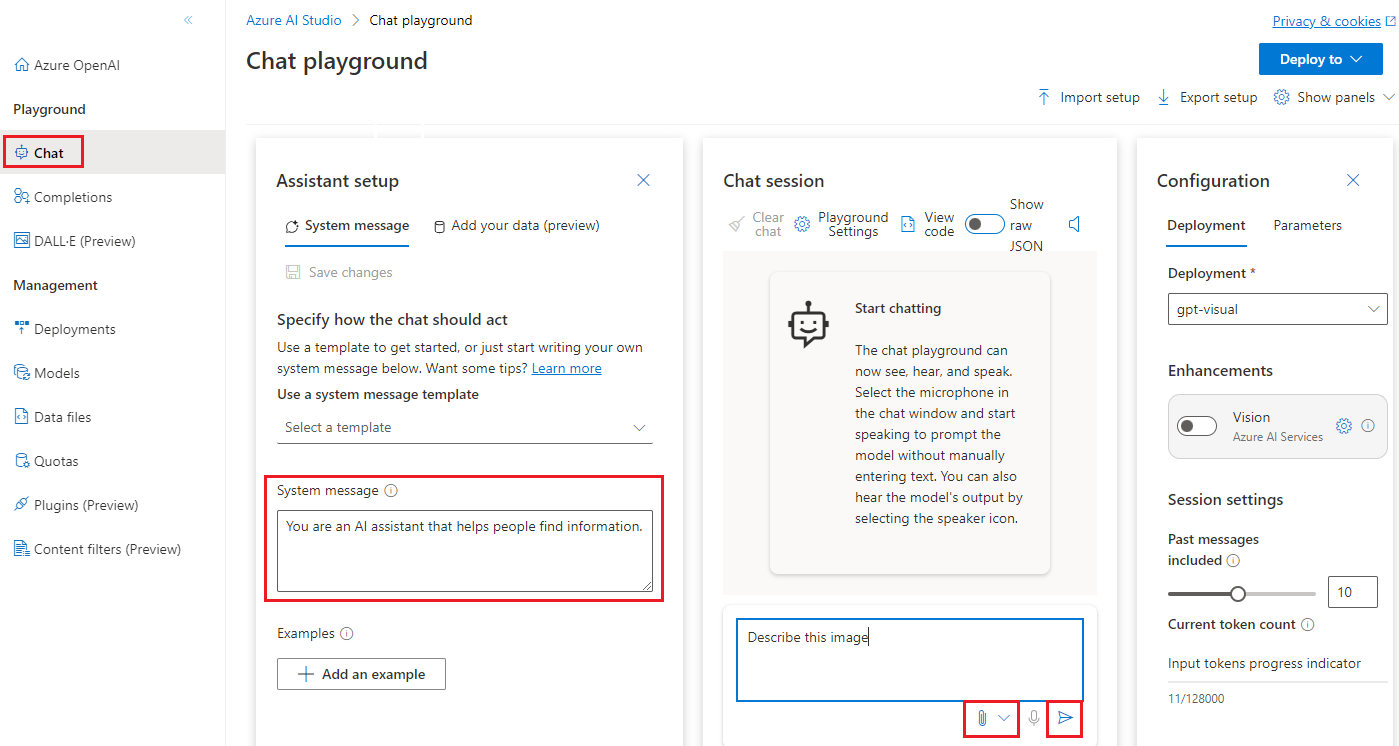
Existing Azure OpenAI Service customers can now deploy gpt-4-turbo-2024-04-09 in Sweden Central and East US 2. For more information, please visit our model availability page. To deploy this GA model from the Studio UI, choose "GPT-4" and then select the "turbo-2024-04-09" version from the dropdown menu. The default quota for the gpt-4-turbo-2024-04-09 model will remain the same as the current quota for GPT-4-Turbo. Refer to the regional quota limits for more information.
Upgrades for Preview Models

We are focusing on upgrading deployments that utilize any of the three preview models (gpt-4-1106-preview, gpt-4-0125-preview, and gpt-4-vision-preview) and are set for auto-update on the Azure OpenAI Service. These deployments will be transitioned to gpt-4-turbo-2024-04-09 starting on June 10th or later. Customers with these preview deployments will be notified at least two weeks before the upgrades commence. A detailed upgrade schedule outlining the regions and model versions' order for the upgrades will be made available in our public documentation.
Enhancements and Future Offerings
JSON mode and function calling for inference requests involving image (vision) inputs will be rolled out in GA in the upcoming weeks. It is important to note that text-based inputs will continue to support both JSON mode and function calling. However, enhancements like Optical Character Recognition (OCR), object grounding, video prompts, and other features integrated with the gpt-4-vision-preview model will not be included in the GA model. We are committed to enhancing our products to deliver value to our customers and are actively exploring ways to incorporate these features into future offerings.