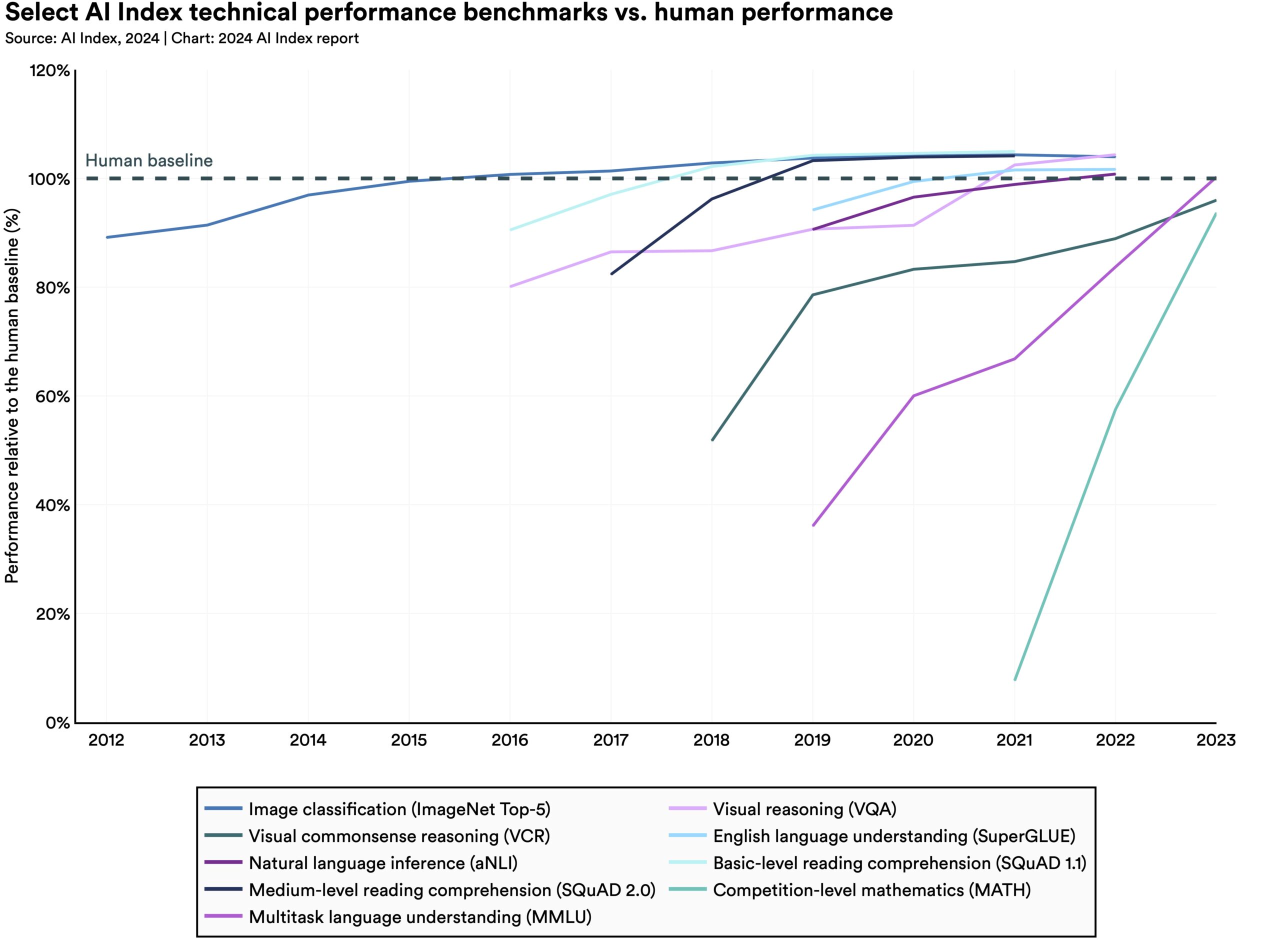
Training AI at a Fraction of the Cost
Last week, the tech world was amazed by the unveiling of DeepSeek R1, an open-source reasoning AI that rivaled ChatGPT o1 at a significantly lower cost. This breakthrough showcased how innovative software and hardware combinations could democratize the creation of powerful AI models. While initial reactions suggested a shift away from high-end hardware, further investigation revealed a different story.
The DeepSeek Controversy
Following the release of DeepSeek R1, suspicions arose regarding the origin of its capabilities. It was speculated that DeepSeek may have used outputs from ChatGPT to train its AI, prompting accusations from OpenAI. These allegations hinted at DeepSeek potentially leveraging established competitor AIs to minimize development costs, causing fluctuations in the stock market that were later corrected.
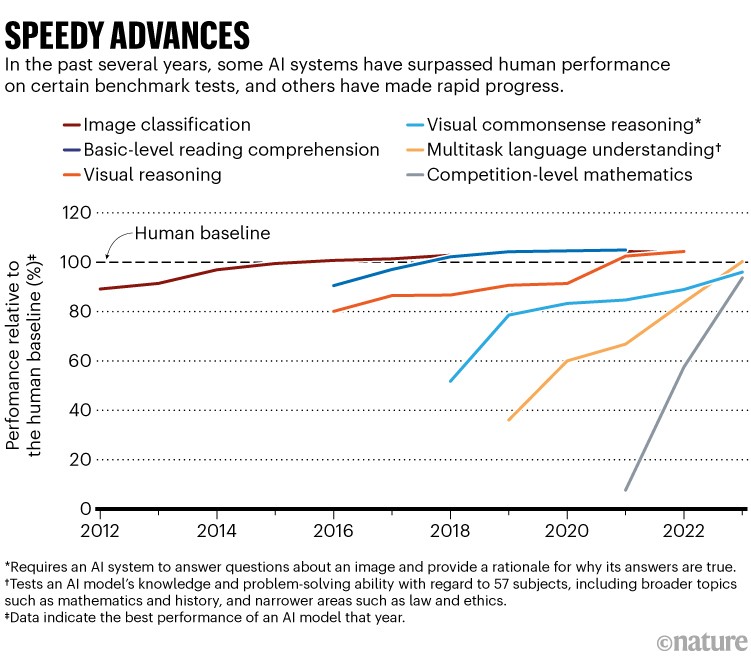
The Rise of S1
Amidst the DeepSeek saga, researchers from Stanford and the University of Washington conducted a groundbreaking experiment. They trained a reasoning AI named S1 to match the performance of ChatGPT o1, all with a mere $50 in compute costs. Drawing inspiration from DeepSeek's approach, the team utilized a version of Gemini and an open-source AI from China in their innovative training process.
The DeepSeek Controversy
Following the release of DeepSeek R1, suspicions arose regarding the origin of its capabilities. It was speculated that DeepSeek may have used outputs from ChatGPT to train its AI, prompting accusations from OpenAI. These allegations hinted at DeepSeek potentially leveraging established competitor AIs to minimize development costs, causing fluctuations in the stock market that were later corrected.
Cost-Efficient AI Development
The swift and cost-effective training of S1 highlights a new paradigm in AI development. By strategically leveraging existing technologies and refining them through innovative methods, researchers are demonstrating that high-end AIs can be trained efficiently without exorbitant costs. The introduction of techniques like allocating additional compute resources and implementing "wait" tokens further enhance the model's performance while keeping expenses minimal.
Implications for the Future
While not as headline-grabbing as DeepSeek R1, the S1 project signifies a significant breakthrough in affordable AI development. This opens doors for a new generation of powerful AI models that rival industry giants without the accompanying hefty price tags. Although the cost-efficiency of models like S1 may be misleading due to their foundational distillation, the impact on the AI landscape is undeniable.

It is crucial to acknowledge that advancements like S1 should not deter major AI firms from substantial investments in compute resources. High-end hardware remains pivotal in shaping the future of AI towards Artificial General Intelligence (AGI). While industry leaders push the boundaries with multi-million dollar projects, smaller teams like the S1 researchers continue to refine and innovate on existing models, catering to specific use cases.
Accessing the S1 Model
The S1 model is available for exploration on GitHub. For further insights, you can refer to the research paper detailing the S1 project.