
Understanding Large Language Models: From Open Source to ...
Can Machines Understand Language? We chat with virtual assistants, ask our phones questions, and get quick translations, language processing by computers has become a daily occurrence. But have we reached the level where machines can fully understand what we say?
This topic has become entirely new with the introduction of Large Language Models (LLMs), a game-changing development in Natural Language Processing (NLP). These complex AI models are pushing the limits of what robots can achieve with language, but can they understand the complexity and the details of human communication? To answer these questions, first, we should understand how LLMs learn.
Training and Architecture
Language models are very important for tasks like generating different types of content and making human-like dialogues, as seen in today’s AI systems. These models are trained using a range of text and code sources like web data from Common Crawl and publications by Project Gutenberg after which the information is carefully cleaned to keep only the required information which is also devoid of any unwanted or unnecessary characters. It’s like a picky eater choosing just the best stuff from the buffet.
To make sure the language model is fed only high-quality material, methods including removing duplication, filtering out low-quality information, and cleaning private data are used. If the text is hateful, prejudiced, or nonsensical then it gets deleted from the LLM so all that remains is an improved data-set.
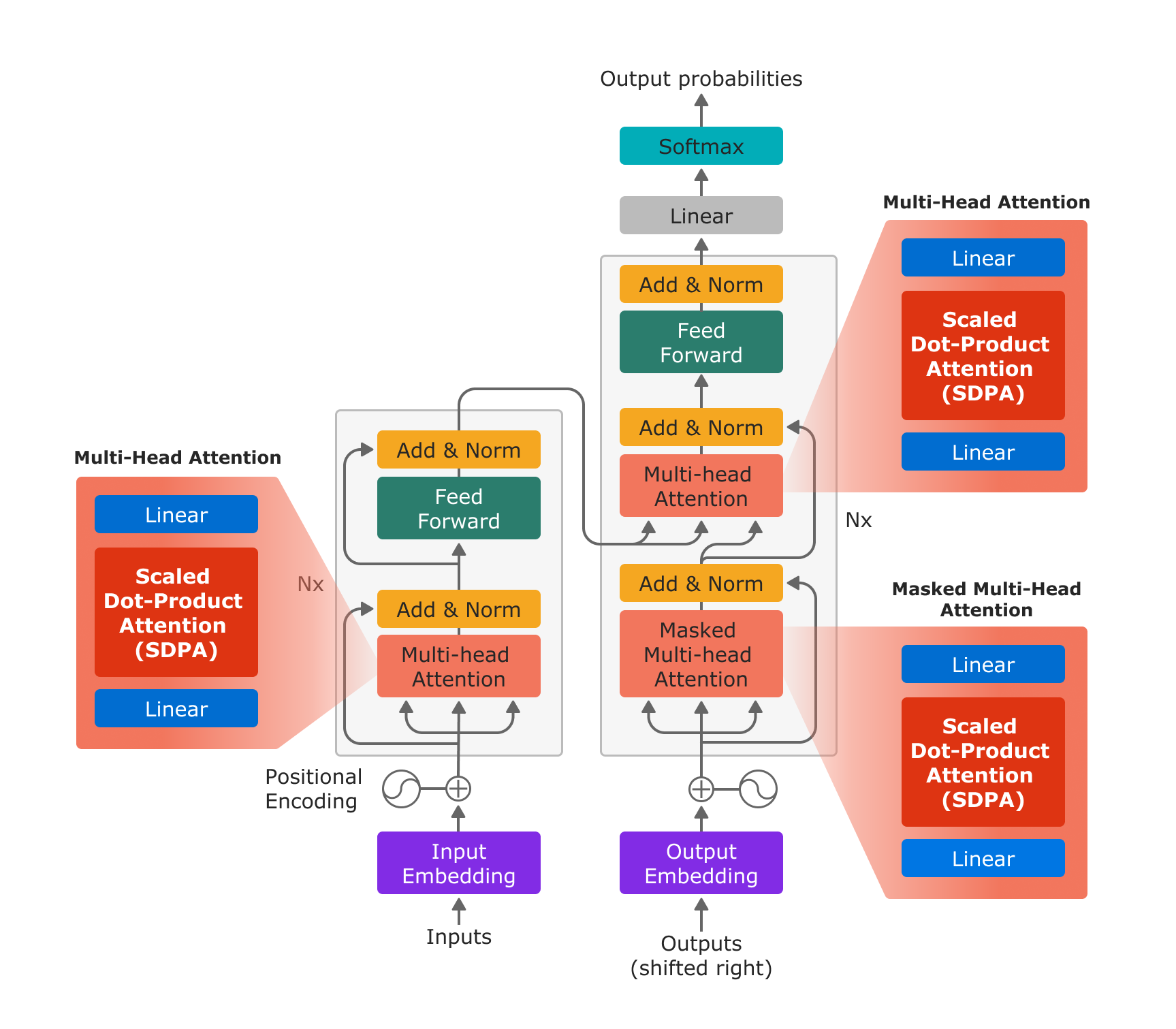
For natural language processing algorithms to compute an accurate score for complexity, such criteria as readability are not usually measured in practice. Next comes the architecture. Transformers, with their encoder-decoder structure, are the most common LLM architecture.
Imagine a language expert analyzing an unfamiliar language. That’s what the encoder in a transformer architecture does — it breaks down the data into its fundamental elements, similar to how a language expert analyzes the grammar and vocabulary of a new language. Afterwards, it sends the understanding to the decoder, which is an imaginative interpreter combining these elements to produce original text, similar to the way a language expert constructs a single sentence in a foreign language.
Open Source vs. Closed Source LLMs
The world of large language models (LLMs) is transforming different industries. These models are changing the game by producing diverse types of text and translating languages smoothly and continuously. Unfortunately, access to these advanced tools has been limited due to proprietary restrictions.
For standardization of AI, Open-source LLMs have taken the lead such as LLaMA, and BLOOM in this area. Their code and training data are openly accessible which enhances transparency as well as availing themselves for scrutiny by developers across the globe. Since the inception of this approach, it has been significant in fostering creativity and innovation in numerous ways.
First, when AI models become open-source, researchers and hobbyists can closely scrutinize their functioning to comprehend better how they produce outputs. Consequently, it is easier to notice any prejudices in the training dataset or algorithms thus leading towards fair and all-embracing Artificial Intelligence advances.
Furthermore, these types of models are not proprietary so that makes it possible for people to customize them for specific purposes. This flexibility enables a wider range of applications, from specialized industry uses to creative personal projects. Open-Source Language Models that are continuously enhanced can make things fair in a way and make it possible to access artificial intelligence for each person`s use.
Challenges and Solutions
Creating intelligent machines such as LLMs is a hard thing to do. It comes with a large price tag. The data dilemma is a huge issue.
To construct these mannerly models, one needs a lot of data which at times goes beyond terabytes or exabytes. Such data should be properly organized, cleaned, and labelled — this might be very expensive and extremely time-consuming. Additionally, storing and handling such enormous amounts of data can be financially difficult.
Another challenge is the Computational Power needed. Training LLMs demands a huge amount of computational power. To train the model, specialized hardware such as GPUs and TPUs are required, and it may take days, weeks, or even months.
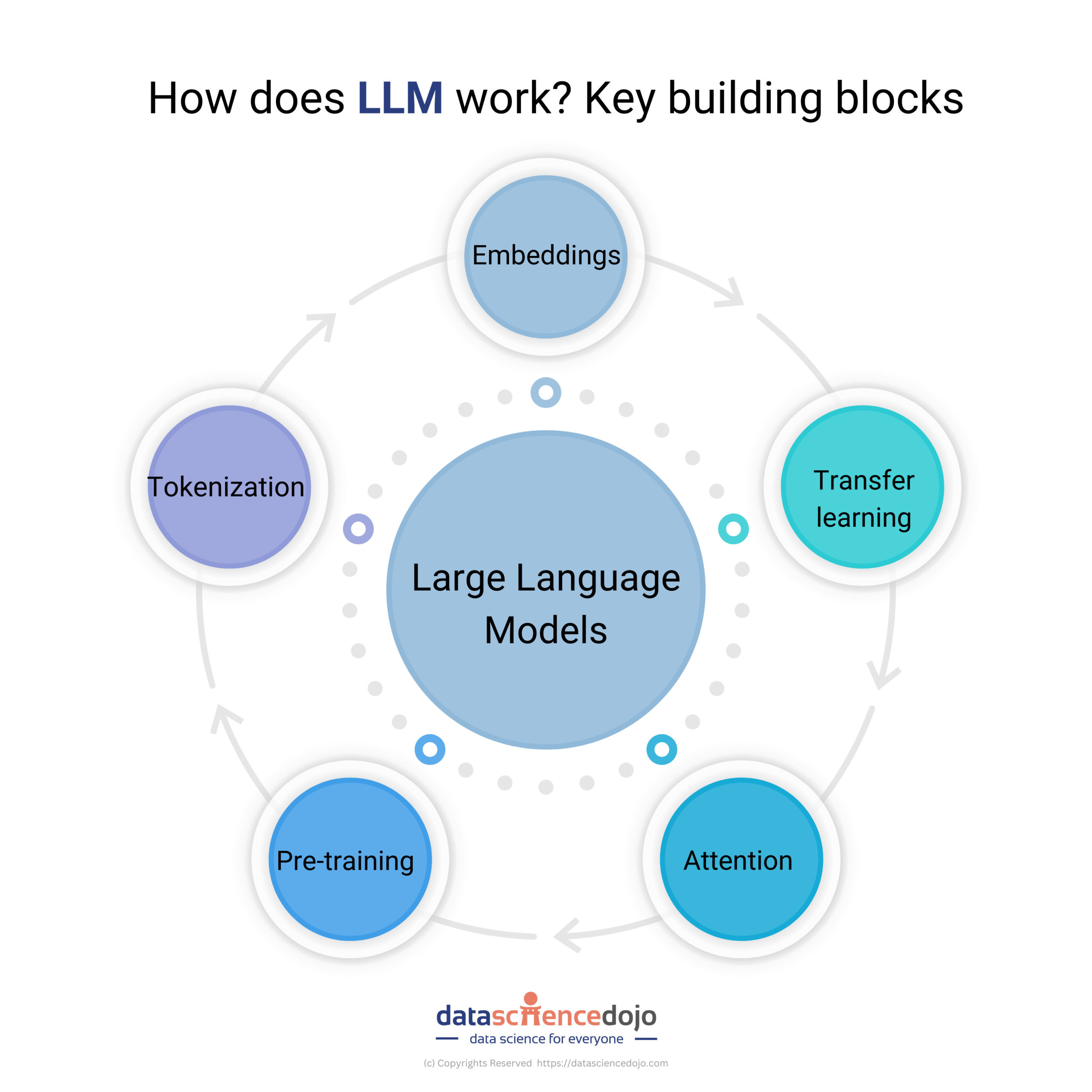
The amount of electricity needed to power these systems adds another layer of cost. These challenges highlight the need for efficient training methods and more readily available resources to make LLMs more accessible.
The phenomenal text-generating capacity of large language models (LLMs) has recently become a trend in the media. To grasp them, we have to cut through the buzz and focus on substantive evaluation methodologies. Understanding the success of LLMs begins with understanding their fundamentals.









