Everything You Need to Know About RAG Pipelines for Smarter AI ...
Introduction
AI technology has advanced significantly, but even the most sophisticated large language models (LLMs) have limitations. Retrieval Augmented Generation (RAG) pipelines offer a solution to build more reliable AI systems by combining retrieval and generation techniques. This helps AI models fetch relevant and up-to-date information from external sources, enhancing their outputs. RAG pipelines are essential for developing intelligent AI applications like chatbots that can answer real-time queries and improve decision-making.
RAG Pipelines Overview
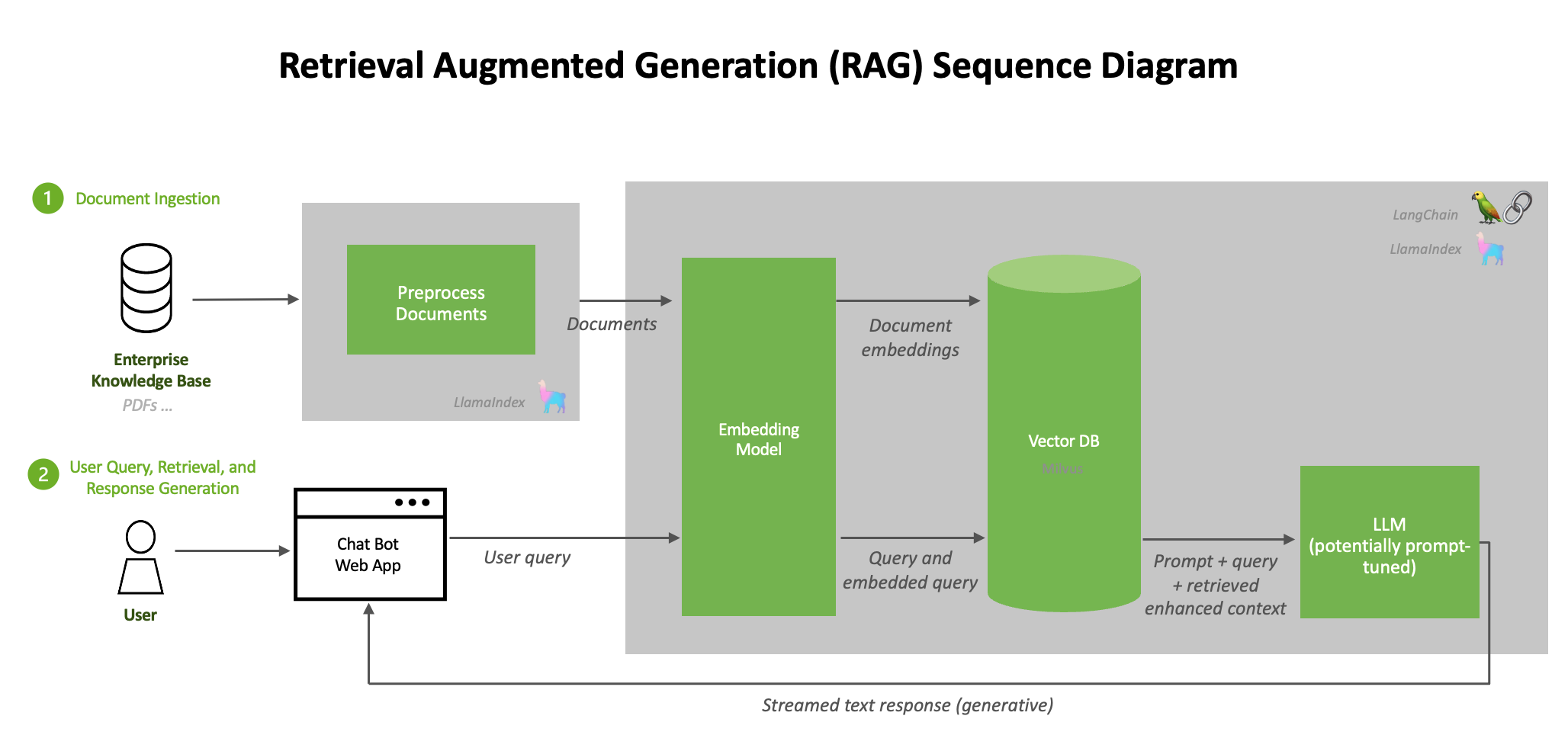
RAG pipelines integrate information retrieval with language generation to create adaptable AI systems. Unlike traditional LLMs that rely solely on pretraining, RAG pipelines enhance generative capabilities by incorporating real-time data from external sources.
Comparison with Other Methods
Aside from RAG, there are other techniques to enhance LLM outputs. Fine-tuning involves retraining LLM parameters with curated data for specific tasks, while semantic search retrieves relevant information based on contextual meaning. However, RAG excels by using retrieved data to generate informative outputs.
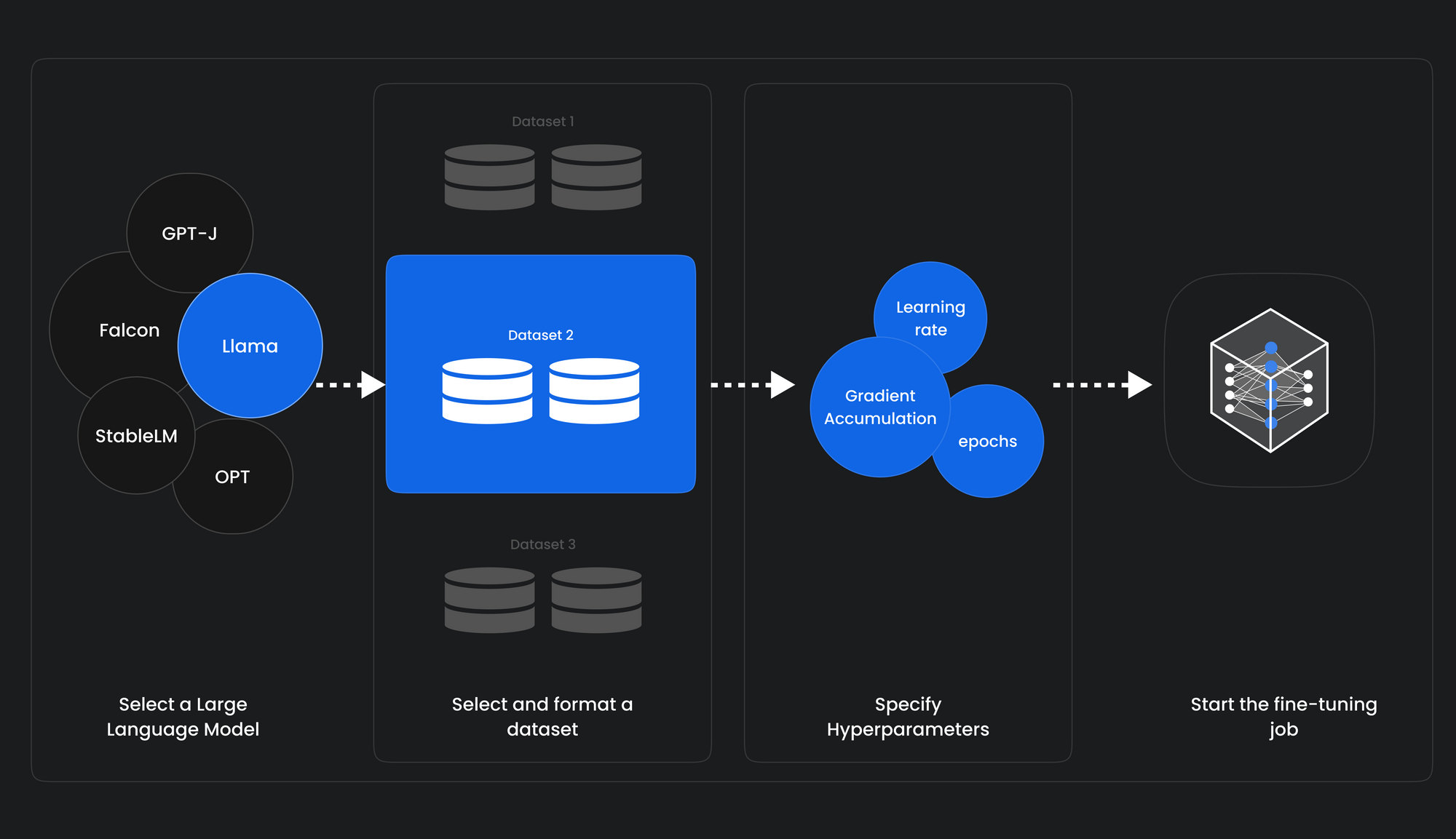
Key Components of RAG Pipelines
RAG pipelines consist of two main stages: information retrieval and generation. The information retrieval phase sources relevant data from external sources, while the generation phase uses this data to create contextually aligned responses.
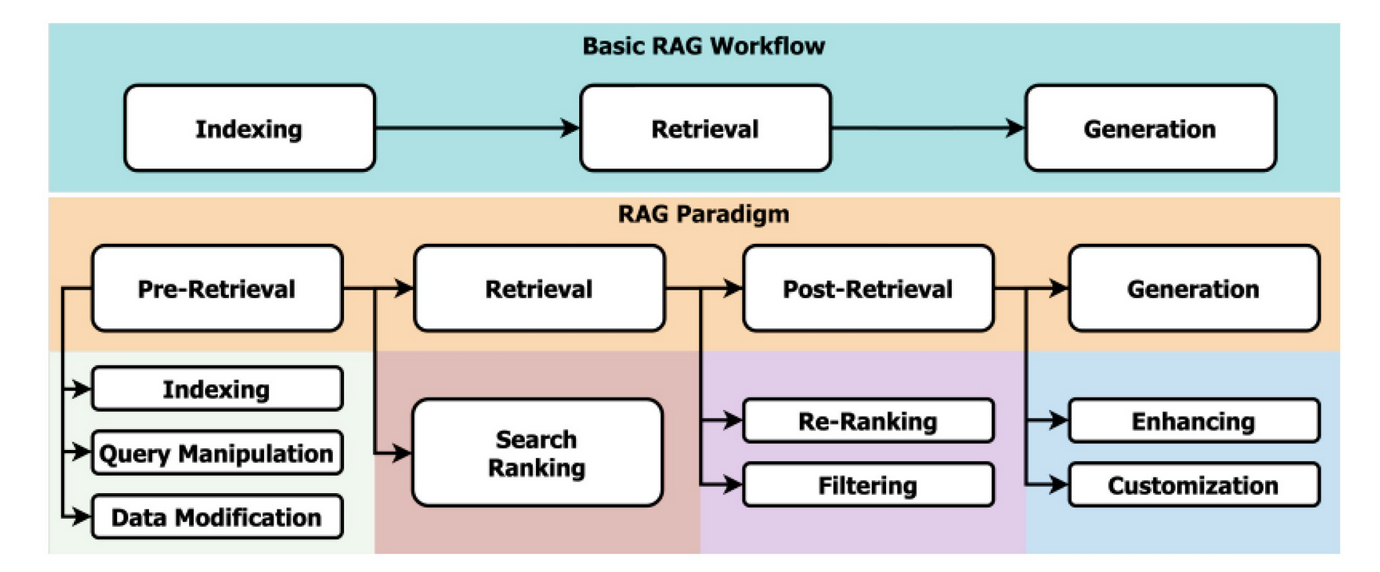
Information Retrieval Stage Challenges
Some challenges in the information retrieval stage of RAG pipelines include maintaining high-quality data curation, efficient embedding storage, and reliable data retrieval systems.
Generation Stage Process
The generation stage involves using retrieved data to generate contextually aligned responses, thus enhancing the model's generative capabilities.
Building an Effective RAG Pipeline
Constructing a successful RAG pipeline involves several steps, starting with data preparation and curation. Platforms like Encord aid in transforming raw data into structured knowledge bases efficiently.
Data Chunking and Embedding
Data is segmented into manageable chunks to optimize embedding generation and retrieval accuracy. These embeddings form the basis for similarity search and retrieval in RAG pipelines.
Information Retrieval System
The information retrieval system matches queries with stored embeddings, using similarity search algorithms to deliver relevant data to the generative model. Context-aware ranking systems refine the retrieval process for high-quality inputs.
Challenges and Solutions
While RAG pipelines are effective, challenges like low-quality data and inefficient retrieval systems can impact their performance. Solutions include proper data preprocessing, optimized retrieval techniques, and context-preserving chunking algorithms.
Recommendations
Encord simplifies dataset management and data curation, crucial for RAG pipelines. By leveraging Retrieval-Augmented Generation, AI systems can access real-time, contextually relevant data, enhancing their capabilities for various applications.
Explore Encord's products for efficient data workflow management and unleash the full potential of RAG pipelines in creating intelligent AI solutions.









