
How Good Are the Latest Open LLMs? And Is DPO Better Than PPO?
April 2024 has been an exciting month with multiple significant events including birthday celebrations, a new book release, the arrival of spring, and the release of four major open LLMs: Mixtral, Meta AI's Llama 3, Microsoft's Phi-3, and Apple's OpenELM.
Review of Mixtral, Llama 3, and Phi-3
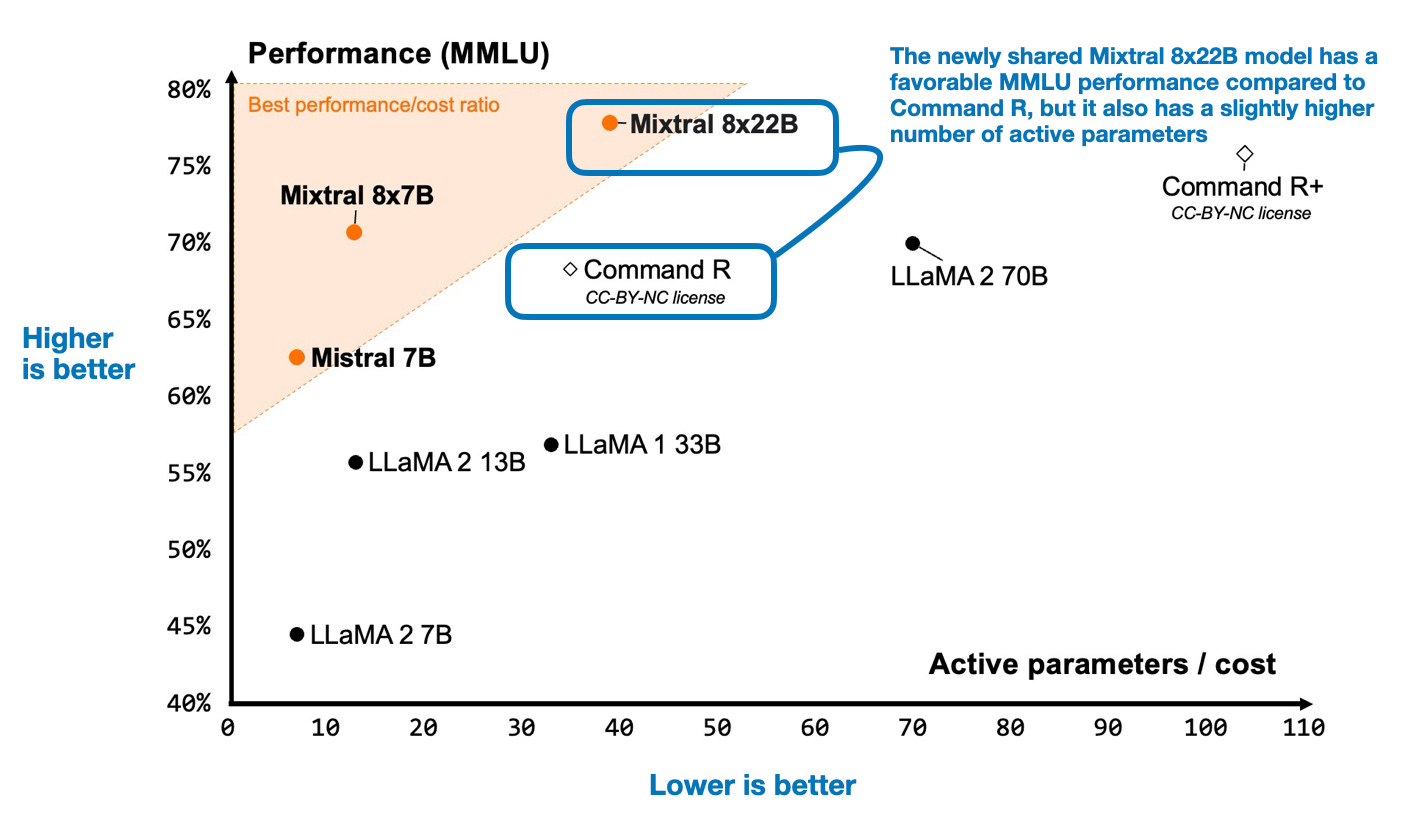
First, let's explore the latest major LLM releases. Mixtral 8x22B, the newest MoE model by Mistral AI, has been generating buzz. Similar to its predecessor, Mixtral 8x7B, this model aims to enhance transformer architecture with 8 expert layers. The performance of Mixtral 8x22B has been analyzed against various LLMs on the MMLU benchmark, showcasing its capabilities.

Meta AI's Llama series has also seen advancements, with the recent introduction of Llama 3 models. These models build upon the success of Llama 2 and come in sizes ranging from 8B to 70B. With improvements in vocabulary size and attention mechanisms, the Llama 3 architecture offers enhanced performance.
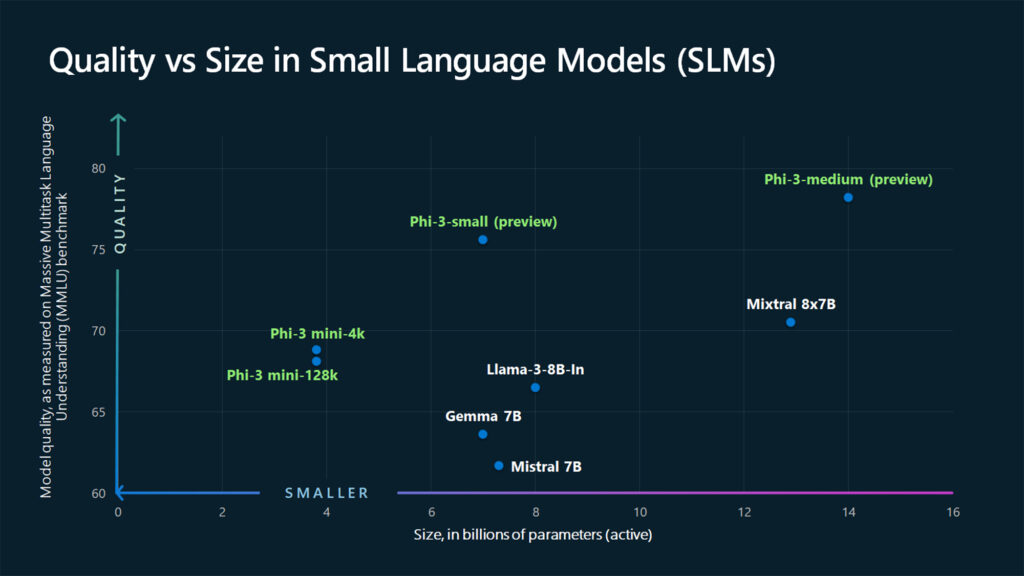
Microsoft's Phi-3 LLM, based on the Llama architecture, has emerged as a strong contender despite using a smaller dataset. The Phi-3 models have demonstrated superior performance compared to Llama 3, highlighting the impact of dataset quality on model effectiveness.
Insights into OpenELM
Apple's OpenELM introduces a suite of LLM models tailored for mobile devices. With sizes ranging from 270M to 3B, OpenELM leverages rejection sampling and direct preference optimization for training. The architecture of OpenELM features a layer-wise scaling strategy, enhancing its adaptability and performance.
The research behind OpenELM delves into dataset curation and scaling techniques, shedding light on the model's development process. By sharing detailed insights into the training methods and data utilization, Apple's OpenELM contributes to the growing body of knowledge in the LLM domain.
Comparing DPO and PPO for LLM Alignment
In a comprehensive study comparing direct preference optimization (DPO) and proximal policy optimization (PPO) for LLM alignment, researchers assess the efficacy of these reinforcement learning methods. Both DPO and PPO play critical roles in refining LLMs based on human feedback, influencing the quality and reliability of model outputs.
As the landscape of open LLMs continues to evolve, exploring different training approaches and algorithmic frameworks becomes essential. The ongoing research and advancements in the field offer valuable insights into optimizing LLM performance and aligning these models with user preferences.









