
The Power of Knowledge Graphs: Comparing Claude, ChatGPT ...
Knowledge Graphs are an increasingly powerful tool in today’s data-driven era, providing the crucial ability to structure extensive amounts of information. From search engines, to recommendation systems, to healthcare, finance, e-commerce, and more, Knowledge Graphs are very versatile tools that enhance data integration, analysis, and retrieval in various fields.
Populating these graphs typically begins with Named Entity Recognition (NER). This process identifies and categorizes the entities in a text into a Resource Description Framework (RDF), which provides the foundation for building Knowledge Graphs. An RDF is a standardized model for data interchange that allows data to be structured in a way that machines can understand. RDFs have “Triple Structure” where information is represented as a set of three components: the “Subject”, the entity being described, the “Predicate”, the property or characteristic of the subject, and the “Object”, the value of the property related to the subject. RDF uses Uniform Resource Identifiers (URIs) to identify subjects, predicates, and objects, ensuring that each element is distinct.
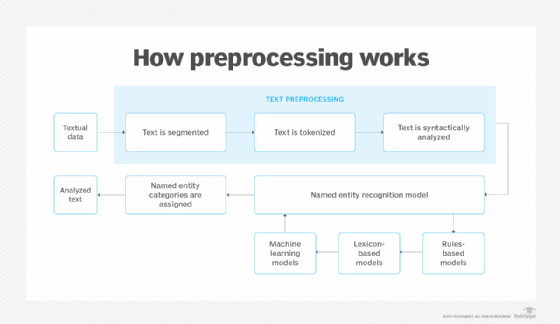
With continuous advancements in AI, there are various approaches to generate RDFs to form Knowledge Graphs. This article will explore how Claude, ChatGPT, and custom-code using the SpaCy framework compare in terms of converting raw text data into a structured RDF. Claude and ChatGPT would fall under “LLM-based” approaches to generating knowledge graphs, while the SpaCy model would be considered a “traditional” NER approach.
Claude, ChatGPT, and SpaCy
Claude is an AI language model by Anthropic that can perform natural language processing (NLP) tasks. ChatGPT is a conversation-based AI based on GPT-4 that can perform a variety of NLP tasks and is common in chatbot development. Lastly, the custom-coded implementation using SpaCy allows for domain-specific natural language processing. SpaCy is an open-source NLP library including tools for tokenization, named entity recognition (NER), and more.
For my comparison, I tested each method’s ability to create an RDF representation of SMU’s Computer Science (B.S.) degree plan. I experimented with catalog data in hopes of using these findings for a future project. See the resulting RDFs from each method:
Claude
ChatGPT:
Custom SpaCy:
As evident, the custom SpaCy implementation provided the most in-depth representation of the data, followed by Claude, and finally ChatGPT. SpaCy allows you to create models that are highly specialized and relevant to your domain, which leads to highly accurate and detailed RDF triples. SpaCy supports rule-based components — in addition to machine learning models — which helps capture specific relationships and patterns that generic models may not. In terms of language processing, SpaCy’s dependency parsing capabilities allow for better understanding of sentence structure, further improving the ability to identify relationships between entities. Finally, SpaCy’s output can be converted into precise, structured data using the RDFLib library.
Overall, the ability of SpaCy to be fine-tuned to the specific needs of the data allowed for the most in-depth, structured representation of the data. Claude and ChatGPT are designed for various NLP tasks and are very powerful, however, they did not provide as much detail in the RDF when prompted. It is likely that with more meticulous and thoughtful prompts, these models would perform better.









