
AI 'gold rush' for chatbot training data could run out of human-written ...
Artificial intelligence systems like ChatGPT could soon run out of what keeps making them smarter — the tens of trillions of words people have written and shared online. A new study released Thursday by research group Epoch AI projects that tech companies will exhaust the supply of publicly available training data for AI language models by roughly the turn of the decade — sometime between 2026 and 2032.
The Challenge of Depleting Training Data
Comparing it to a “literal gold rush” that depletes finite natural resources, Tamay Besiroglu, an author of the study, said the AI field might face challenges in maintaining its current pace of progress once it drains the reserves of human-generated writing. 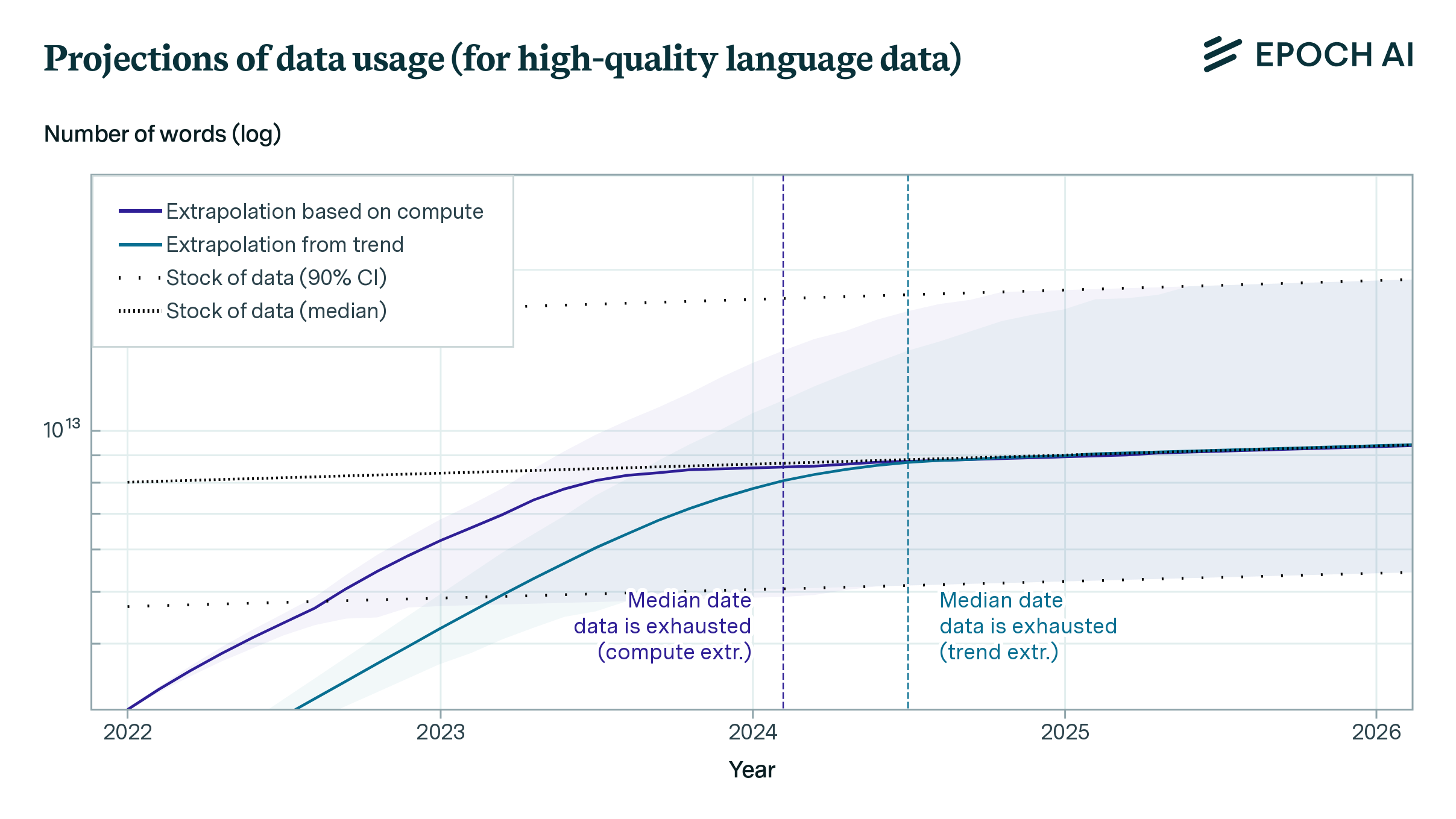
In the short term, tech companies like ChatGPT-maker OpenAI and Google are racing to secure and sometimes pay for high-quality data sources to train their AI large language models – for instance, by signing deals to tap into the steady flow of sentences coming out of Reddit forums and news media outlets. WATCH: Current, former OpenAI employees warn company not doing enough control dangers of AI
The Future of AI Development
In the longer term, there won’t be enough new blogs, news articles, and social media commentary to sustain the current trajectory of AI development, putting pressure on companies to tap into sensitive data now considered private — such as emails or text messages — or relying on less-reliable “synthetic data” spit out by the chatbots themselves.
“There is a serious bottleneck here,” Besiroglu said. “If you start hitting those constraints about how much data you have, then you can’t really scale up your models efficiently anymore. And scaling up models has been probably the most important way of expanding their capabilities and improving the quality of their output.”
Projection and Concerns
The researchers first made their projections two years ago — shortly before ChatGPT’s debut — in a working paper that forecast a more imminent 2026 cutoff of high-quality text data. Much has changed since then, including new techniques that enabled AI researchers to make better use of the data they already have and sometimes “overtrain” on the same sources multiple times. But there are limits, and after further research, Epoch now foresees running out of public text data sometime in the next two to eight years.
Shifts in AI Landscape
The amount of text data fed into AI language models has been growing about 2.5 times per year, while computing has grown about 4 times per year, according to the Epoch study. Facebook parent company Meta Platforms recently claimed the largest version of their upcoming Llama 3 model — which has not yet been released — has been trained on up to 15 trillion tokens, each of which can represent a piece of a word. :max_bytes(150000):strip_icc()/large-language-model-7563532-final-9e350e9fa02d4685887aa061af7a2de2.png)
READ MORE: California advances measures targeting AI discrimination and sexually abusive deepfakes
Impact on AI Development
From the perspective of AI developers, Epoch’s study says paying millions of humans to generate the text that AI models will need “is unlikely to be an economical way” to drive better technical performance.
As OpenAI begins work on training the next generation of its GPT large language models, CEO Sam Altman told the audience at a United Nations event last month that the company has already experimented with “generating lots of synthetic data” for training. “I think what you need is high-quality data. There is low-quality synthetic data. There’s low-quality human data,” Altman said.
AI companies should be “concerned about how human-generated content continues to exist and continues to be accessible,” said Selena Deckelmann, chief product and technology officer at the Wikimedia Foundation, which runs Wikipedia.









