
#ai #llm #chatgpt #claude #gemini | Michael Kisilenko
Breaking News: Microsoft's recent paper has unveiled the true scale of major LLM models, and the numbers are truly astounding.
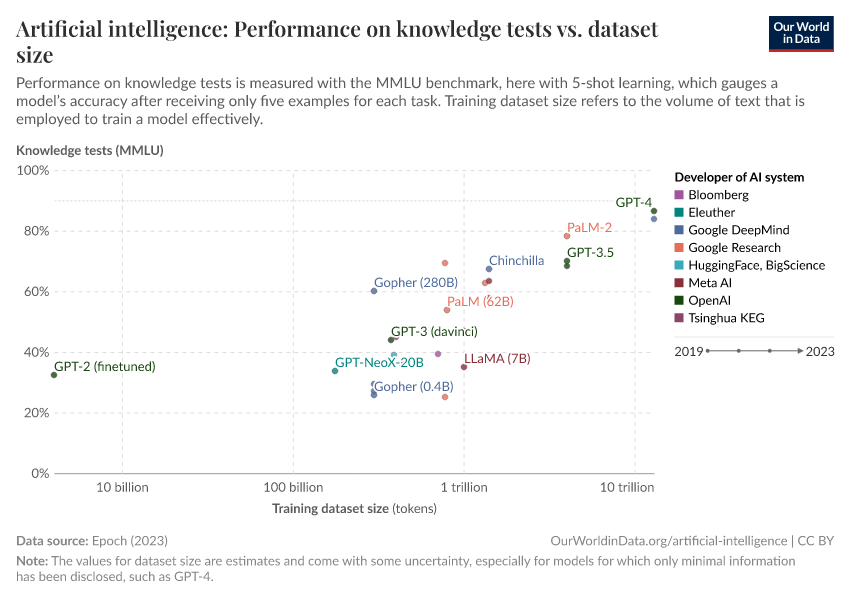
Insights into Language Models
Here's a breakdown of what we now understand about these language models:
- GPT-4 boasts an immense size of 1.76 trillion parameters
- Claude 3.5 Sonnet stands at 175 billion
- GPT-4o and o1-mini are both at 200 billion
- o1-preview reaches 300 billion
- GPT-4o-mini surprisingly sits at 8 billion

Microsoft researchers employed a unique technique known as "attention pattern analysis" to deduce these sizes, akin to scrutinizing the footprints of these AI behemoths.
However, the most intriguing aspect is that size doesn't dictate AI performance. Smaller models are proving to be remarkably efficient:
- GPT-4o-mini (8 billion) delivers exceptional performance
- Optimization outweighs raw size
- Efficient architecture surpasses brute force
Implications and the Future
What does this mean for the future of AI development?
- Greater emphasis on model efficiency
- Rise of smaller, optimized models
- Environmental concerns driving innovation

The AI landscape is evolving rapidly, with a newfound focus on efficiency shaping the industry's trajectory.
Source: Microsoft Research (arXiv:2412.19260)
Follow me for more updates and insights in the realm of AI.









