
Scaling AI Smarter: NAMMs Revolutionize Transformer Performance
Discover how NAMMs streamline transformer models with cutting-edge memory management, unlocking unprecedented performance across tasks and modalities.
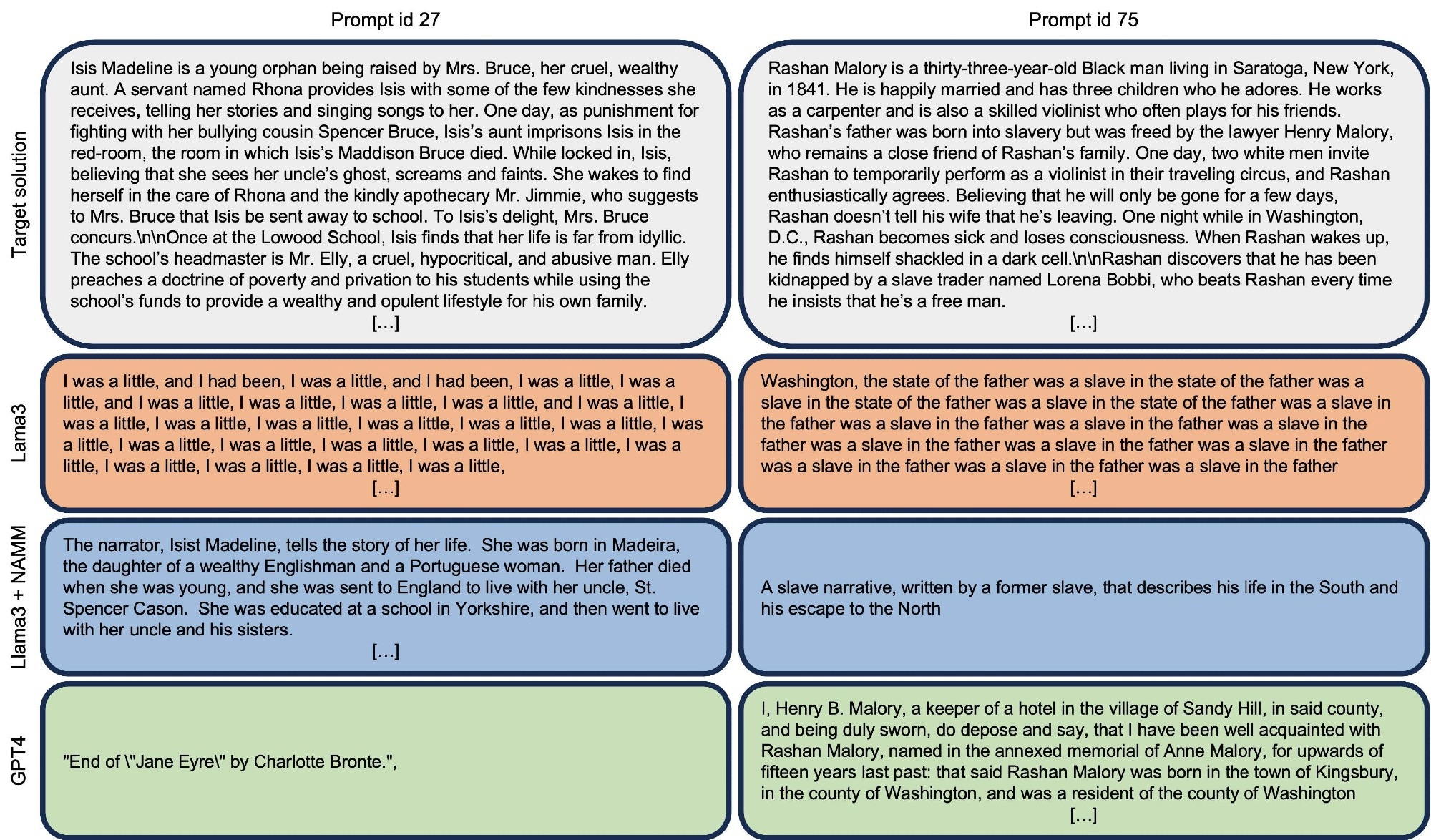
Qualitative examples comparing the ground produced responses by Llama3 with and without our NAMM memory, together with GPT4, on two prompts from the En.Sum task part of InfiniteBench.
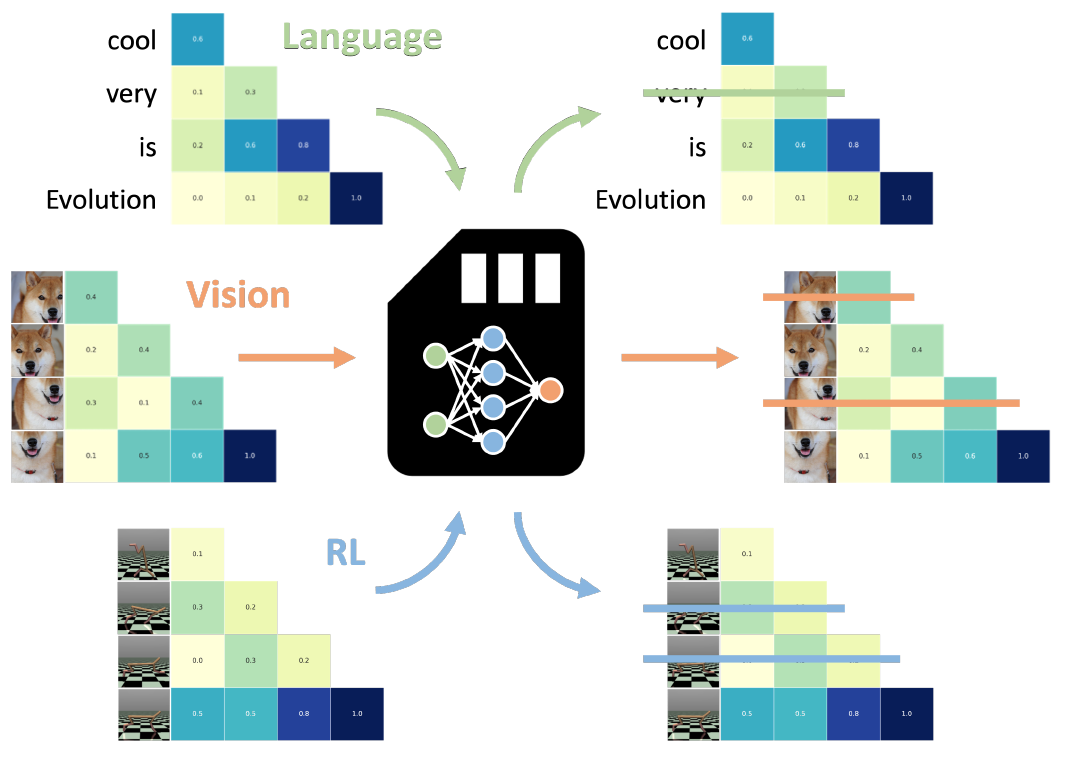
NAMMs use evolution to optimize the performance of LMs by pruning their KV cache memory. Evolved NAMMs can be zero-shot transferred to other transformers, even across input modalities and task domains.

Spectrogram-Based Feature Extraction: NAMMs utilize the Short-Time Fourier Transform (STFT) with a Hann window to create spectrogram representations of attention matrices, enabling universal and compact memory management across transformer architectures.
Introduction to NAMMs
Transformer architectures have become a cornerstone in deep learning, underpinning modern foundation models due to their exceptional scalability and performance. These models rely on a context window of input tokens, which poses challenges in addressing long-range tasks efficiently. Extending this context window often increases computational costs, making transformers resource-intensive.
Memory Management with NAMMs
Existing approaches have achieved partial success in reducing memory size while limiting performance degradation. However, this paper introduced NAMMs, a novel framework that redefined memory management in transformers by employing the Short-Time Fourier Transform (STFT) to extract spectrogram representations of attention matrices.
Efficiency and Performance Benefits
NAMMs demonstrated efficiency and performance benefits across diverse benchmarks and modalities, including vision and reinforcement learning. They addressed the inefficiencies of transformer models and optimized the KV cache by introducing a model-agnostic feature extraction framework.
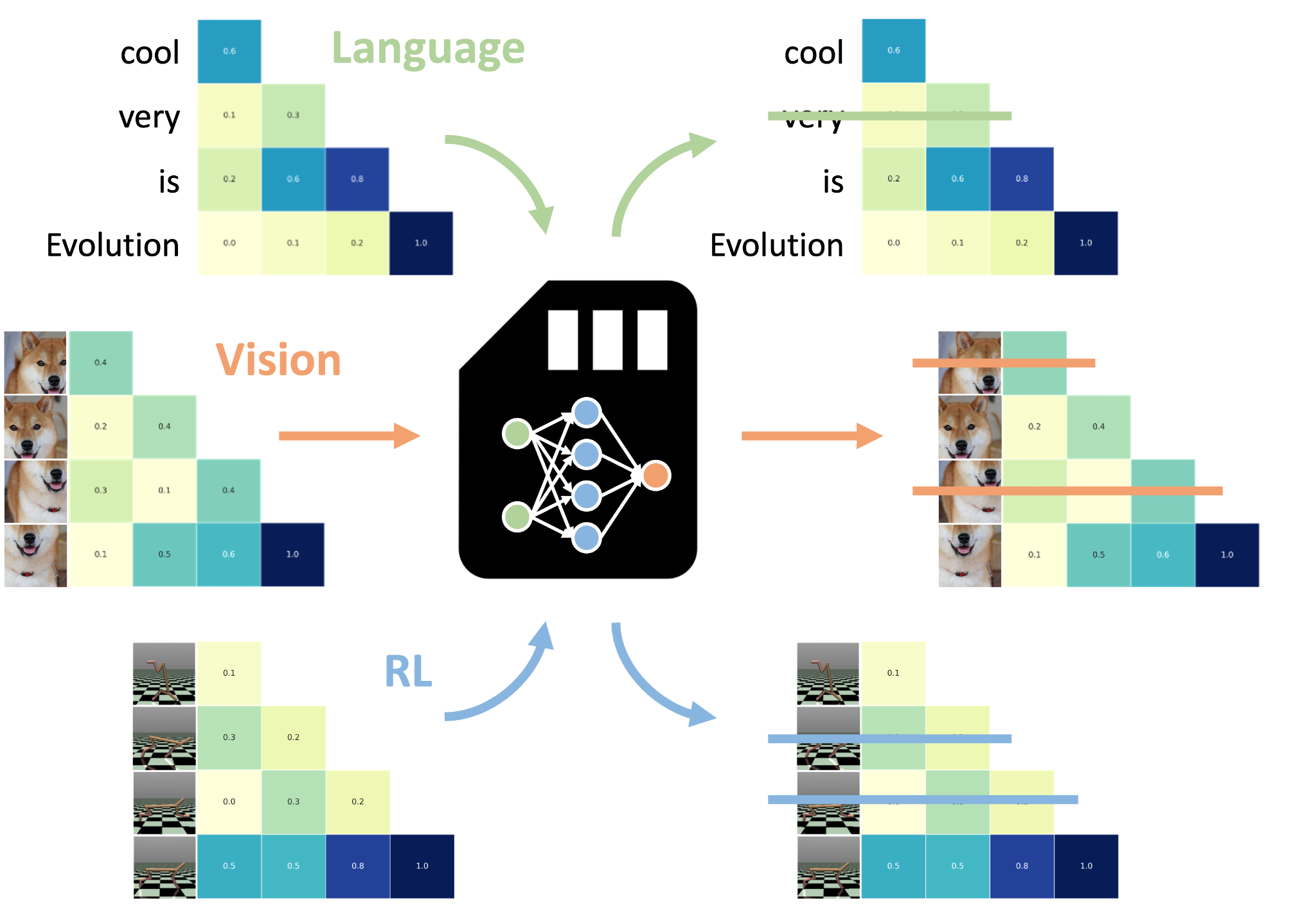
Zero-Shot Transfer Across Modalities
NAMMs demonstrated remarkable transferability, enhancing transformer performance in diverse domains, including computer vision and reinforcement learning, without additional task-specific training.
Evaluation and Results
The researchers evaluated NAMMs across various benchmarks against full-context transformers and recent hand-designed KV cache management methods. NAMMs demonstrated superior performance and efficiency by learning to discard unhelpful information and achieved significant improvements in benchmarks like LongBench and InfiniteBench.
Conclusion

In conclusion, NAMMs offer a novel framework to enhance transformer efficiency and performance while reducing memory usage. By dynamically managing latent memory, NAMMs optimize KV cache usage, surpassing traditional hand-designed methods. Their evolutionary approach enables NAMMs to outperform baselines across diverse benchmarks and transfer effectively across architectures and modalities.









