
Google Gemini API: Making Long Context LLMs Usable with Context Caching
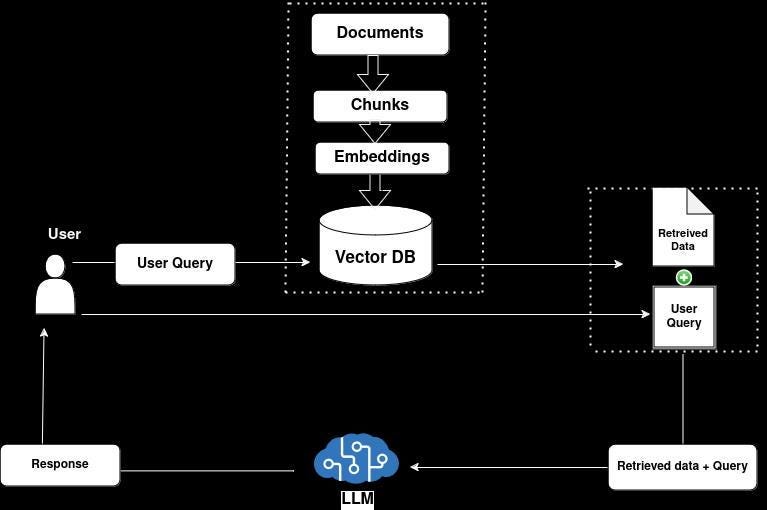
Google has recently introduced support for context caching in their Gemini API to overcome the challenges associated with long context Language Model Models (LLMs). Long context LLMs have the capacity to store vast amounts of information, but they encounter issues like extended processing time, high latency, and increased costs due to processing all tokens in each query.
Context caching is a solution designed to address these drawbacks. By storing extensive context datasets and sending only concise user queries with each request, context caching minimizes the number of tokens processed per query. This not only reduces costs but also has the potential to enhance latency.
Setting Up and Utilizing Context Caching
For developers interested in leveraging context caching, Google offers a comprehensive video tutorial that explains the setup and usage of this feature. It covers essential tasks such as creating and managing caches, establishing the time-to-live for cached data, and managing cache metadata. The implementation involves utilizing the Google generative AI client for Python, loading substantial documents, and caching the content.
The video also delves into considerations like storage expenses and performance implications. While the current implementation primarily focuses on cost reduction, forthcoming updates are anticipated to enhance latency as well.

Enhancing Developer Experience
The tutorial serves as a valuable resource for developers, offering a detailed walkthrough of the process involved in implementing context caching in their applications. By following the instructions provided, developers can seamlessly incorporate context caching into their projects.









