
Deploying Generative AI LLMs on Docker - Open Source For You
Built on massive datasets, large language models or LLMs are closely associated with generative AI. Integrating these models with Docker has quite a few advantages.Generative AI, a growing and prominent segment of artificial intelligence, refers to systems capable of producing content autonomously, ranging from text, images and music, to even code. Unlike traditional AI systems, which are primarily deterministic and perform tasks based on explicit rules or supervised learning, generative AI models are designed to create new data that mirrors the characteristics of their training data. This capability has profound implications, transforming industries by automating creative processes, enhancing human creativity, and opening new avenues for innovation.
Market Overview
According to Fortune Business Insights, the global generative AI market was valued at approximately US$ 43.87 billion in 2023. This market is projected to increase from US$ 67.18 billion in 2024 to US$ 967.65 billion by 2032. This dominance can be attributed to several factors, including the presence of key technology companies, significant investments in AI research and development, and a robust ecosystem that fosters innovation and collaboration. As businesses across various sectors increasingly adopt generative AI solutions to enhance their operations, the market is poised for unprecedented growth and transformation in the coming years.
Role of Large Language Models (LLMs)
Large language models (LLMs) are closely associated with generative AI and specifically focused on text generation and comprehension. LLMs such as OpenAI’s GPT-4 and Google’s PaLM are built on massive datasets encompassing a wide range of human knowledge. These models are trained to understand and generate human language with a high degree of coherence and fluency, making them instrumental in applications ranging from conversational agents to automated content creation.
The versatility of LLMs is evident in their application across various domains. In the healthcare industry, LLMs are used to assist in the drafting of clinical notes and patient communication. In finance, they generate reports and assist with customer service. The adaptability of these models makes them a cornerstone of the AI revolution, driving innovation across multiple sectors.
Deployment of Large Language Models
The deployment of large language models (LLMs) involves intricate processes that require not only advanced computational resources but also sophisticated platforms to ensure efficient, scalable, and secure operations. With the rise of LLMs in various domains, selecting the appropriate platform for deployment is crucial for maximising the potential of these models while balancing cost, performance, and flexibility.
Ollama is a specialised platform that facilitates the deployment and management of large language models (LLMs) in local environments. This tool is particularly valuable for developers and researchers who need to fine-tune and run models without relying on cloud-based infrastructure, ensuring both privacy and control over computational resources.
Integrating Generative AI and LLMs with Docker
Integrating generative AI and large language models with Docker involves a dedicated process that enhances the scalability, portability, and deployment efficiency of these advanced machine learning models. Docker, a containerisation platform, encapsulates applications and their dependencies into lightweight, self-sufficient containers, enabling seamless deployment across various environments.
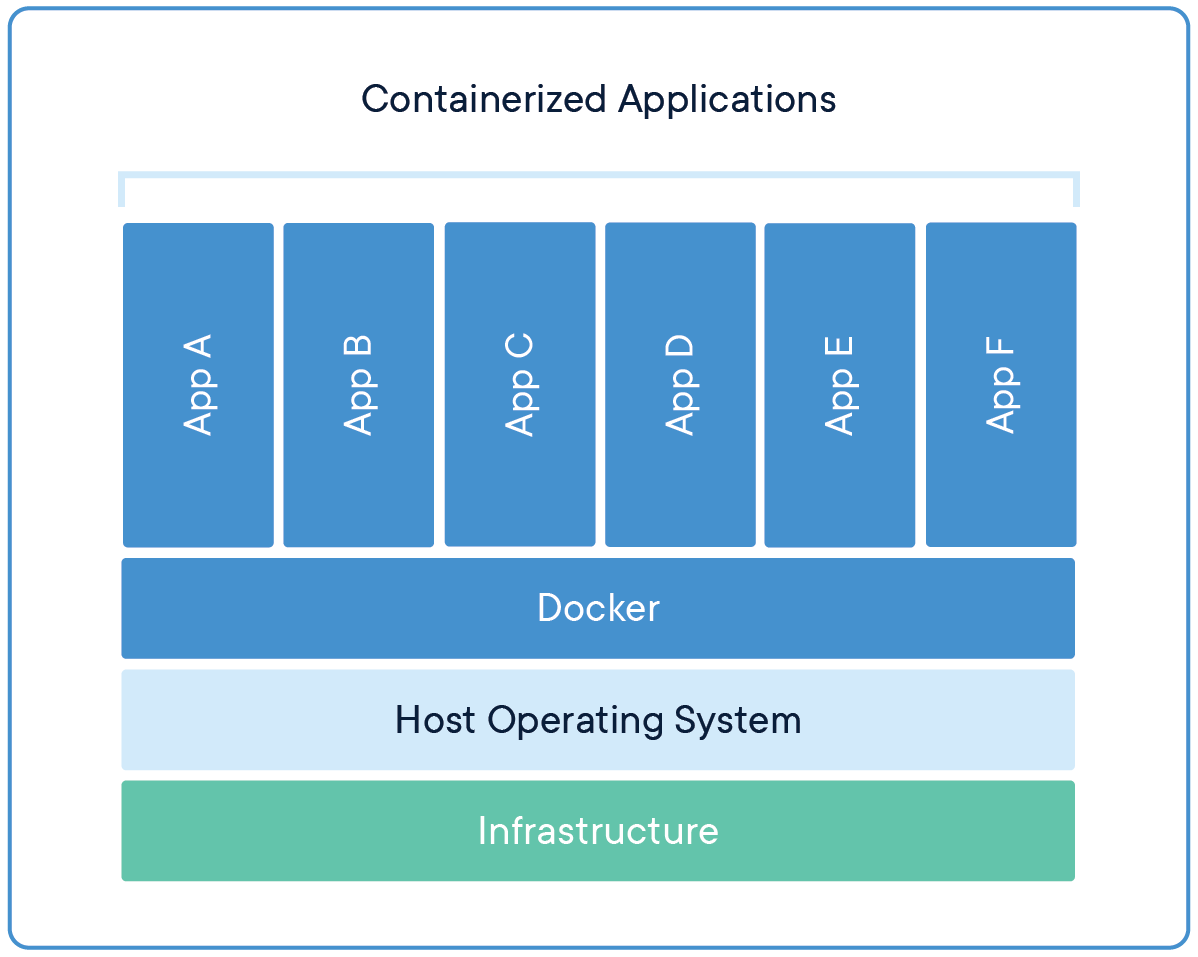
The first step in Dockerizing a generative AI LLM is to create a Docker image that contains the model, its runtime environment, and all requisite dependencies. This process typically begins with selecting a base image, such as an official Python image if the model is implemented in Python, or a specialised machine learning image like TensorFlow or PyTorch, depending on the framework used.
Steps for Dockerizing a Generative AI LLM
- Step 1: Installation and deployment of Docker
Download Install Docker for your operating system on the official Docker website. - Step 2: Create a Dockerfile
Create a file named Dockerfile in your project directory as per the specifications. - Step 3: Build the Docker image
Open your terminal, navigate to your project directory, and build the Docker image. - Step 4: Run the Docker container
Start a container from the image with specified configurations. - Step 5: Download an LLM model
Download a model using the Ollama CLI within the container. - Step 6: Interact with the model
Interact with the model using the Ollama CLI or the Ollama Web UI for a user-friendly interface.
Generative AI LLMs, particularly state-of-the-art models, are characterised by their massive size, often requiring significant disk space and memory. Integrating these models into Docker necessitates efficient handling of large model files, either by including the model weights in the Docker image or by mounting external storage volumes where the models are stored.

Leveraging GPU acceleration is often indispensable for running LLMs efficiently, given their computational demands. Docker allows for the integration of GPU resources by using NVIDIA’s Docker runtime, facilitating direct access to the host’s GPU.
One of the primary advantages of Docker is its ability to facilitate the scaling of applications. For generative AI LLMs, this means that multiple instances of the model can be deployed across different nodes within a cluster, thereby distributing the load and improving response times.
Security is paramount when deploying LLMs in Docker containers, particularly in production environments where models may process sensitive data. Docker provides mechanisms to enhance container security, including secure base images, least privilege access, and network policies.
Integrating Docker into a CI/CD pipeline is crucial for streamlining the deployment of generative AI LLMs. The CI/CD pipeline automates the build, testing, and deployment of Docker images, enabling efficient updates and rollbacks.
Effective monitoring and logging are essential for maintaining the health and performance of Dockerized LLMs in production. Tools such as Prometheus, Grafana, and ELK Stack can be integrated with Docker containers to provide real-time insights into metrics like CPU and memory usage, GPU utilisation, and error rates.









