
Big Tech needs to get creative as it runs out of data to train its AI ...
OpenAI, Meta, Google, and other Big Tech firms rely heavily on online data to train their AI models. However, the rapid learning pace of AI systems could deplete all available data by 2026. This poses a significant challenge for AI systems to continue learning and evolving.
The Importance of Data in AI Training
AI models become more powerful with the volume of data they are trained on. As the demand for advanced AI capabilities grows, tech giants like Meta, Google, and OpenAI are facing a critical issue - the shortage of high-quality data to train their models effectively. By 2026, it is projected that the existing reservoir of quality data may be fully utilized, as reported by Epoch, an AI research institute.
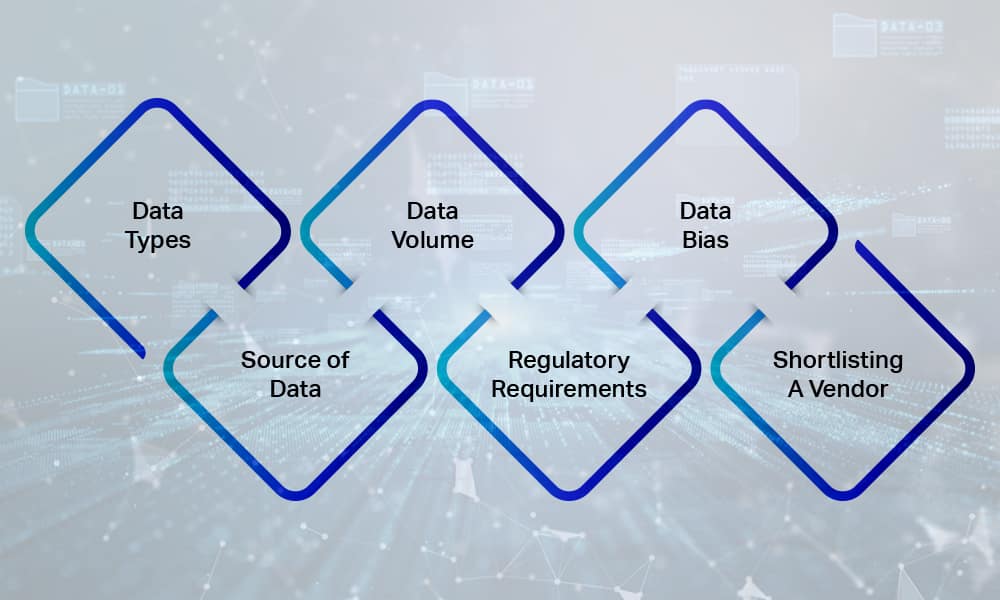
Exploring New Data Sources
To address the diminishing data reserves, major tech companies are exploring innovative solutions to feed their AI systems with fresh learning material. Some of the creative approaches being considered include:
- Tapping into consumer data available in Google Docs, Sheets, and Slides
- Exploring potential acquisitions like Simon & Schuster for data sourcing
- Generating synthetic data through AI systems
- Developing tools like Whisper for speech recognition and data translation
- Exploring databases like Photobucket for a rich repository of images
Challenges and Considerations
While these approaches offer potential solutions, there are challenges associated with training AI systems on new or synthetic data. Synthetic data, though generated by AI, may inadvertently reinforce biases and limitations inherent in AI algorithms. To mitigate this, companies like OpenAI are implementing processes to validate and refine the synthetic data utilized in training.
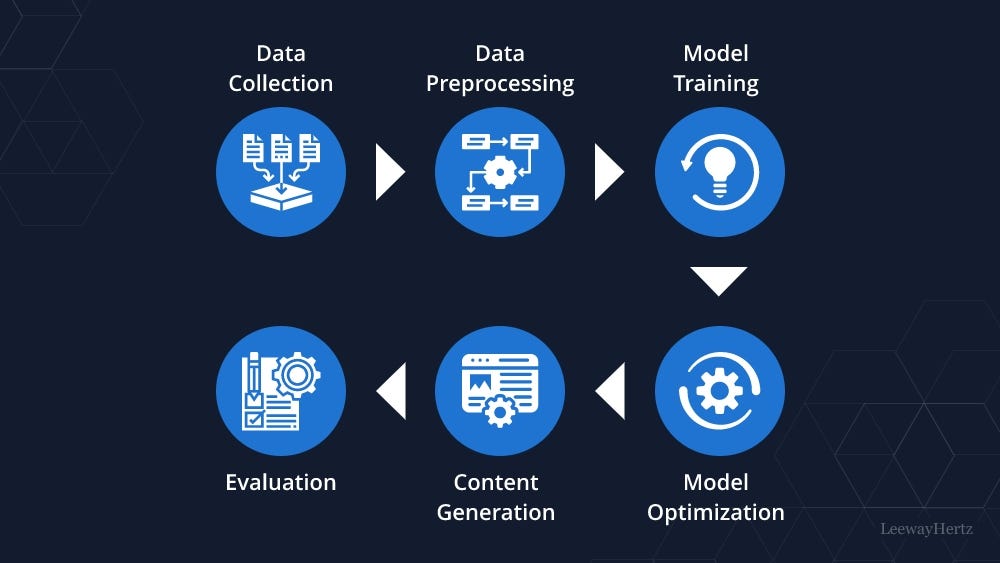
It is evident that the future of AI training will require continuous innovation and adaptation to overcome the data scarcity challenges faced by Big Tech companies.









