
Arpita Gupta on LinkedIn: What's the old BM25 technique that Anthropic’s new “Contextual Retrieval” method uses
Anthropic introduced the method called "Contextual Retrieval" a month ago to address the loss of context when documents are split into smaller chunks for processing.
The Technique Used in Contextual Retrieval
While the key enabling Contextual Retrieval is the new prompt caching feature done by using Anthropic’s Claude model, the technique employs two key sub-techniques:
- Contextual Embeddings
- Contextual BM25
The purpose of using BM25 in Contextual Retrieval is to add relevant contextual information to each chunk before it's embedded or indexed, maintaining critical details that might be lost with traditional methods.

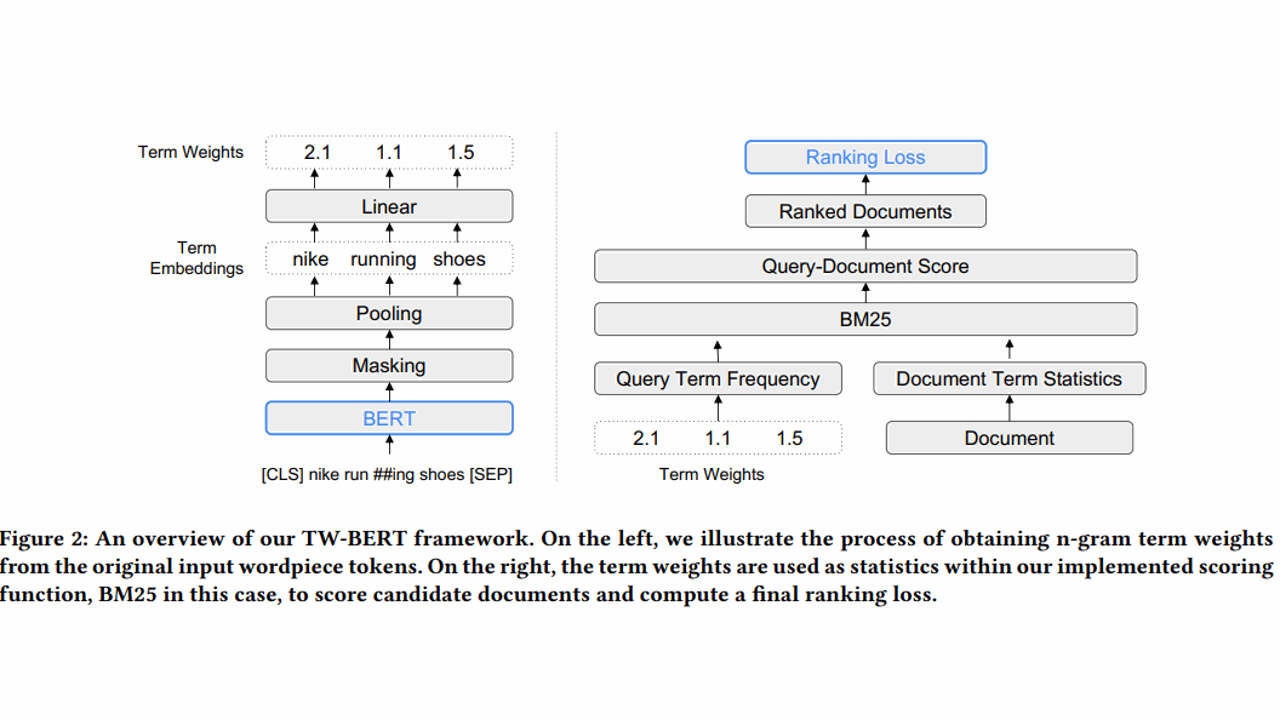
Importance of BM25 in Retrieval
BM25 is an old technique built on TF-IDF (Term Frequency-Inverse Document Frequency) and is particularly effective for queries that include unique identifiers or technical terms. It refines TF-IDF by considering document length and applying a saturation function to term frequency, which helps prevent common words from dominating the results.
Enhancing Performance with Contextual Retrieval
The new "Contextual Retrieval" method combines and deduplicates results using rank fusion techniques, adding the top-K chunks to the prompt to generate responses efficiently.
Contextual Retrieval enhances the retrieval process by using "Contextual Embeddings" and "Contextual BM25" to prepend chunk-specific explanatory contexts to each chunk before embedding and creating the BM25 index.
Combining Contextual Retrieval with Reranking further boosts performance by providing better responses and reducing cost and latency in processing information.
Reranking is a filtering technique that ensures only the most relevant chunks are passed to the model, improving the overall retrieval quality.
To explore the detailed document implementation, you can read the document from Anthropic.









