
AI-as-a-Service: Architecting GenAI Application Governance with Azure OpenAI
The past year has seen explosive growth for Azure OpenAI and large language models in general. With models reliant on a token-based approach for processing requests, ensuring prompt engineering is being done correctly, tracking what models and API’s are being used, load balancing across multiple instances, and creating chargeback models has become increasingly important. The use of Azure API Management (APIM) is key to solving these challenges.
There have been several announcements specific to the integration of Azure Open AI and APIM during Microsoft Build 2024 to make them easier to use together. As the importance of evaluating analytics and performing data science against Azure Open AI based workloads grows, storing usage information is critical. That’s where adding Microsoft Fabric and the Lakehouse to the architecture comes in. Capturing the usage data in an open format for long-term storage while enabling fast querying rounds out the overall solution.
Multiple Types of Generative AI Models
We must also consider that not all use cases will require the use of a Large Language Model (LLM). The recent rise of Small Language Models (SLM), such as Phi-3, for use cases that do not require LLMs, means there will very likely be multiple types of Generative AI (GenAI) models in use for a typical enterprise. These models will all be exposed through a centrally secured and governed set of APIs enabling every GenAI use case for rapid onboarding and adoption.
Having an AI Center of Enablement framework providing “AI-as-a-Service" will be incredibly important for organizations to safely enable different GenAI models quickly and their numerous versions all within the allocated budget or by using a chargeback model that can span across the enterprise regardless of the number of teams consuming the AI services and the number of subscriptions or environments they end up requiring. This model will also allow organizations to have complete consumption visibility if they purchase Provisioned Throughput Units (PTU) for their GenAI workloads in production.
Architectural Solution
The overall architecture for this “AI-as-a-Service" solution involves setting up a framework that ensures efficient governance and usage tracking. By incorporating Microsoft Fabric and the Lakehouse into the architecture, organizations can effectively store and query usage data for long-term insights.
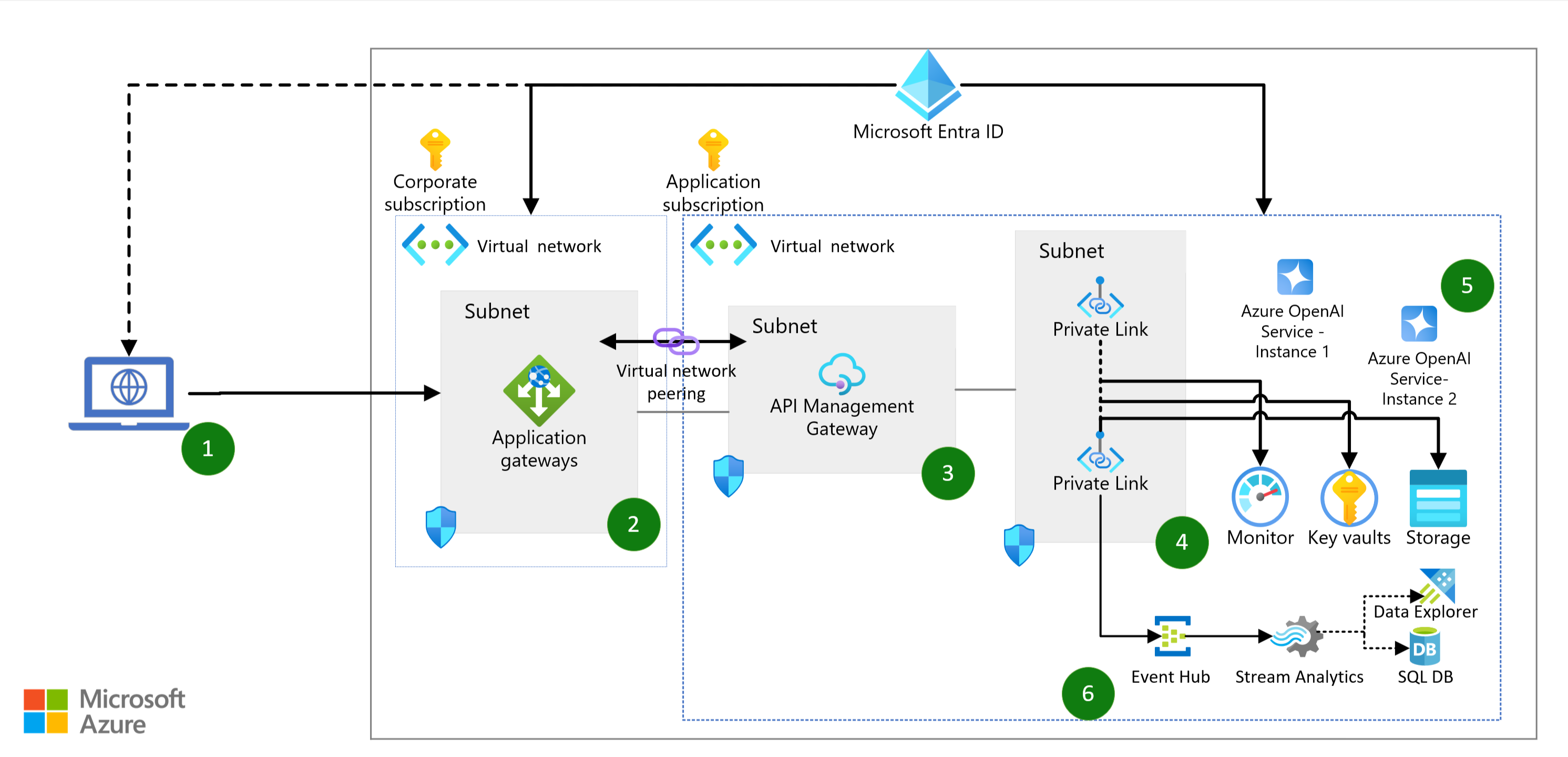
One key aspect of this architecture is the integration of Azure API Management and Azure OpenAI. Through the use of detailed instructions available on GitHub, organizations can build out the necessary components to enable seamless integration.
An Alternative Designs Landing Zone Accelerator is also provided to guide the development of foundational infrastructure in an enterprise-ready manner.
Token Consumption Tracking
One essential aspect of the architecture involves tracking token consumption through Azure API Management policies. By logging this information into Event Hub and storing it in the Fabric Lakehouse, organizations can create aggregate measures for in-depth analysis and reporting.
For example, the "TokensByBU" measure calculates the sum of the maximum "TotalTokens" value for each "BusinessUnitName" in the "aoaichargeback" table. This data can be further utilized for advanced analytical purposes and governance.

With the recent announcement of GenAI Gateway capabilities in Azure API Management, organizations can leverage the Azure OpenAI Emit Token Metric Policy to capture key consumption metrics directly into Application Insights.









