In-depth understanding of Llama 3 Tokenizer and PreTrainedTokenizerFast
Llama is a family of large language models released by Meta AI starting in February 2023. The Llama 3, Llama 3.1, and Llama 3.2 language models utilize PreTrainedTokenizerFast as their tokenizer. Tokens serve as the fundamental units of input and output in a language model, typically representing words, subwords, characters, and punctuation. A tokenizer plays a crucial role in a language model as it divides the input sequence into discrete tokens.
For a more profound comprehension of Llama PreTrainedTokenizerFast, a detailed study has been conducted on the Gemma Tokenizer and Llama 2 Tokenizer. It is important to note that Meta Llama 3 models make use of PreTrainedTokenizerFast.
When loading the Llama tokenizer with HuggingFace, 'meta-llama/Llama-3.2-1B-Instruct' can be used as an example. Other Llama-3 models also utilize the same tokenizer. Access to Llama may need to be requested, and an access token set up if not already done.
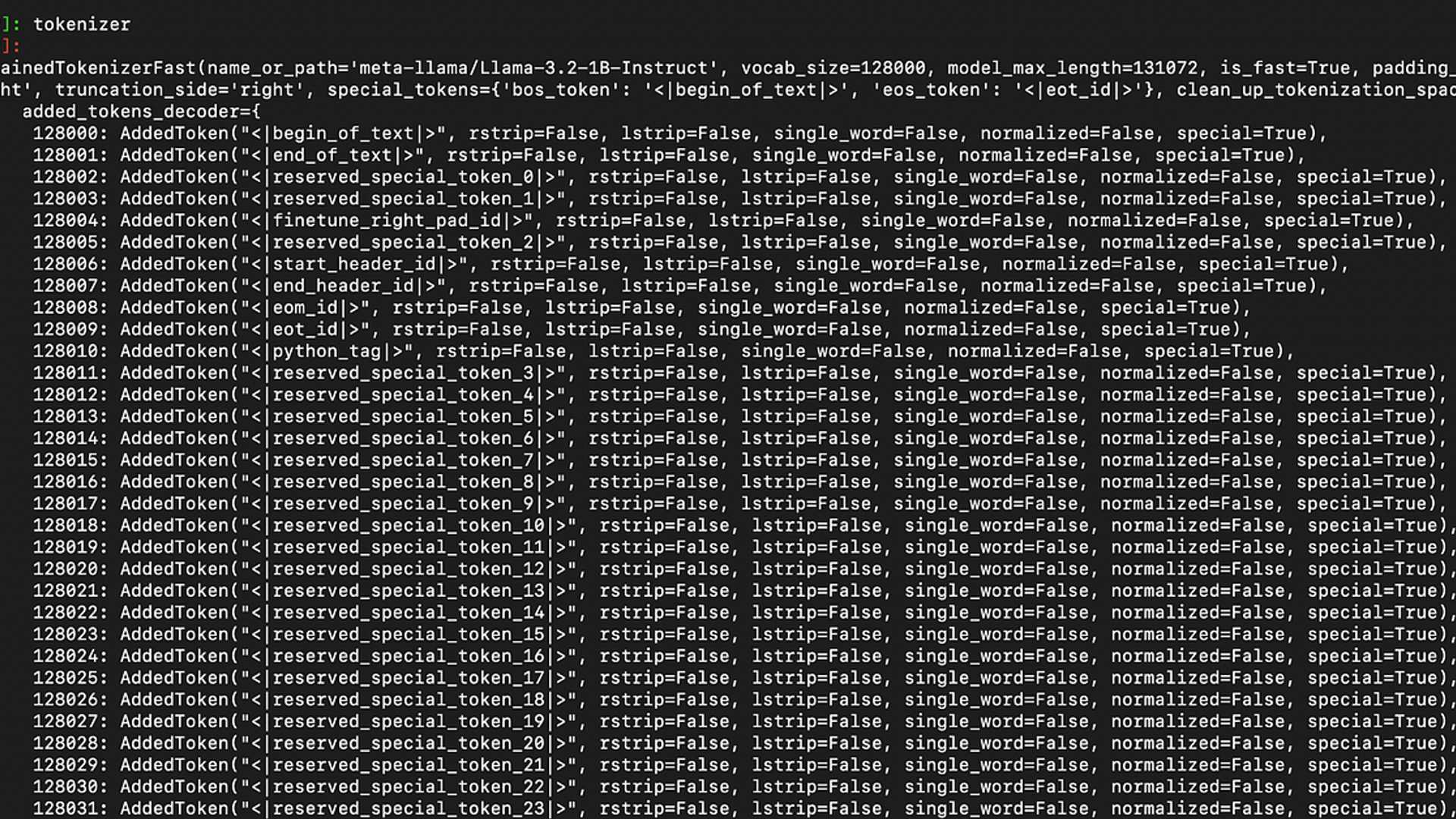
Printing out the Tokenizer
Tokenizer comprises two main parts: PreTrainedTokenizerFast and added_tokens_decoder.
If you are interested in delving deeper into the world of AI/ML and solving real-world problems, sharing knowledge and exploring consciousness and brain functionality, feel free to follow along on this journey.









