
NLTK: Natural Language Processing Made Easy - Open Source For ...
We focus on the basics of natural language processing and its applications using one of the most popular NLP libraries known as Natural Language Toolkit (NLTK)
In the age of generative AI, natural language processing (NLP) is a popular subject of interest. One of the most popular NLP libraries is NLTK or Natural Language Toolkit and we will learn how to use it effectively in this article.
Installation of NLTK using Google Colab
We will start by looking at the installation process of this library using Google Colab as the IDE. Let’s open the link as shown in Figure 1. Now open a new notebook and, in the first cell, give the command pip install nltk to install NLTK.
Tokenisation in NLTK
The first NLP process we will be looking at is tokenisation. Tokenisation is a natural language processing step in which we break a given piece of text into smaller parts. These parts can be simple phrases, sentences, words, and even characters or sets of characters, and are called tokens. Tokenisation is an important preprocessing step in most NLP applications. This may be done for feature engineering, text preprocessing or to build vocabulary for tasks like sentiment analysis.
Let us look at how we can do this using NLTK. First, import the required functions. I’ve given a sample string, which is the first paragraph of this article, as a sample for us to analyse. We are going to use the sentence tokeniser and the word tokeniser.
Stemming in NLTK
The next major NLP process we are going to learn is called stemming. This is a crucial process in which we reduce a given word to its root form. For example, the words work, working and worked have the same sentiment or meaning. Therefore, it becomes easy for us to manage them, whether to create a vocabulary or for any other purpose.
There are multiple methods or algorithms that help us perform this task, the most popular being Porter Stemmer. Let us now use the list of words we created above for checking out the stemming process.
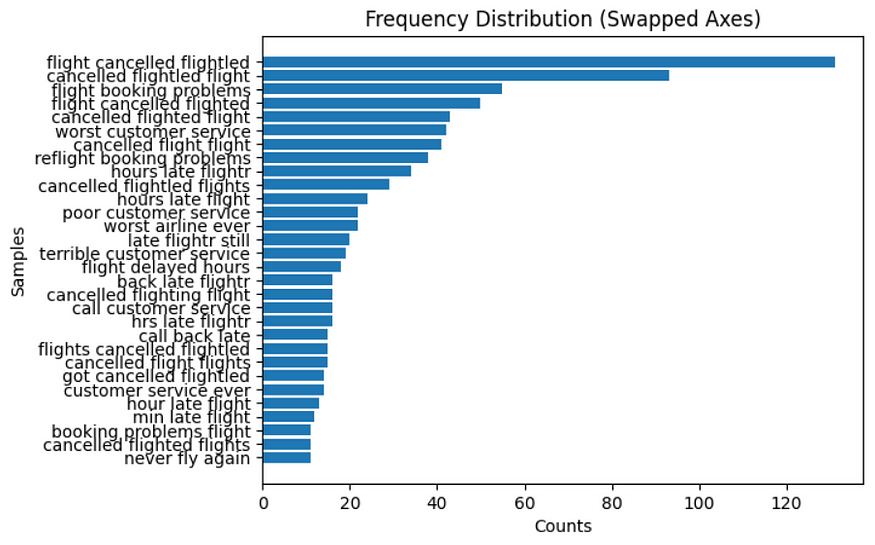
Frequency Distribution
Another important process is frequency distribution, a method usually used to count the vocabulary. The output is a dictionary, which may have the vocabulary as the key and the number of times the word has occurred in the text as the value.

Another process that is important is tagging the parts of speech, which must be done accurately. Here we tag the parts of speech for each word in the given piece of text.
Chunking and Named Entity Recognition
Chunking is done to identify phrases or groups of words that are generally used together. Another important process in the field of NLP is named entity recognition (NER), which has multiple business applications. It is used to detect private data in text, as well as extract important names/dates, a news article or a normal piece of text.
That’s it! You have learned most of the basic concepts in the field of NLP using NLTK. You can explore much more in this space as there are many libraries today helping with various NLP tasks.









