Meta AI Releases LayerSkip: A Novel AI Approach to Accelerate Inference in Large Language Models
Accelerating inference in large language models (LLMs) can be a challenging task due to their computational and memory requirements. This not only leads to significant costs but also high energy consumption. Current solutions often require specialized hardware or compromise model accuracy, making deployment difficult.
Introducing LayerSkip
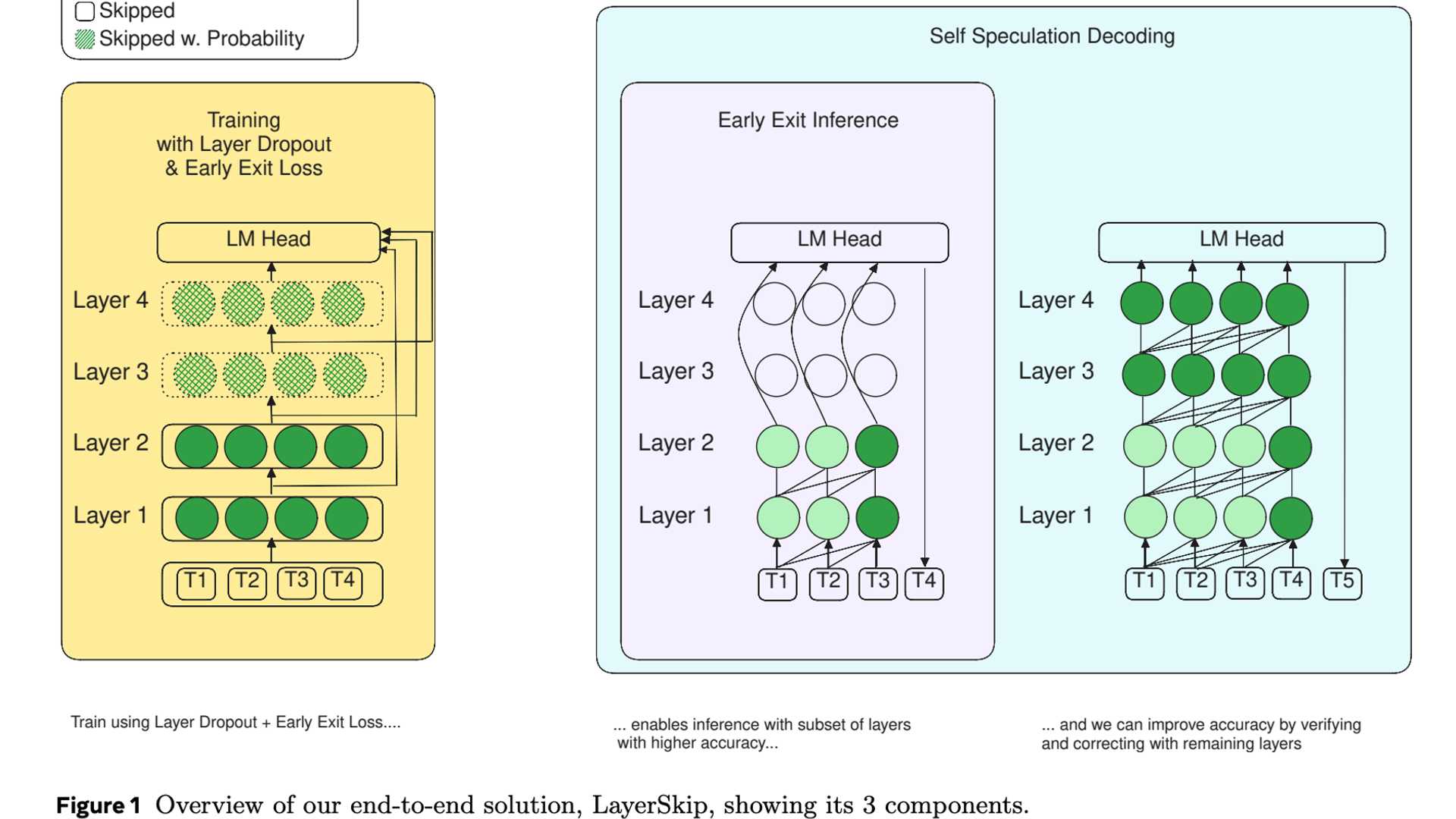
Researchers from FAIR at Meta, GenAI at Meta, Reality Labs, and various universities have collaboratively introduced LayerSkip. This innovative solution offers an end-to-end approach with a unique training recipe and self-speculative decoding. The key highlight is the use of a layer dropout mechanism during training.
LayerSkip consists of three main components:
- Layer dropout mechanism for training efficiency
- Early exit loss for robustness to early exits
- Self-speculative decoding for improved memory efficiency
Unique Features of LayerSkip
LayerSkip brings a novel self-speculative decoding method into play. This approach involves making predictions at early layers and subsequently performing verification and correction using the remaining layers. By sharing compute and activations between the draft and verification stages, LayerSkip ensures a reduced memory footprint compared to traditional speculative decoding approaches.
Experimental Results
Experimental results demonstrate significant speed enhancements across different LLM sizes and tasks such as summarization, coding, and semantic parsing. LayerSkip achieved speedups on various tasks while maintaining comparable performance to baseline models. The self-speculative decoding approach exhibited notable memory and computational efficiency, facilitating practical deployment of LLMs.
Conclusion
LayerSkip offers a promising solution for enhancing the efficiency of LLMs during inference, minimizing computational and memory overhead. By integrating layer dropout, early exit loss, and self-speculative decoding, researchers have introduced a novel approach that accelerates inference and reduces memory requirements.
For more information, refer to the Paper, explore the Model Series on Hugging Face, and access the GitHub repository.









