
Elon Musk says that AI has already consumed all human-produced data for training
AI requires an enormous amount of resources—from endless water to an estimated $1 trillion in investor dollars—but Elon Musk has warned that the technology has already depleted its primary training resource: human-generated data.
Engineers and data scientists train AI by essentially reducing the entire internet, all books, and every interesting video published into a token that AI can digest and learn from, Musk told Mark Penn, CEO of marketing firm Stagwell, in an interview broadcast on X Wednesday. However, AI has already consumed that information and requires additional data to fine-tune itself.
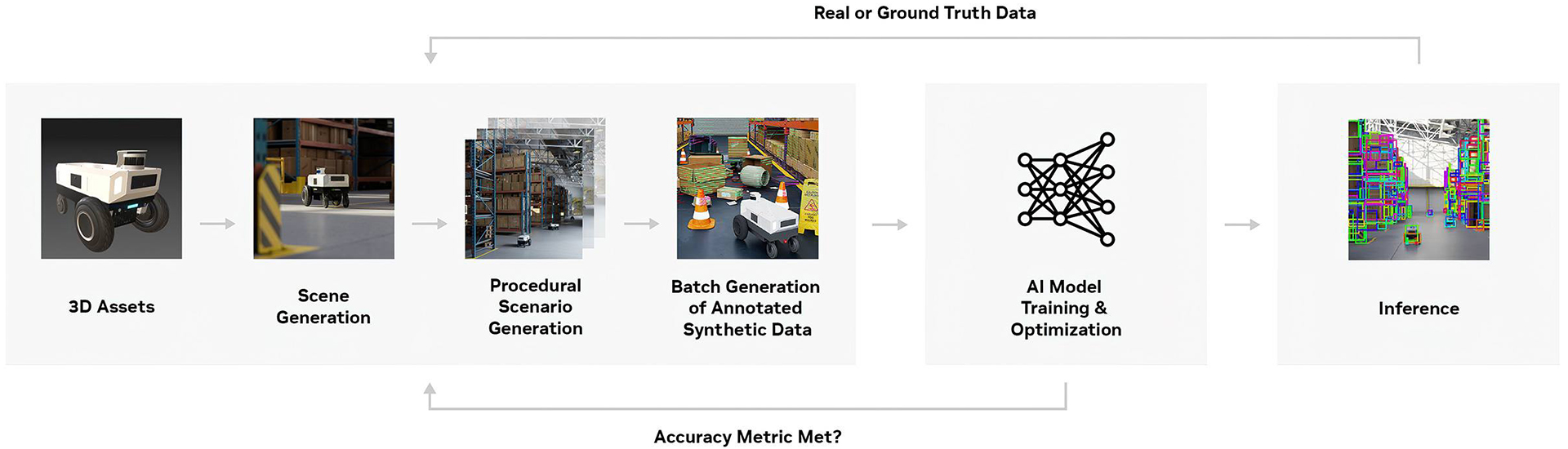
Synthetic Data Training
AI continues to train using synthetic data, which is also generated artificially. Musk compared the process to an AI model writing and grading an essay itself.
Microsoft, Google, and Meta have already used synthetic data to train their AI models. Google DeepMind trained its system Alpha Geometry to solve complex math problems using an artificially generated pool of 100 million unique examples, thus “sidestepping the data bottleneck” of human-generated information. In September, Open AI unveiled o1, an AI model that can fact-check itself.
Concerns and Challenges
Musk acknowledged that the widespread use of synthetic data for model training has drawbacks. Synthetic data usage increases the likelihood of hallucinations, or nonsensical content that AI can share while believing it is entirely true.
These heaps of incomprehensible or simply incorrect information, known as AI slop, have already flooded the internet, alarming tech experts and users. Meta’s president of global affairs, Nick Clegg, said in February that the company is working to identify AI-generated content on its platforms.
Future of AI Training
The limited availability of human-generated data for AI training has become a widely accepted issue in the tech community. However, tech companies are exploring alternative options to overcome this challenge.
Some data scientists have used not only synthetic data, but also private information and agreements with publishers to gain access to their content. According to the New York Times, Open AI even had employees transcribe podcasts and YouTube videos to collect more training data, potentially infringing on copyright laws.
Still, synthetic data remains the future of AI training. CEO Sam Altman stated that as synthetic data production improves, it will help solve the content crisis.
For more information, you can visit the source.









