
DeepSeek-V3 has a problem: it keeps claiming to be ChatGPT ...
AI and large language models are advancing rapidly, with models like ChatGPT, Gemini, Claude, and the latest entrant, DeepSeek-V3, gaining prominence. DeepSeek-V3, an open-source LLM developed by DeepSeek AI in China, has garnered attention for its remarkable performance and cost-effectiveness.
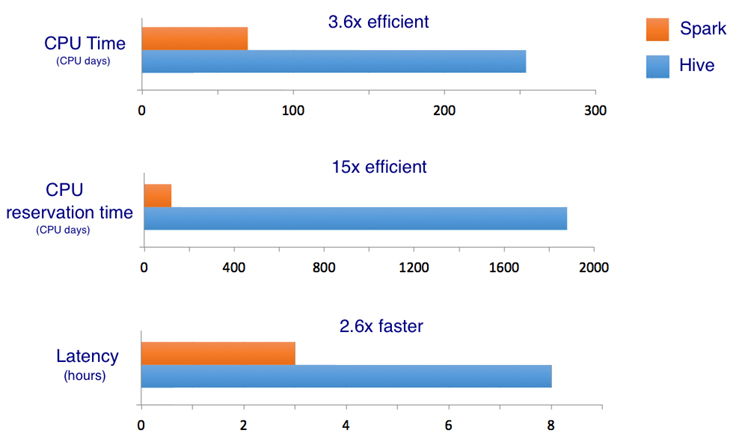
DeepSeek-V3 is equipped with 671 billion parameters, with 37 billion active per token, and the ability to handle context lengths of up to 128,000 tokens. During its training, which spanned approximately two months, the model processed 14.8 trillion tokens using 2.788 million H800 GPU hours, costing around $5.6 million, significantly less than the $100 million spent on training OpenAI's GPT-4.
Despite its impressive capabilities, there seems to be an issue plaguing DeepSeek-V3. Users have observed a peculiar behavior where the model mistakenly identifies itself as ChatGPT. This phenomenon, known as "identity confusion," can have implications for the model's reliability, particularly in critical fields like education and professional services where accurate AI outputs are crucial.
Cause of Identity Confusion
The root of this identity mix-up likely lies in the model's training data. DeepSeek-V3 might have picked up text generated by ChatGPT during its training, leading to the model associating itself with the wrong name. Researchers have delved into this problem, with a recent study indicating that around 25% of proprietary large language models experience similar identity confusion issues.
While this may appear to be a minor glitch, it underscores the importance of ensuring the accuracy and reliability of AI models, especially in applications where trust is paramount.

Please click here for more information on the training data distribution.
The following research paper provides detailed insights into this phenomenon and its implications for large language models.
Stay informed about the latest developments in AI and language models to understand the challenges and advancements in this rapidly evolving field.



















