
Proprietary data, your competitive edge in generative AI | IBM
72% of top-performing CEOs agree that having the most advanced generative AI tools gives an organization a competitive advantage, according to the IBM Institute for Business Value. But if those generative AI tools are not grounded in an enterprise’s unique context, organizations might not get the full benefit from them. As powerful as the big, general-purpose generative AI models such as ChatGPT and Google Gemini are, they aren’t trained on organization-specific data sets. When they’re plugged into an organization’s processes, they might be missing important information that can cause them to get confused and produce suboptimal results.
The Importance of Context
“Every company has its own language,” explains Michael Choie, Senior Managing Consultant, AI and Analytics, IBM Consulting. “Take the word ‘dressing.’ For a grocery chain, that’s going to mean ‘salad dressing.’ For a hospital, that’s going to mean ‘wound dressing.’”
IBM partnered with The Harris Poll to publish AI in Action 2024, a survey of 2,000 organizations across the globe. The survey discovered that 15% of these organizations—called AI Leaders—are achieving quantifiable results with AI.
Customizing AI Efforts
One thing that sets AI Leaders apart is confidence in their ability to customize their AI efforts for optimal value. This doesn’t mean an organization must build its own models from scratch to stand out from the crowd. Instead, it can adapt existing AI models by leveraging the one thing nobody else has: proprietary enterprise data.
“Every AI vendor, such as X or Google, has access to public information. They also have access to data from their own platforms,” explains Shobhit Varshney, Vice President and Senior Partner, Americas AI Leader, IBM Consulting. “What they don’t have access to is your enterprise data. That piece of the puzzle is missing.”
Feeding Proprietary Data to AI Models
There are three primary ways to feed proprietary data to an AI model: prompt engineering, retrieval augmented generation (RAG) and fine-tuning. In this context, prompt engineering means including proprietary data in the prompt that is passed to the AI.
Say that a user wants an AI model to summarize call center conversations. The user can write a prompt—“Summarize this conversation”—and attach the call transcript as part of the prompt.
Retrieval Augmented Generation (RAG)
RAG means hooking an AI model up to a proprietary database. The model can pull relevant information from this database when responding to prompts. For example, an organization can give a customer service chatbot access to a database of company products. When users ask the chatbot questions about these products, it can look at the corresponding documentation and retrieve the correct answer.
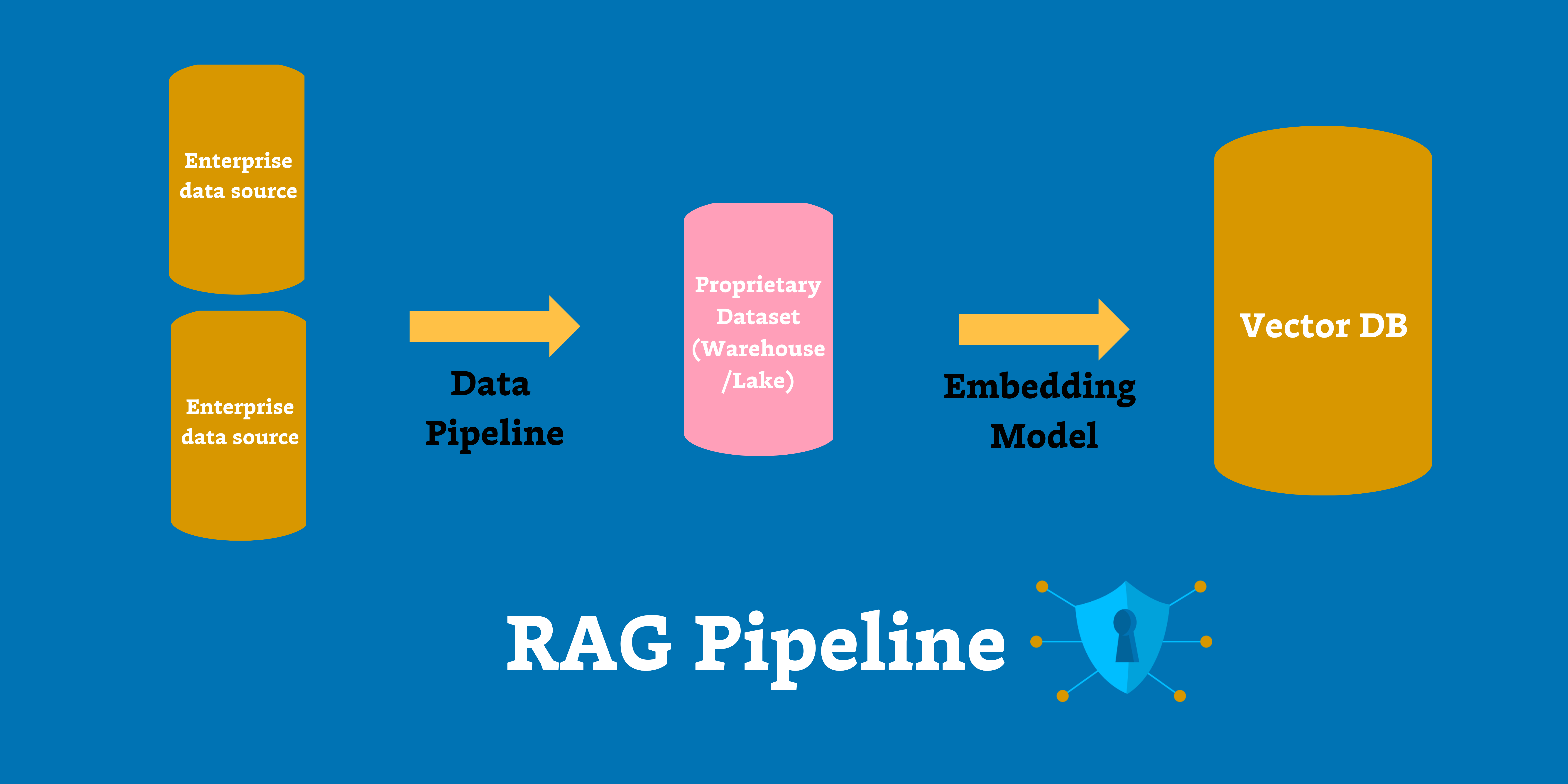
Fine-Tuning
Fine-tuning means giving an AI model enough additional data to change some of its parameters. Fine-tuning permanently changes the behavior of a model, adapting it to a particular use case or context. It’s also faster and cheaper than training a brand-new model.
Advantages of Using Proprietary Data
Using proprietary data in these ways can offer a significant competitive advantage by familiarizing AI models with an enterprise’s unique processes, products, customers and other nuances. When AI models have access to proprietary data, they are grounded in a specific business context, which means their outputs are also grounded in that context.

“I can take an open AI model, fine-tune it with my own proprietary data, and that copy is uniquely mine,” Varshney says. “I own the IP behind it. I run it on my own infrastructure.”
Benefits of Open-Source Models
Organizations can use many different types of AI models to achieve results. But open-source models—such as IBM Granite™ models, which are available under an Apache 2.0 license for broad, unencumbered commercial usage—offer certain benefits.
Effective Data Management for AI
Effective data management is one of the key characteristics that separates AI Leaders from other organizations. Organizations need to ensure the proprietary data they’re feeding to AI models is reliable and accurate.
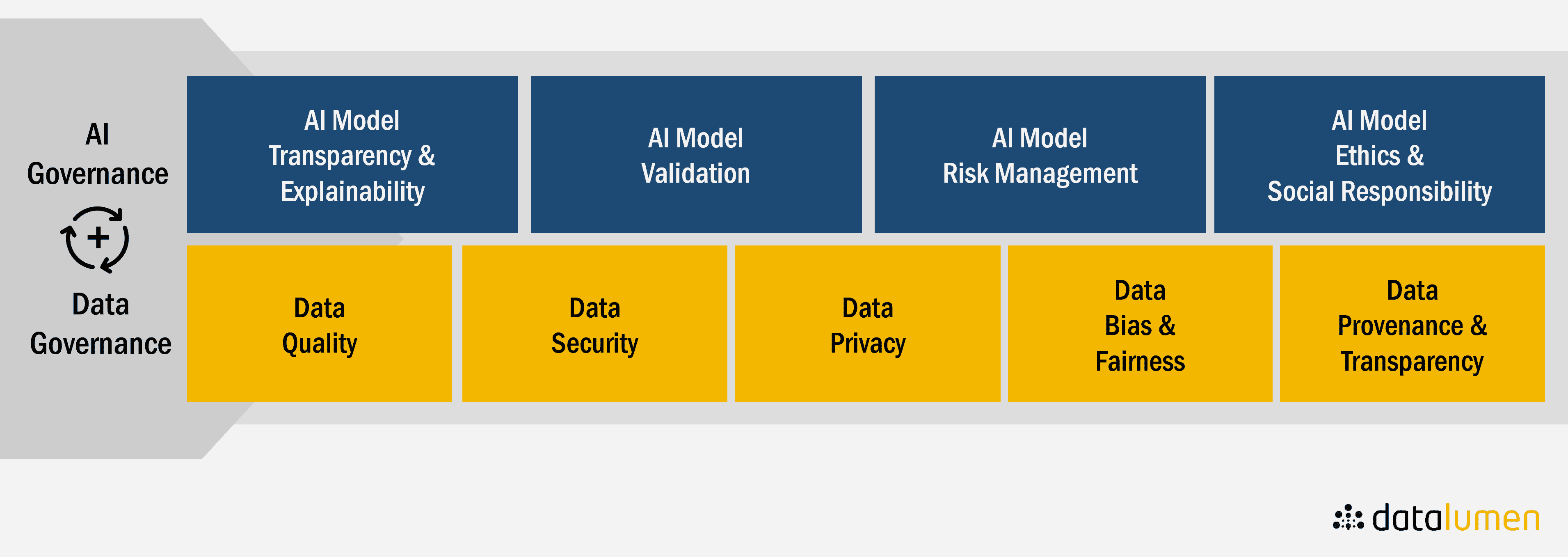
Bad inputs lead to bad outputs. Organizations must ensure the data they feed to AI models is cleaned up and prepared before passing it on. This involves tools such as AI-enabled data management tools, synthetic data generators, and data preprocessing and engineering tools.
Data Integration
In broad terms, the solution is to implement an integrated data fabric that knocks down silos, ensures interoperability and orchestrates fluid data movement across platforms.
Ensuring Data Quality
“You need to figure out the gold in your data—the differentiator—so you can amplify that,” Varshney says. “You want to reduce the noise in the data, and you want to provide high-quality data to fine-tune on.”
Data must be cleaned up before it is passed to an AI. Otherwise, it can make the model perform worse. Data cleaning, preparation, and curation involve tools like data observability tools that can track the flow of data over time, monitor usage, data lineage, and detect anomalies.









