
Microsoft AI Releases OmniParser Model on HuggingFace: A Breakthrough in GUI Automation
Graphical User Interfaces (GUIs) serve as the primary medium for user interaction across various devices, from desktops to mobile phones. While GUIs offer a user-friendly way to engage with digital systems, automating interactions with these interfaces poses a complex challenge. This is especially true when developing intelligent agents capable of understanding and executing tasks based solely on visual cues.
Traditionally, approaches to automated GUI interaction involve parsing underlying HTML structures or view hierarchies, which limit their effectiveness to web environments or situations with accessible metadata. Additionally, existing Vision-Language Models (VLMs) such as GPT-4V encounter difficulties in accurately interpreting intricate GUI components, often leading to incorrect action predictions.
Introducing OmniParser: A Vision-Based Solution
To address these challenges, Microsoft has launched OmniParser, a revolutionary vision-based tool designed to enhance current screen parsing methodologies. This innovative model, accessible on Hugging Face, marks a significant advancement in intelligent GUI automation.
One of the key strengths of OmniParser is its ability to bridge existing gaps in screen parsing techniques without relying on supplementary contextual information. By focusing solely on visual input, OmniParser offers a more sophisticated understanding of GUI elements across different platforms, including desktops, mobile devices, and the web.
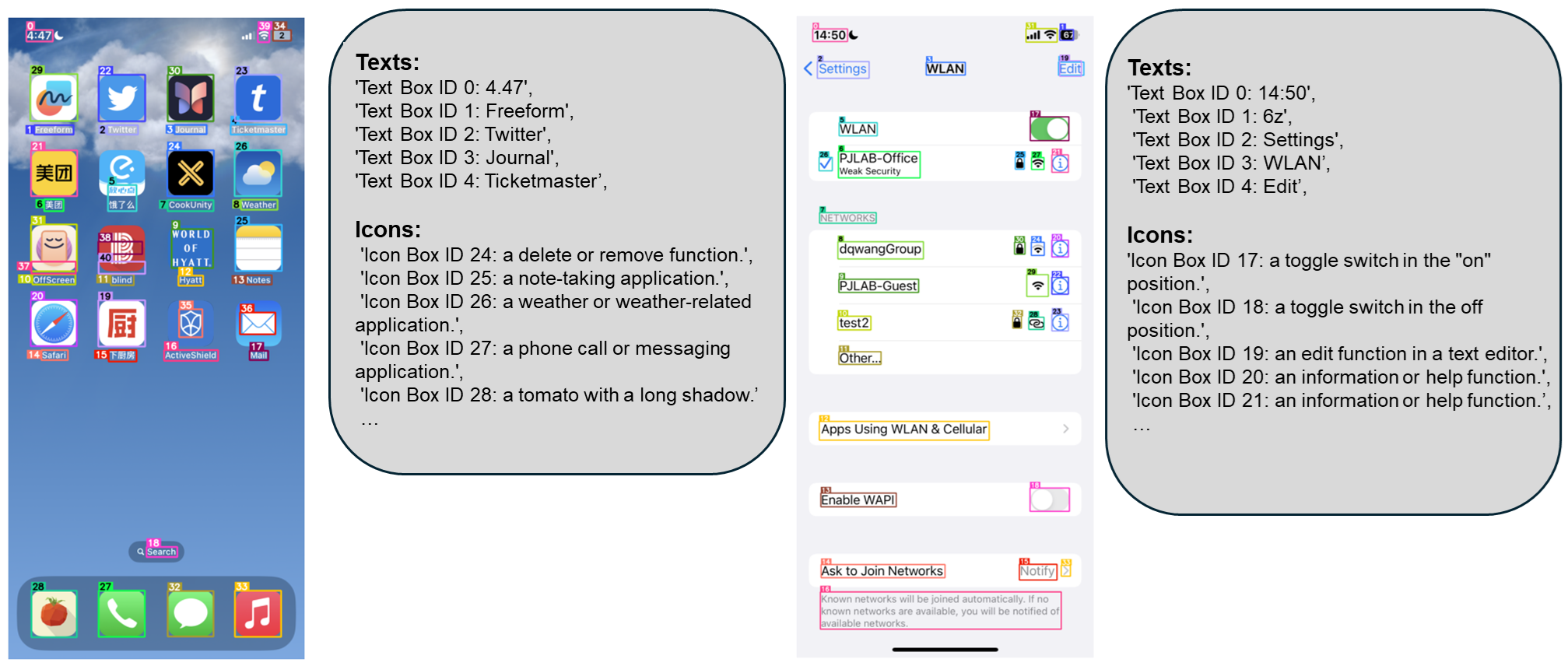
The Technology Behind OmniParser
OmniParser incorporates several specialized components to achieve robust GUI parsing capabilities. These include a fine-tuned interactable region detection model, an icon description model, and an OCR module. The region detection model identifies actionable elements like buttons and icons on the UI, while the icon description model captures the functional semantics of these elements. Additionally, the OCR module extracts text elements from the screen, collectively providing a structured representation directly from visual input.
One notable feature of OmniParser is its overlay of bounding boxes and functional labels on the screen. This visual guidance aids language models in generating more precise predictions regarding user actions, eliminating the need for external data sources. This approach proves particularly beneficial in environments lacking accessible metadata, expanding the model's applicability across different use cases.
Advancements and Performance
OmniParser represents a significant advancement in GUI automation by offering a vision-only solution capable of parsing diverse UI types, independent of underlying architectures. This versatility ensures improved cross-platform usability, catering to both desktop and mobile applications. Performance benchmarks across various datasets demonstrate OmniParser's effectiveness, showcasing notable enhancements over baseline GPT-4V setups.

For instance, on the ScreenSpot dataset, OmniParser achieved an accuracy boost of up to 73%, surpassing models reliant on HTML parsing methods. By leveraging local semantics of UI elements, OmniParser significantly enhanced predictive accuracy, with GPT-4V's correct labeling of icons improving from 70.5% to 93.8% when utilizing OmniParser's outputs.
Empowering Intelligent GUI Agents
Microsoft's OmniParser marks a critical advancement in developing intelligent agents capable of interacting with GUIs. By emphasizing vision-based parsing, OmniParser eliminates the need for auxiliary metadata, making it a versatile tool for diverse digital environments. This enhancement not only extends the usability of models like GPT-4V but also lays the foundation for creating more adaptable AI agents across various digital interfaces.

With the release of OmniParser on Hugging Face, Microsoft has democratized access to cutting-edge technology, empowering developers with a potent tool to build smarter and more efficient UI-driven agents. This strategic move opens up new avenues for applications in accessibility, automation, and intelligent user assistance, propelling the potential of multimodal AI to unprecedented heights.
Explore the paper for further insights and details. Dive into the full details of OmniParser, and try out the model here.









