
Import wizards in Azure portal - Azure AI Search | Microsoft Learn
This browser is no longer supported. Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support. Azure AI Search has two import wizards that automate indexing and object definitions so that you can begin querying immediately. If you're new to Azure AI Search, these wizards are one of the most powerful features at your disposal. With minimal effort, you can create an indexing or enrichment pipeline that exercises most of the functionality of Azure AI Search.
Import data wizard
The Import data wizard supports nonvector workflows. You can extract alphanumeric text from raw documents. You can also configure applied AI and built-in skills that infer structure and generate text searchable content from image files and unstructured data.

Import and vectorize data wizard
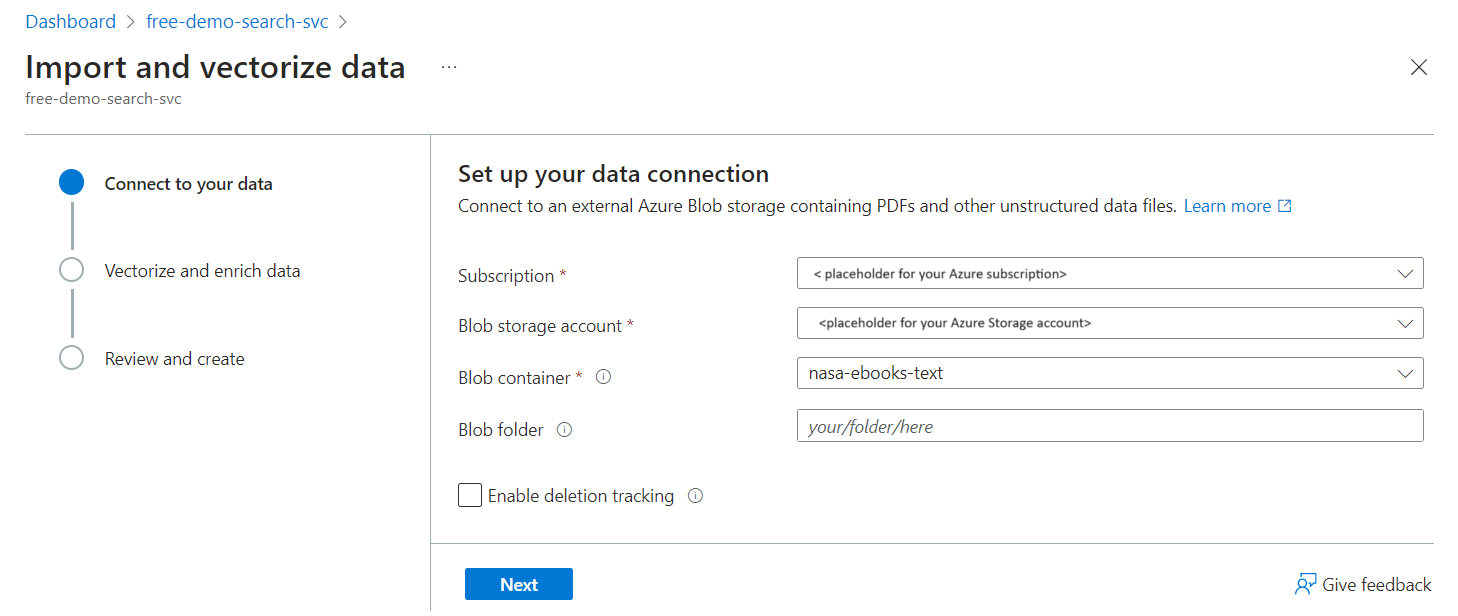
The Import and vectorize data wizard supports vectorization. You must specify an existing deployment of an embedding model, but the wizard makes the connection, formulates the request, and handles the response. It generates vector content from text or image content. If you're using the wizard for proof-of-concept testing, this article explains the internal workings of the wizards so that you can use them more effectively.
Sampling and Limitations
Sampling is the process by which an index schema is inferred, and it has some limitations. When the data source is created, the wizard picks a random sample of documents to decide what columns are part of the data source. Not all files are read, as this could potentially take hours for very large data sources. Given a selection of documents, source metadata, such as field name or type, is used to create a fields collection in an index schema.
Overall, the advantages of using the wizard are clear: as long as requirements are met, you can create a queryable index within minutes. Some of the complexities of indexing, such as serializing data as JSON documents, are handled by the wizard.
The wizard isn't without limitations. Constraints are summarized as follows:
- The wizard doesn't support iteration or reuse. Each pass through the wizard creates a new index, skillset, and indexer configuration. Only data sources can be persisted and reused within the wizard.
- Source content must reside in a supported data source.
- Sampling is over a subset of source data. For large data sources, it's possible for the wizard to miss fields.
Data Source Inputs
The wizards connect to an external supported data source using the internal logic provided by Azure AI Search indexers, which are equipped to sample the source, read metadata, crack documents to read content and structure, and serialize contents as JSON for subsequent import to Azure AI Search. Not all preview data sources are guaranteed to be available in the wizard.
You can paste in a connection to a supported data source in a different subscription or region, but the Choose an existing connection picker is scoped to the active subscription.
Skillset Configuration
Skillset configuration occurs after the data source definition because the type of data source informs the availability of certain built-in skills. The wizard adds the skills you choose. It also adds other skills that are necessary for achieving a successful outcome.
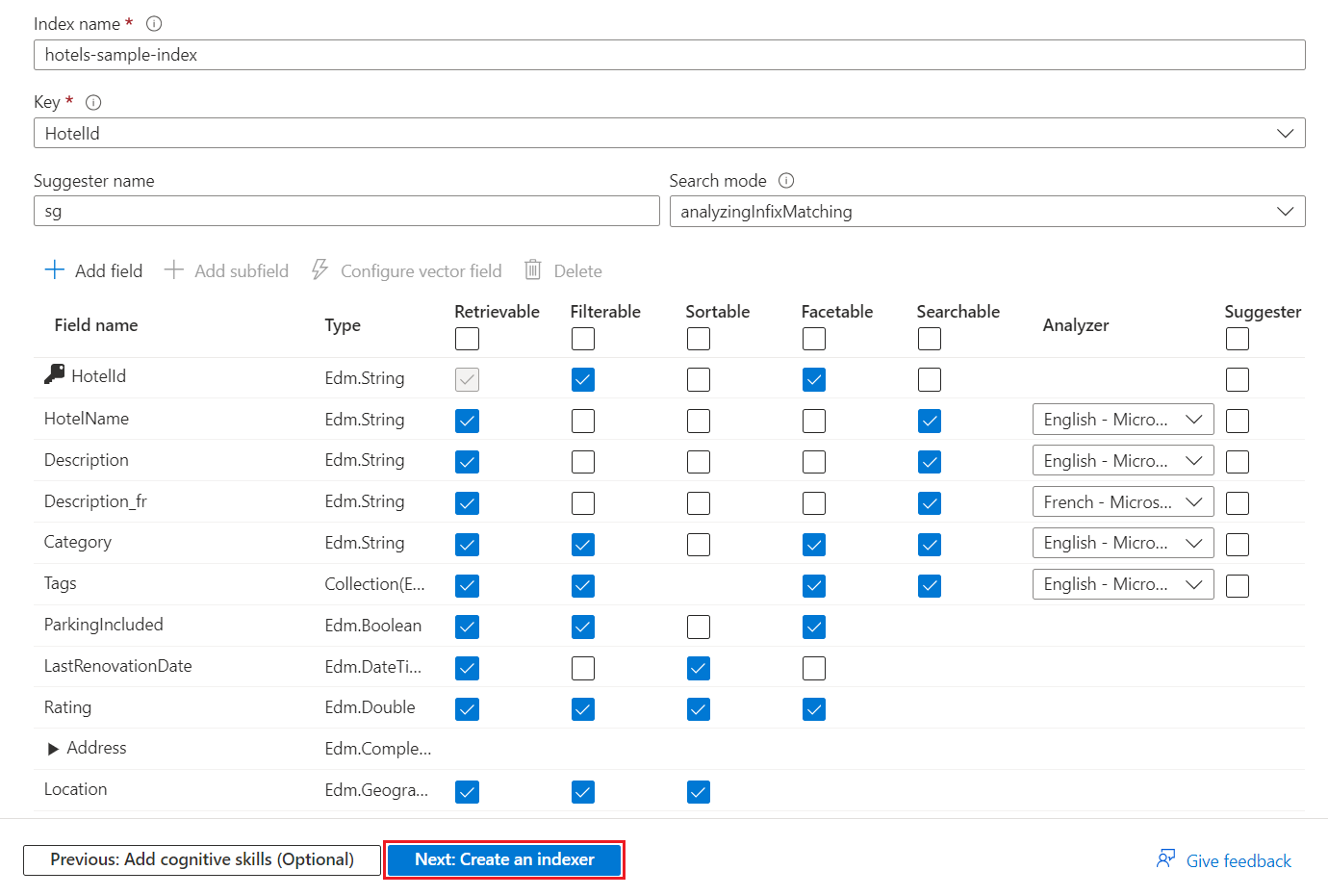
Index Definition
The wizards sample your data source to detect the fields and field type. Depending on the data source, it might also offer fields for indexing metadata. Take your time with this step because the accuracy of the index schema is crucial for the search experience.
Because sampling is an imprecise exercise, review the index for the following considerations:
- Is the field list accurate?
- Is the data type appropriate for the incoming data?
- Do you have one field that can serve as the key?
Set attributes to determine how that field is used in an index.









