
DeepSeek R1: The Real Worry Behind R1 and Other Tools - Serious ...
I haven’t written about DeepSeek R1 because I’ve spent most of my time commenting on it via podcasts and phone calls. I’ve been asked, “Why now?” The answer to that is Apple downloads. Had DeepSeek not piqued a viral curiosity streak, the newly minted foundations of the AI establishment would not have shaken so quickly. I was not surprised by the event but disappointed in the timing.
AI fatigue comes not just from learning and interacting with so many tools; it also comes from an overwhelming sense of intense fluidity. Those who are not agile thinkers (we have an answer for that here) can get bound very quickly in a new reality and struggle to realign when that reality meets a disruption. R1’s release clearly shook some people. Stock prices for several well-established AI firms took a hit almost immediately. It remains to be seen if the market reaction was merely a knee-jerk response to something new or if the market knows something substantive. At this point, I’m leaning toward knee-jerk because most investors don’t understand AI. The reaction came from the cost models, not the knowledge models.
The Impact of DeepSeek R1
Let me back up for those who have not been keeping up with the AI news cycle. Those in the news cycle think everyone is paying attention, but they are not. This week, DeepSeek dropped R1, which caused consternation among those in the AI community to whom reality has become big data-driven machine learning built from across the webs, light and dark, powered by massive, energy-gnawing computing centers. DeepSeek claims to be able to train a model at a fraction of the cost of those associated with Open AI, Meta or Anthorpic. R1, a new large language model, is the result of seemingly secretive development in China funded quietly by a mix of private investors and corporate partnerships.
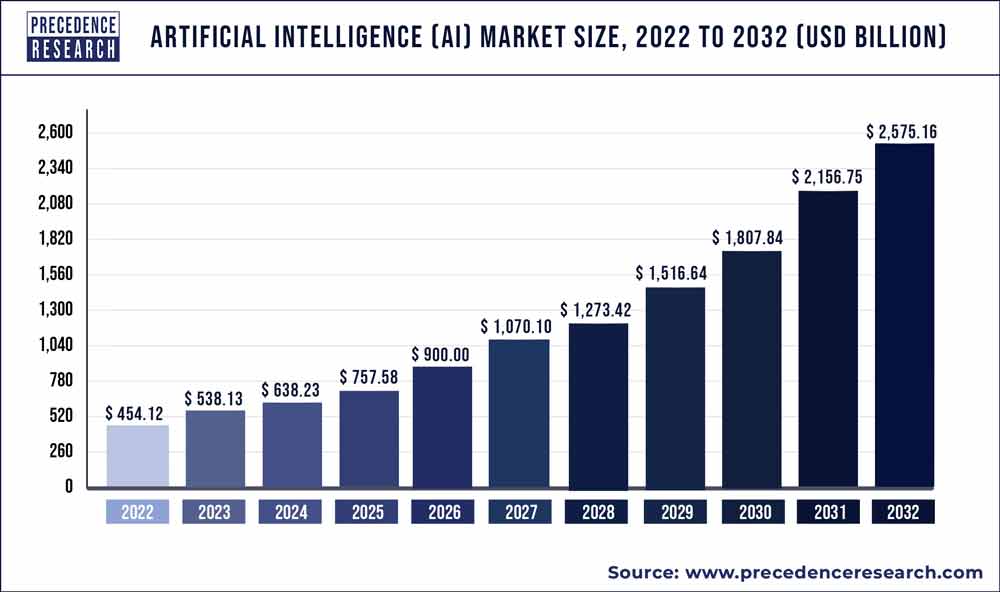
While many see R1 as a quantum leap forward—delivering not just faster response times but higher accuracy and more nuanced reasoning—others wonder if it is as special as it appears.
Challenges and Skepticism
First, the public model, not the open-source version, is heavily censored in favor of the Chinese version of history and reality; that will create a level of skepticism as organizations test DeepSeek R1’s edges. Second, the cost of computing comes from training, not using AI. Enterprises that want to leverage existing AI systems, open source or commercial, pay less for queries compared to training, with some of the training costs baked into the consumption costs. While it may cost less to train the model, most businesses aren’t training models. Now, for the big players, R1 challenges their assertions about reality, which gets back to me not being surprised. The current models are unsustainable. A new approach was going to appear at some point that would undermine the assumptions about training, energy and processor farms. Even if the R1 story isn’t as pure as it seems on the surface, it challenges the current narrative, which isn’t good for marketing or credibility for U.S. AI executives.

Third, the claims may be overstated. My first inclination was that DeepSeek R1 must have used preprocessed data, which would push the cost back to the preprocessed data and away from the accounting related to the foundation model. Pre-GRPO (Group Relative Policy Optimization) pipeline finetuning likely accounts for some of the apparent gains.
Future Implications
Fourth, open source is not a panacea. Companies that adopt open source will need to implement internal governance, deal with skill shortages, develop approaches to integrated enterprise content and many other activities that many may not be able to afford, and for those who can afford it, the acquisition of talent, internally or outsourced, will constrain the total available bandwidth to develop high-quality AI-based applications.
If R1 is an evolutionary revolution (because it is clearly not new new) it has the following implications: The other AI service providers will likely emulate DeepSeek’s training process both as a test of its assertions and as a learning tool for their own work. DeepSeek should be treated as a scientific test that requires others to prove that the solution is repeatable. AI plays a critical role in that it has created a very rapid software development cycle, which means between coding and abbreviated training, it could be a matter of weeks before we see R1-like models coming from Open AI, Anthropic and Meta. My guess is the large AI service providers will offer alternative models, as they already do, with their more richly trained and layered models adding step functions to existing systems. Hugging Face has announced Open-R1, an attempt to reverse engineer DeepSeek’s approach. As Hugging Face and others deconstruct DeepSeek R1, they will leverage its advantages and point out its deficiencies. This will result in marketing shifts that take a more offensive posture that differentiates approaches from DeepSeek and other emergent models.
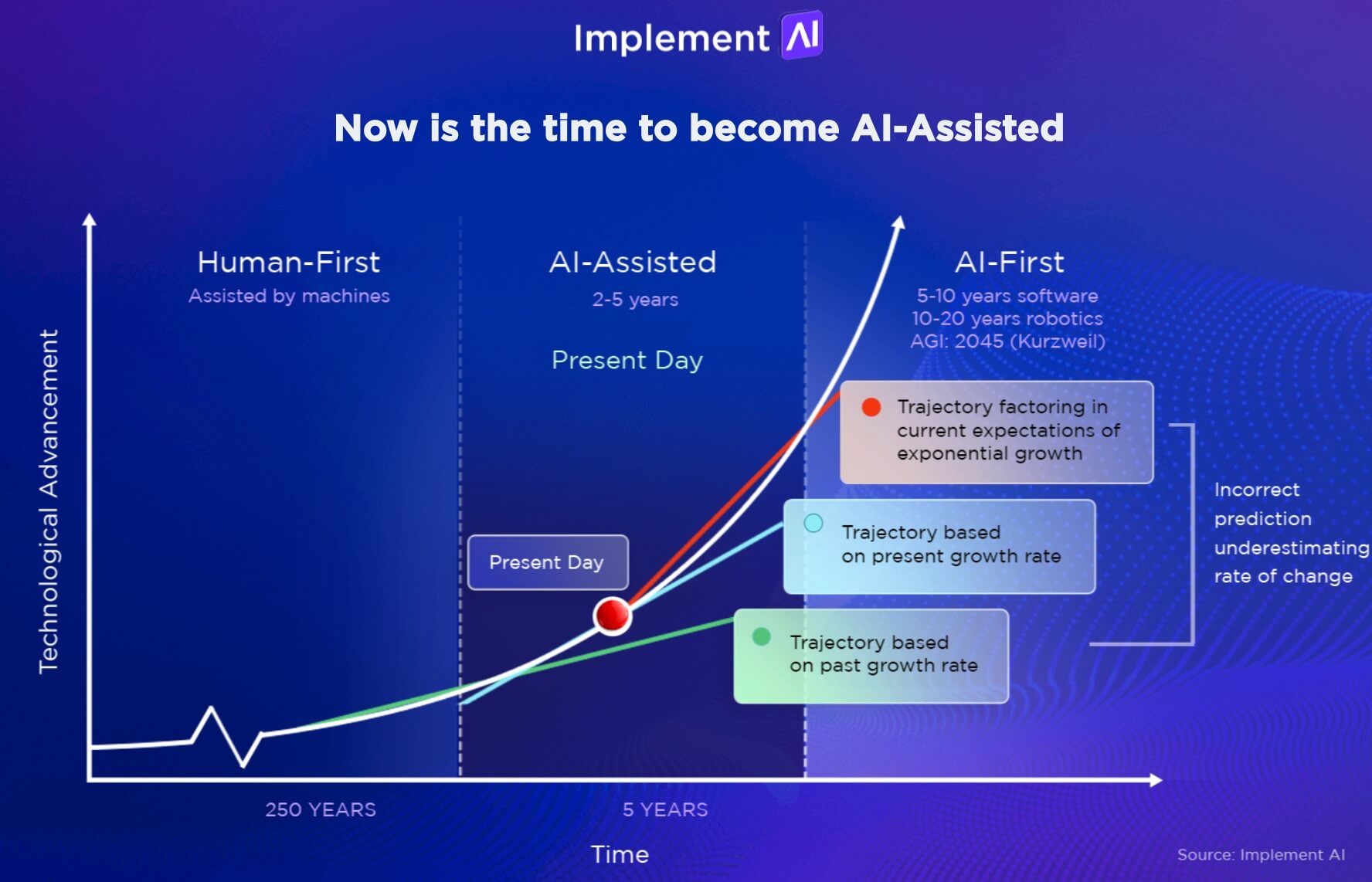
The AI market remains nascent. It may be the first market to eschew the idea of maturity as a market and as a technology. I’m guessing this isn’t the only disruption of 2025. All the AI service providers have been trying to one-up each other since the beginning. Other concepts and ideas will drop that will further challenge assumptions or perhaps double down on proof points. The biggest lesson for R1 is that we can’t assume stability in the AI market. The AI market remains nascent. It may be the first market to eschew the idea of maturity as a market and as a technology.
For more serious insights on AI, click here.
Copyright 2009-2025 Serious Insights LLC



















