
From Concept to Code: Unveiling the ChatGPT Algorithm | Towards AI
For the past two years, ChatGPT and Large Language Models (LLMs) in general have been the big thing in artificial intelligence. Many articles about how-to-use, prompt engineering, and the logic behind have been published. Nevertheless, when I started familiarizing myself with the algorithm of LLMs — the so-called transformer — I had to go through many different sources to feel like I really understood the topic.
In this article, I want to summarize my understanding of Large Language Models. I will explain conceptually how LLMs calculate their responses step-by-step, go deep into the attention mechanism, and demonstrate the inner workings in a code example.
1.1 Introduction to Transformers
Tokens are the basic building blocks for text processing in Large Language Models. The process of splitting text into tokens is called tokenization. Depending on the tokenization model, the received tokens can look quite different. Some models split text into words, others into subwords or characters. Tokenization models also include punctuation marks and special tokens like <start> and <stop> for controlling the LLM's output to a user interaction.
The basic idea of tokenization is to split the processed text into a potentially large but limited number of tokens the LLM knows.
1.2 Tokenization
Fig. 1.2.1 shows a simple example. The context "Let’s go in the garden" is split into the seven tokens "let", "‘", "s", "go", "in", "the", "garden". These tokens are known to the LLM and will be represented by an internal number for further processing.
1.3 Word Embedding
Word embedding translates tokens into large vectors with usually several hundred or several thousand dimensions. The higher the embedding depth, the more information the embedding can capture.
In Fig. 1.3.1, the tokenizer has split the sentence "Let’s go in the garden" into tokens, and the word embedding translates these tokens into vectors.
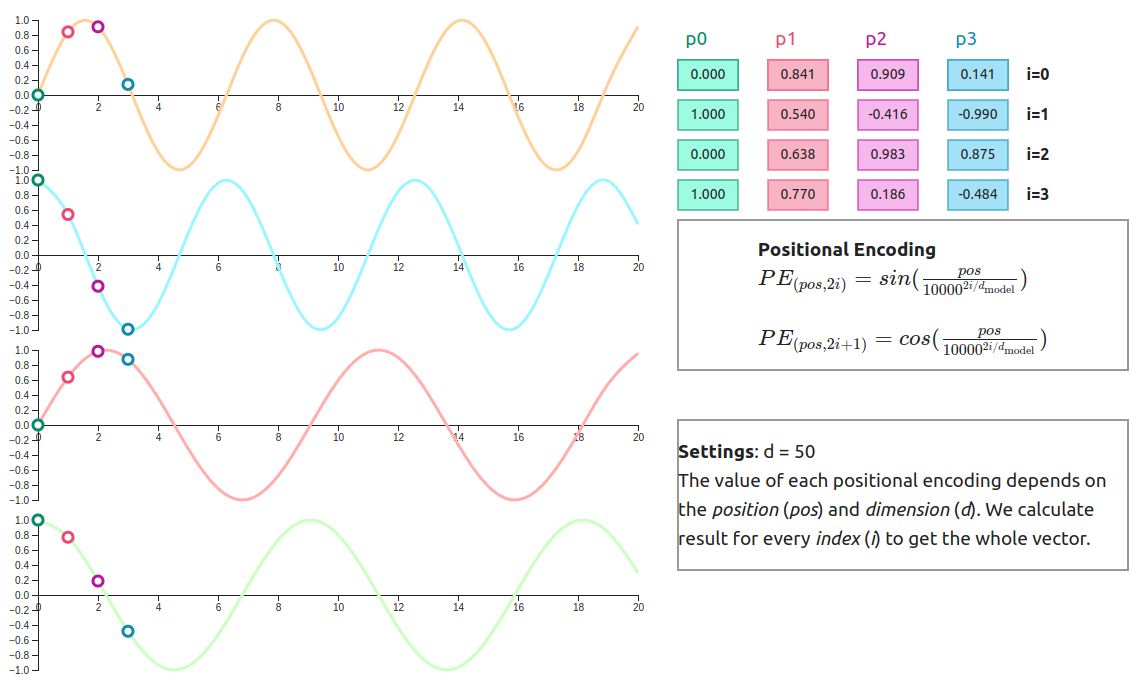
1.4 Positional Encoding
Positional encoding is used to specify the position of the token in the context. It adds a vector of the same size as the word embedding to each embedding vector.
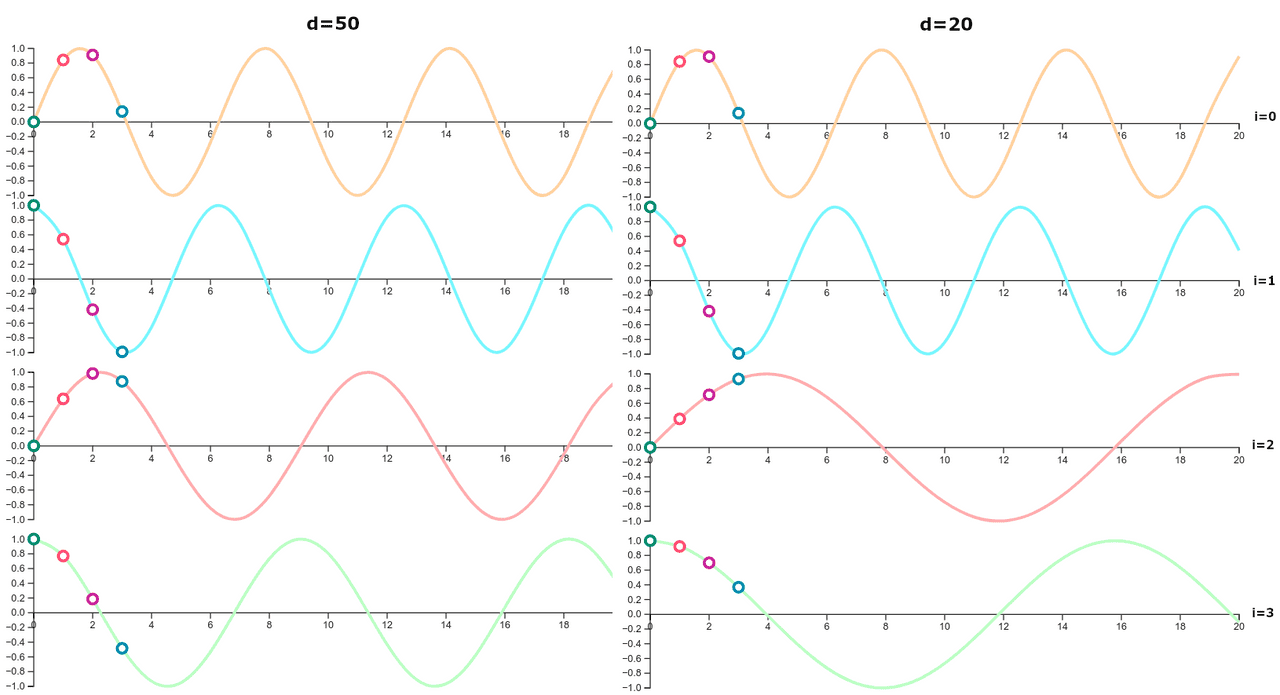
Fig. 1.4.1 continues the example of "Let’s go in the garden" by showing positional vectors added to each token.
1.5 Attention Mechanism
The attention mechanism is the heart of the transformer and is the main reason why ChatGPT is so good at language processing. It revolves around the concept of "context".
We will dive deeper into the attention mechanism and other key components in the upcoming sections.
...My personal impression is that the way positional vectors are calculated is less important for the performance of a transformer. However, it is crucial to use positional encoding, no matter how the vectors have been calculated.
1.6 Layer Norm
The layer normalization process in transformers.
1.7 Feed Forward
Explaining the feed-forward mechanism in transformers.
1.8 Softmax
Understanding the softmax function in the context of transformers.
1.9 Multinomial
Discussing the multinomial distribution in transformer models.
Stay tuned for the upcoming sections where we will delve into the data preparation, attention heads, model training, and more.









