
Evaluating LLMs — What's the right one for the job?
LLMs move so fast. Have you noticed? One minute Open AI’s on top, then Google Gemini, nope wait — now it’s Anthropic. How do you keep up? And perhaps more importantly, how do you pick the right LLM for the job? It’s a tricky business!
At Humaxa we dynamically choose an LLM based on several factors including:
- Answer Quality
- Hallucination Rate
- Hallucination Rate
- Performance
- Response speed
- Cost

Perhaps our criteria could help you decide as well. We generate a report including each metric from above with scores that can be used to compare LLMs. This tool can then be incorporated into automated processes using a simple API (Application Programming Interface).
Why dynamically choose an LLM?
It’s like having an army of people ready to work at your company. Some are good at computer programming. Some are good at conversing with customers and understanding their needs. Others are good at getting a large group of people to come to consensus on a critical matter. You need all of them at one point or another, but they shine in different situations. LLMs are a lot like that.
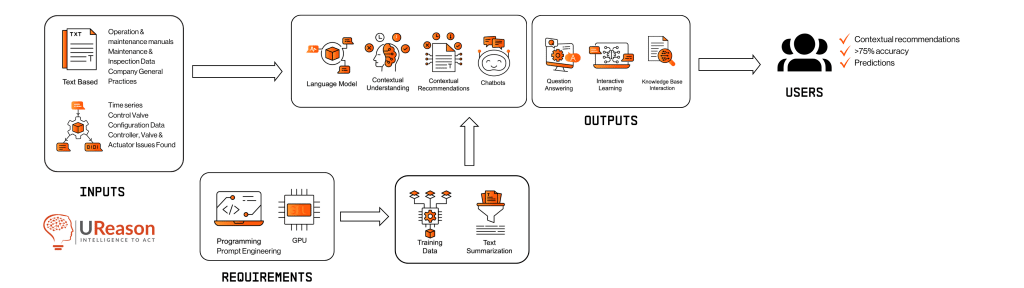
Testing Inputs
What are your inputs to test? You would need:
- Prompt-Response Samples: A list of questions and answers that are considered correct or appropriate.
- Subject LLM Endpoint: The API by which the LLM to be tested can be accessed.
- Evaluator LLM Endpoint: The API by which the evaluating LLM can be accessed.
- Iterations: How many times should the exam be performed? A high number of repetitions prevents outlier performances from skewing the score.
- Callback Endpoint: Since the testing process is lengthy and time consuming, the evaluator needs an endpoint to call with the results once the process is completed.
Evaluation Process
An evaluation should be performed once for each iteration, and consists of the following processes:
For each prompt-response pair:
- Call the Subject LLM with the prompt. Measure response time and output length.
- Call the Evaluator LLM with the response given by subject, asking it to evaluate if the answer given matches the expected response sufficiently. This is a Pass/Fail test.
- Call the Evaluator LLM once more, this time asking it to grade the answer using an A-to-F grade system. This is a quality indicator.
Evaluation Outputs
What would the outputs be?
- Accuracy: Number of passed tests divided by total tests performed
- Quality: Average grade
- Response Time Per Token: An average measure of performance
- Outliers: Additionally, the tool will provide a list of prompts that have over or under-performed relative to the norm
Have you been thinking about how to dynamically choose an LLM? What decision criteria do you use? We'd love to hear your thoughts! And if you’re looking to implement such a tool on your own and you’re looking for help, don’t hesitate to reach out.
Humaxa









