
[AINews] DeepSeek's Open Source Stack • Buttondown
This is AI News! an MVP of a service that goes thru all AI discords/Twitters/reddits and summarizes what people are talking about, so that you can keep up without the fatigue. Signing up here opts you in to the real thing when we launch it. Cracked engineers are all you need. AI News for 3/7/2025-3/8/2025. We checked 7 subreddits, 433 Twitters and 28 Discords (224 channels, and 4696 messages) for you. Estimated reading time saved (at 200wpm): 406 minutes. You can now tag @smol_ai for AINews discussions!
We didn't quite know how to cover DeepSeek's "Open Source Week" from 2 weeks ago, since each release was individually interesting but not quite hitting the bar of generally useful and we try to cover "the top news of the day". But the kind folks at PySpur have done us the favor of collating all the releases and summarizing them:

It even comes with little flash quizzes to test your understanding and retention!!
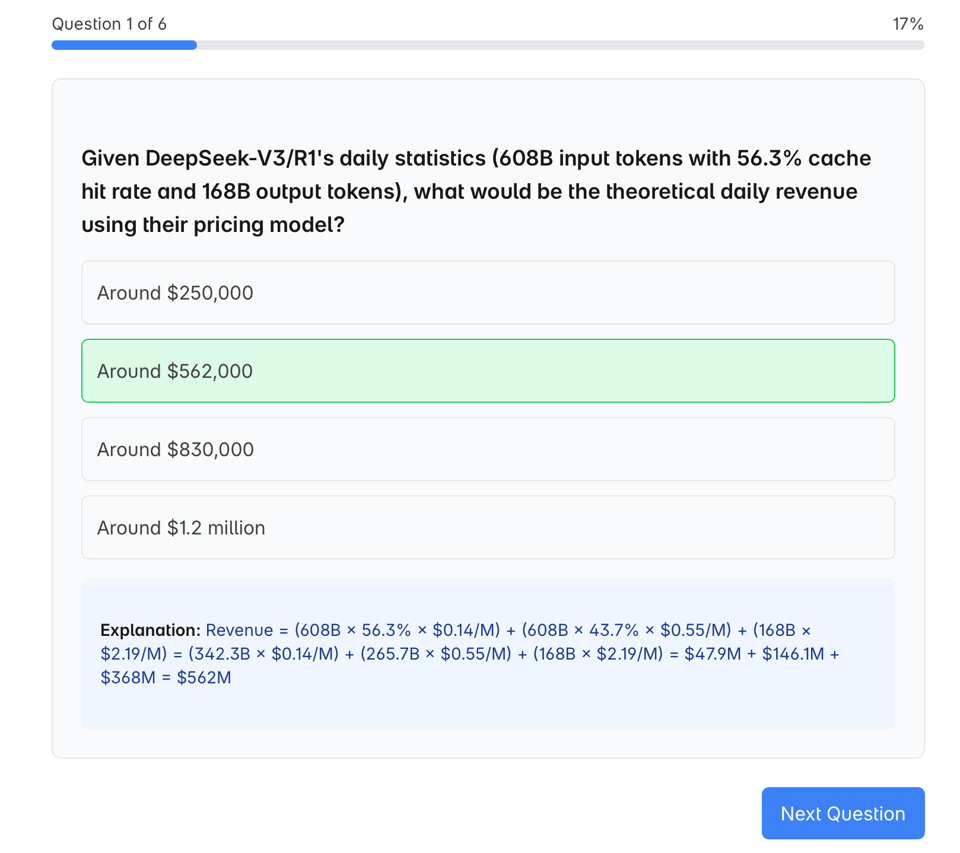
We think collectively this is worth some internalization.
Table of Contents
Models & Releases
Tools & Applications
Research & Datasets
Industry & Business
Opinions & Discussions
Humor & Memes
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCodingerror in pipeline that we are debugging... sorryA summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. FT: Llama 4 w/ Voice Expected Soon, Enhancing Voice AI
Theme 2. QwQ-32B Performance Settings and Improvements
Theme 3. QwQ vs. qwen 2.5 Coder Instruct: Battle of 32B
Theme 4. Meta's Latent Tokens: Pushing AI Reasoning Forward
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCodingerror in pipeline that we are debugging... sorryA summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. IDE Showdown: Cursor, Windsurf, and the Code Editor Arena
Theme 2. Model Benchmarks and Optimization Breakthroughs
Theme 3. Diffusion Models Disrupt Language Generation
Theme 4. MCP and Agent Security Threats Loom Large
Theme 5. Hardware Hustle: 9070XT vs 7900XTX and Native FP4 Support
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCodingerror in pipeline that we are debugging... sorryA summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. FT: Llama 4 w/ Voice Expected Soon, Enhancing Voice AI
Theme 2. QwQ-32B Performance Settings and Improvements
Theme 3. QwQ vs. qwen 2.5 Coder Instruct: Battle of 32B
Theme 4. Meta's Latent Tokens: Pushing AI Reasoning Forward
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCodingerror in pipeline that we are debugging... sorryA summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. IDE Showdown: Cursor, Windsurf, and the Code Editor Arena
Theme 2. Model Benchmarks and Optimization Breakthroughs
Theme 3. Diffusion Models Disrupt Language Generation
Theme 4. MCP and Agent Security Threats Loom Large
Theme 5. Hardware Hustle: 9070XT vs 7900XTX and Native FP4 Support
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCodingerror in pipeline that we are debugging... sorryA summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. FT: Llama 4 w/ Voice Expected Soon, Enhancing Voice AI
Theme 2. QwQ-32B Performance Settings and Improvements
Theme 3. QwQ vs. qwen 2.5 Coder Instruct: Battle of 32B
Theme 4. Meta's Latent Tokens: Pushing AI Reasoning Forward
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCodingerror in pipeline that we are debugging... sorryA summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. IDE Showdown: Cursor, Windsurf, and the Code Editor Arena
Theme 2. Model Benchmarks and Optimization Breakthroughs
Theme 3. Diffusion Models Disrupt Language Generation
Theme 4. MCP and Agent Security Threats Loom Large
Theme 5. Hardware Hustle: 9070XT vs 7900XTX and Native FP4 Support
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
Cursor vs Lmarena, Cursor 0.47, Claude 3.7, Grok struggles, vibe coding GPU memory management for training large models, ktransformers IQ1 benchmarks, QwQ-32B optimizations and best practices, GRPO algorithm optimizations RLHF with Unsloth GRPO on Qwen7b, Qualitative vs Quantitative Improvement, Reward Model Bias, KL Divergence Issues, Qwen for Sudoku RAM Configuration for Mac Studio, ktransformers Performance, RoPE Scaling, Custom Datasets, Multi-GPU Parallelism with Unsloth
Link mentioned: unslothai/unsloth: Finetune Llama 3.3, DeepSeek-R1 & Reasoning LLMs 2x faster with 70% less memory! 🦥 - unslothai/unsloth
Diffusion Effect, Rust Code, Deepseek Coder v2, Unsloth and MoE Registry Editing Risks, Quantization impact on RAM and VRAM, File path limitations on windows, Trustless authentication, Diffusion-based language models IDE Telemetry Settings, Codeium Website Payment Updates Windsurf stability issues, Credit consumption, Cascade problems, Model performance comparison (Cursor vs. Windsurf), MCP server issues Perplexity Pro Account Issues, GPT-4.5 Usage, Commercial Use of Perplexity and Copyright, Sonnet 3.7 Extended Performance, Perplexity Mobile App and Claude Apple Foldable iPhone, OpenAI AI Agent, Amazon Prime AI Dubbing, DuckDuckGo AI Search LM Studio 0.3.12, QwQ template bug fixes, RAG chunking speed improvement
Link mentioned: LM Studio 0.3.12: Bug fixes and document chunking speed improvements for RAG
Open Source LLM for Coding on M2 Macbook Pro, DeepSeek v2.5 1210, Qwen Coder, Finetuning Large Language Models, Context Length and Memory Management 9070XT vs 7900XTX, ROCm and Vulkan performance, Native FP4 support, CodeGPT extension issues on WSL, Quantization impact on model quality Open Source Alternatives to Replit/Bolt, Gradio Dexie Wrapper Proposal, Obsidian user is from Obsidian, Suspecting Dataset Misuse in Research Papers, Hugging Face Datasets and DOI Generation HF Docker Repository, fxtwitter
Link mentioned: OpenStreetMap AI Helper - a Hugging Face Space by mozilla-ai: no description found
Downloads, Community Appreciation OCR-2.0 Guidance Smol Agents Course, Pokemon LLM Agent Benchmark, HuggingFace Token issues Course Start Dates, LLM as Agent Component, RAG as Environment, Course Completion Status, Image Generation Troubles Perplexity API copyright issues, OpenRouter latency with Anthropic API, Groq provider in OpenRouter, Gemini embedding model, Testing reasoning parameter in OpenRouter models Minion.ai, Gemini Embedding Model, Claude code vs cursor.sh vs VSCode+Cline Web3 Agents, ElizaOS framework, AI Personas, Agent-as-a-Service, CryptoKitties ChatGPT token limits, Share GPS with AI, Local LLMs, AI copilots for skilled trades, Temporary chat box

Link mentioned: AI Copilot Technical Manuals: no description found
Manus AI Agent, OpenAI Plus O1 Limits, SimTheory O1 Message Cap, ChatGPT Memory and Folders Model Following Request Patterns, Steerability Implications, Pre-Project Evaluation Model's Presumptions, Steerability Impact, Pre-Project Evaluation, Method Optimization Aider showing reasoning, Jamba model release, AI-written code, Copilot account suspension, Claude token consumption API Key for Aider, MCP Agents Integration, Playwright Certificate Errors, QwQ-32B Local Model Benchmark, Aider Scripting and Web Content LinkedIn premium referral codes, Entropy as a Penalty, DeepSeek Ban, Discrete Diffusion Modeling Latent Reasoning, Chain-of-Thought Data, Context Compression, VQ-VAE
Link mentioned: Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning: Large Language Models (LLMs) excel at reasoning and planning when trained on chain-of-thought (CoT) data, where the step-by-step thought process is explicitly outlined by text tokens. However, this res...
Diffusion Models Hallucinations, Multi-step Agentic Workflows, LLADA Limitations, OpenAI's AGI shift, Chinese AI Agent Manus MCP security concerns, MCP adoption in commercial products, Malicious prompt injections, MCP and GitHub Copilot, Open Source vs Closed Source MCPs
Link mentioned: For Client Developers - Model Context Protocol: no description found
Mastra Agent, Searxng MCP Server, Typescript port of the python fetch server Mojo's Dynamism, Python Interop, Monkey Patching Alternatives, Protocol Polymorphism SOTA agentic methods, Arxiv papers, algorithm complexity, state machines, framework abstractions Triton Autotune use_cuda_graph argument, Triton Kernel SVD Quant Performance, Nunchaku SVD Quant Implementation PTX, CUDA C++ Distributed barrier, cuda synchronize, register_comm_hook, FSDP communication hook
Link mentioned: Added communication hook for sharded cases by aovladi · Pull Request #83254 · pytorch/pytorch: Fixes #79114An implementation of a FSDP communication hook interface for a sharded strategies:Added reduce_scatter_hook to default hooks. Note the difference of reduce_scatter from all_reduce, i...
NCCL AllReduce, Double Binary Trees, Ring Topology, Communication Latency
Link mentioned: Massively Scale Your Deep Learning Training with NCCL 2.4 | NVIDIA Technical Blog: Imagine using tens of thousands of GPUs to train your neural network. Using multiple GPUs to train neural networks has become quite common with all deep learning frameworks, providing optimized…
WoolyAI, CUDA abstraction layer, GPU resource utilization, PyTorch support
Link mentioned: Introduction | WoolyAI Documentation: What is Wooly?
GPU Memory Buffers on Apple, cuda_graph in Triton Autotune, Resources for GPU/TPU Programming
AMD GPU Rental, Compile HIP code, Runpod MI300 Access
Kernel Compilation, Matrix Shapes, TileLang
Cute Kernels for Training, Triton vs CUDA, Custom Autotune Implementation, LLVM Compiler Efficiency
LCF concurrency, DDP+nccl, Deadlocks
Curriculum Creation, Reasoning Gym, Sonnet Context Experiment, Reasoning GAN Self-Play, LLMs Speed Up Developers
Link mentioned: Experiment: how much do LLMs speed up developers: METR is seeking software engineers who regularly work on large open-source projects to test the effectiveness of AI software engineering tools. Apply here (bit.ly/ai-speedup-apply) Questions? Contact...
AVX-256 performance on 3a, Hybrid AVX-256/AVX-512 approach, Tiling and OpenMP
Open Source AI Projects, GPT-NeoX, Tooling Setup for Claude Code
Link mentioned: GitHub - KellerJordan/modded-nanogpt: NanoGPT (124M) in 3 minutes: NanoGPT (124M) in 3 minutes. Contribute to KellerJordan/modded-nanogpt development by creating an account on GitHub.
Token Assorted Paper, TorchTitan Embedding Sharding, Embedding Layer Implementation
Link mentioned: Why use RowwiseParallel for nn.Embedding instead of ColwiseParallel? · Issue #785 · pytorch/torchtitan: Colwise makes the logic a bit more clear. Rowwise splits on the token dimension, leading to confusion on how the different shards









