
GPT 4.1 vs Gemini 2.5 Pro vs Claude 3.7 : The Ultimate AI Model Comparison
In the ever-evolving realm of artificial intelligence, language models are constantly pushing boundaries in terms of what machines can achieve. For individuals navigating this dynamic landscape, understanding the distinctions between the leading players is crucial. This article delves into a comprehensive comparison of three prominent AI models: OpenAI’s GPT-4.1, Google’s Gemini 2.5 Pro, and Anthropic’s Claude 3.7 Sonnet. By examining their features, performance, and practical applications, we aim to provide a detailed insight into how these AI powerhouses stack up against each other, enabling you to determine the model that aligns best with your specific requirements.
GPT-4.1
GPT-4.1 stands as the latest advancement in OpenAI’s Generative Pre-trained Transformer (GPT) series, building upon the groundwork laid by GPT-4o and its predecessors. This newest iteration introduces significant enhancements, particularly in its ability to execute coding tasks with greater proficiency, adhere to instructions more reliably, and process a larger volume of information thanks to its expanded context window, which can now encompass up to 1 million tokens. OpenAI has diversified its offerings in this lineup by introducing GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano. Each of these models is tailored to address diverse computational requirements and applications, providing users with multiple options based on their specific needs for speed, cost, and performance. The introduction of a "nano" model reflects OpenAI’s strategic objective to offer AI solutions across a broad spectrum of computational demands, catering to both intensive applications and more streamlined uses. This nomenclature implies a smaller, swifter, and more cost-effective variant, indicating a concerted effort to appeal to users with varying latency and budget considerations.
Gemini 2.5 Pro
Gemini 2.5 Pro represents Google DeepMind’s latest artificial intelligence model, with a strong focus on enhanced reasoning and coding capabilities. A key feature of this model is its "thinking model" architecture. This design empowers Gemini 2.5 Pro to engage in a process of deliberation and analysis of prompts before delivering a response, leading to higher precision in its outputs. Furthermore, Gemini 2.5 Pro is built on native multimodality, enabling seamless comprehension and processing of information from various sources, including text, audio, images, and video. With an impressive context window of 1 million tokens, there are plans to further expand this capacity in the future. Google's emphasis on "reasoning" underscores a clear intent to tackle more intricate and nuanced tasks that require a deeper level of comprehension beyond simple pattern recognition in data. The consistent highlighting of its "thinking model" nature and explanation of its analytical, conclusive, and contextual capabilities suggest a design aimed at closely emulating human cognitive processes.
Claude 3.7 Sonnet
Claude 3.7 Sonnet stands as Anthropic’s most advanced model released to date, distinguished by its innovative "hybrid reasoning" framework. This unique architecture enables Claude 3.7 Sonnet to alternate between providing rapid answers for simpler queries and adopting a more thoughtful, step-by-step approach to complex issues through its "extended thinking" mode. The model demonstrates impressive coding and front-end web development capabilities, and Anthropic has introduced Claude Code, a command-line interface tool designed to facilitate proactive coding practices. Claude 3.7 Sonnet boasts a 200K token context window and possesses multimodal comprehension, allowing it to handle both textual and visual data. Anthropic’s focus on "hybrid reasoning" and "extended thinking" signifies a design ethos that emphasizes both speed and precision. This flexibility enables users to tailor the model's behavior to suit the specific demands of the task at hand. The explicit ability to transition between swift and deliberate reasoning underscores a versatility that could prove particularly advantageous across a diverse array of applications with varying requisites.
Coding Prowess: Benchmarking Their Abilities
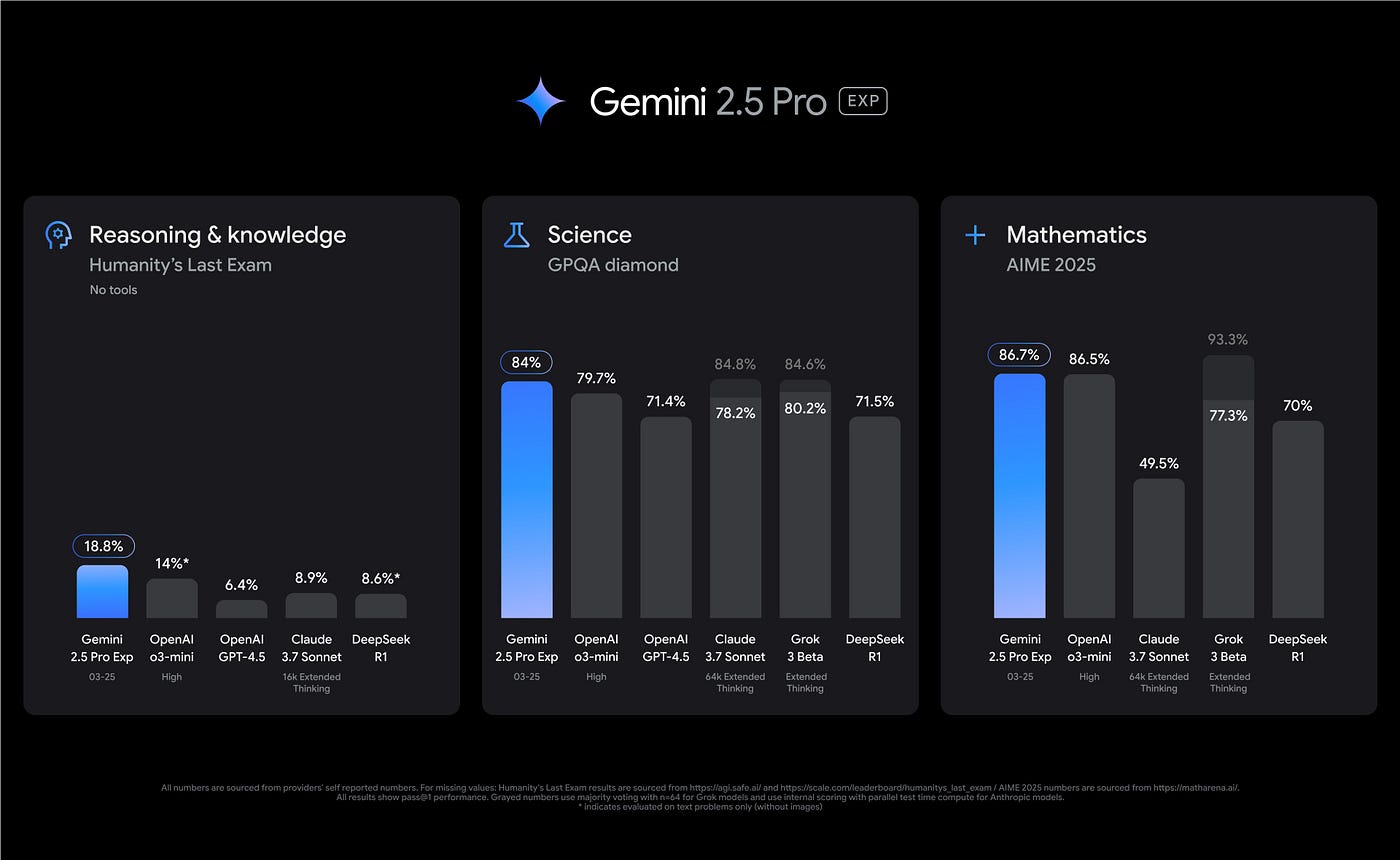
When evaluating the coding capabilities of GPT 4.1, Gemini 2.5 Pro, and Claude 3.7, benchmark results offer valuable insights. In the SWE-bench Verified benchmark, which assesses how effectively models can rectify actual coding issues, Gemini 2.5 Pro claims the top spot with a score of 63.8%. Claude 3.7 Sonnet closely follows, scoring 62.3% on the base benchmark and achieving 70.3% with a custom scaffold. GPT-4.1, while performing credibly, ranks last in this specific benchmark, scoring between 52% and 54.6%. However, GPT-4.1 excels in other programming-related tasks, showcasing greater consistency in code variance across different formats and outperforming in front-end coding, where human evaluators preferred websites generated by GPT-4.1 over GPT-4o 80% of the time. Gemini 2.5 Pro has earned acclaim for producing intricate functional code in a single iteration, such as constructing a flight simulator or solving a Rubik’s Cube. Claude 3.7 Sonnet also shines in handling complex codebases and multi-step coding assignments, leading Anthropic to introduce Claude Code, a feature tailored to further enhance its code generation prowess.
SWE-bench Verified Scores
While Gemini 2.5 Pro and Claude 3.7 Sonnet demonstrate outstanding performance across coding tests, GPT-4.1’s prowess in front-end development and code differentiation-specific enhancements positions it as the preferred choice for developers with specific workflow requirements. A comprehensive analysis of a range of coding tasks reveals that the optimal model selection hinges on the user’s precise coding necessities. In the realm of reasoning and problem-solving, comparing GPT 4.1, Gemini 2.5 Pro, and Claude 3.7 showcases distinctive strengths in each. Gemini 2.5 Pro excels in benchmarks assessing intricate reasoning, such as GPQA (expert-level graduate-level reasoning) and AIME (American Invitational Mathematics Examination). It also performs well in Humanity’s Last Exam, a challenging benchmark evaluating broad general knowledge and reasoning across diverse domains. Claude 3.7 Sonnet exhibits robust reasoning capabilities, particularly at the graduate level and expert reasoning, with its "extended thinking" mode facilitating a detailed analysis for complex problems. This capability offers users insight into the model’s thinking process, aiding in understanding how solutions are developed. GPT-4.1 showcases superior instruction adherence and multi-turn conversation handling, reflecting enhanced reasoning in interactive contexts. The transparent reasoning process available in Claude 3.7 Sonnet through its "extended thinking" mode confers a unique advantage to users requiring visibility into the model’s problem-solving steps, making it valuable for debugging intricate outputs or educational purposes. Although Gemini 2.5 Pro seemingly holds a slight edge in overall reasoning prowess based on benchmarks, Claude 3.7 Sonnet's controlled reasoning capability offers a distinct advantage for specific applications. The ability to process and retain information over extended interactions is pivotal for most applications, and the size of the context window is critical. In this regard, GPT-4.1 and Gemini 2.5 Pro present a remarkable 1 million token context window, enabling these models to effectively handle extensive documents, entire code repositories, and prolonged conversations with ease. Conversely, Claude 3.7 Sonnet, while proficient, features a relatively modest 200K token context window. GPT-4.1 is specifically engineered to access information across its entire 1 million token context reliably, outperforming its predecessors in identifying pertinent text within extensive contexts. Gemini 2.5 Pro has also excelled in evaluations assessing comprehension of long contexts. The vast context windows of Gemini 2.5 Pro and GPT-4.1 offer significant advantages for tasks necessitating processing large volumes of data, rendering them ideal for enterprise-grade applications or intensive research endeavors. Processing extensive code repositories or sizable documents within a single prompt can notably streamline workflows and alleviate the burden of prompt formulation.
Multimodal Capabilities
The ability to process and understand various forms of data, including images and text, is increasingly vital. An examination of the multimodal strengths in GPT 4.1, Gemini 2.5 Pro, and Claude 3.7 reveals Gemini 2.5 Pro leading the pack with its innate multimodality, encompassing text, audio, images, and video right from the outset. All members of the Claude 3 family, such as 3.7 Sonnet, incorporate vision capabilities, enabling them to analyze and process image data. GPT-4.1 supports both textual and image inputs. This multimodal adeptness enables a myriad of applications, spanning from analyzing images and interpreting video content to processing documents containing figures and graphs. Gemini 2.5 Pro’s extensive support for multiple modalities, including audio and video, confers a distinct advantage in scenarios requiring comprehension and processing of diverse data types. Native support for video and audio could prove particularly beneficial for applications like processing meeting recordings or deciphering the contents of video files.
Real-World Utility
The effectiveness of an AI model is not solely measured by benchmarks but also by its capacity to accurately follow instructions and its practical utility in real-world contexts. Comparing GPT 4.1, Gemini 2.5 Pro, and Claude 3.7 in this aspect underscores GPT-4.1’s notable advancements in instruction adherence assessments. Gemini 2.5 Pro showcases promising aptitude in grasping subtle prompts and finds application across various domains. Claude 3.7 Sonnet exhibits exceptional precision in following instructions, making it ideally suited for powering AI agents required to execute tasks in adherence to specific guidelines. All three models have proven valuable across a diverse array of real-world applications, including code generation, data analysis, and content creation. GPT-4.1’s particular focus on and reported improvements in instruction adherence suggest its potential value in use cases necessitating strict compliance with intricate instructions. Robust instruction adherence is imperative for developing robust and dependable AI applications.
Use Cases
Use Cases for GPT-4.1: GPT-4.1 demonstrates remarkable aptitude in software programming, making it a valuable tool for tasks like code composition, debugging, and code validation. Its ability to handle extensive contexts renders it particularly effective in processing lengthy legal documents or research papers. Additionally, its enhanced instruction adherence and comprehensive context comprehension make it highly proficient in constructing advanced AI agents. Organizations such as Thomson Reuters have witnessed a 17% enhancement in accuracy while utilizing GPT-4.1 for reviewing lengthy legal documents, and Carlyle experienced a 50% increase in extracting information from intricate financial documents. This underscores GPT-4.1's suitability for developer use and enterprise applications requiring extensive information processing.
Use Cases for Gemini 2.5 Pro: Gemini 2.5 Pro showcases prowess in intricate reasoning tasks, positioning it as a viable option for applications that demand advanced reasoning capabilities. Its strong performance in Humanity’s Last Exam and similar benchmarks highlights its competence in broad knowledge and reasoning domains. Claude 3.7 Sonnet also excels in reasoning tasks, particularly at expert and graduate levels. The model’s "extended thinking" mode facilitates detailed problem analysis, providing users with insight into its decision-making process. GPT-4.1's strength lies in instruction adherence and multi-turn conversation handling, indicating superior reasoning in interactive settings. The visible reasoning process offered by Claude 3.7 Sonnet through its "extended thinking" mode presents a unique advantage for users requiring transparency in the model’s problem-solving steps, making it valuable for debugging complex outputs or educational purposes. While Gemini 2.5 Pro may have a slight edge in overall reasoning efficiency based on benchmarks, Claude 3.7 Sonnet’s controlled reasoning capability offers a definitive edge for specific applications.









