
alphaXiv: Explore
Researchers from Meta FAIR, NYU, MIT, and Princeton demonstrate that Transformer models can achieve equal or better performance without normalization layers by introducing Dynamic Tanh (DyT), a simple learnable activation function that reduces computation time while maintaining model stability across vision, diffusion, and language tasks.
Researchers from Oxford's Visual Geometry Group and Meta AI develop VGGT, a transformer-based architecture that directly infers multiple 3D scene attributes from multi-view images in a single forward pass, eliminating the need for iterative optimization while processing scenes in under one second through alternating frame-wise and global attention mechanisms.
An information-theoretic analysis demonstrates that the human brain's theoretical storage capacity (2.8 x 10^15 bits) falls short of the calculated minimum information requirements for conscious experience (9.46 x 10^15 bits), challenging fundamental assumptions about the brain operating as a classical digital computer.
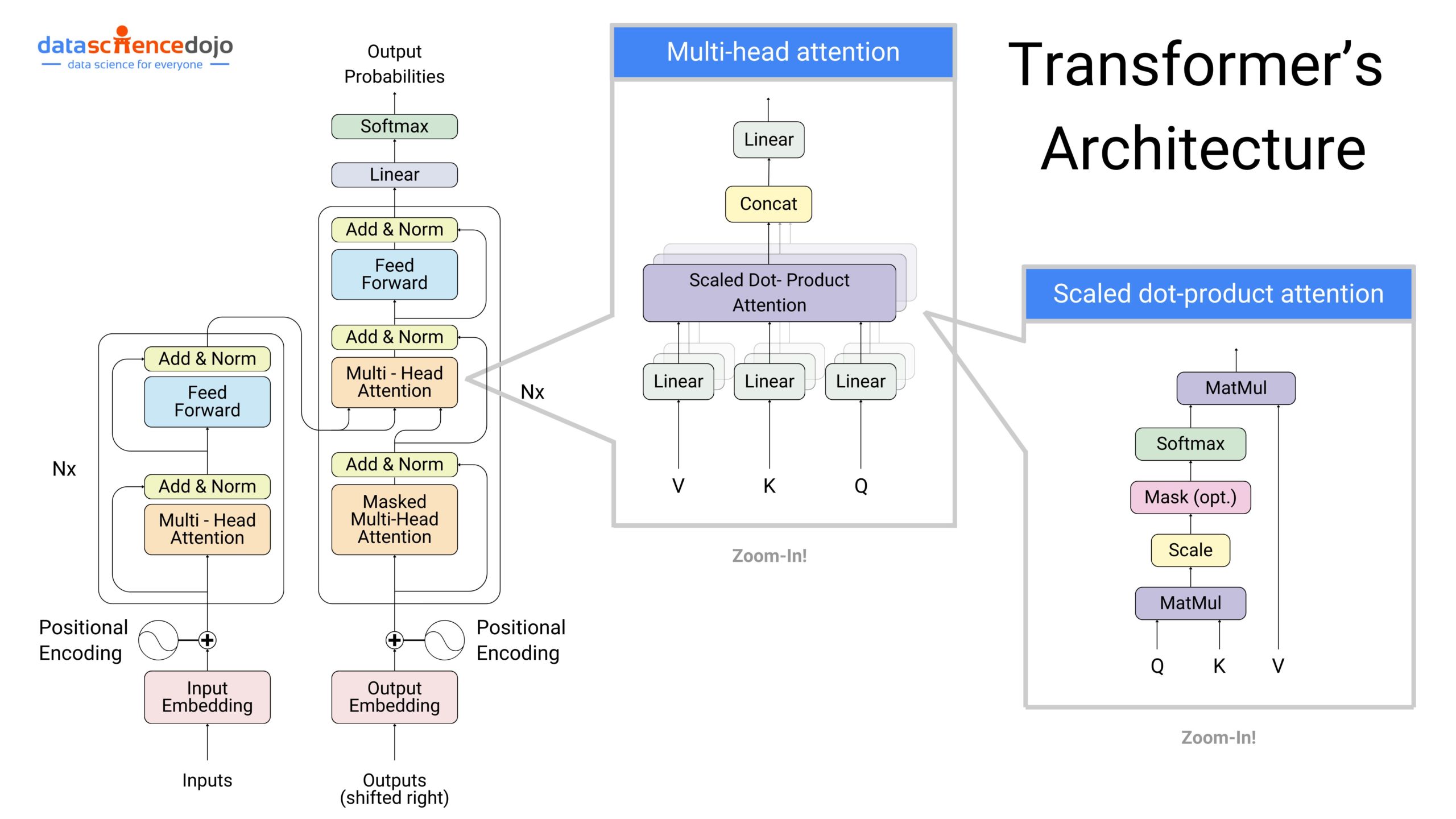
Cornell Tech researchers introduce Block Diffusion (BD3-LMs), a framework that interpolates between autoregressive and diffusion language models by combining block-wise autoregressive modeling with within-block diffusion, achieving state-of-the-art perplexity among discrete diffusion models while enabling arbitrary-length sequence generation through innovative variance reduction techniques and efficient training algorithms.
Researchers at IIIA-CSIC demonstrate how Large Language Models can improve existing optimization algorithms without requiring specialized expertise, showing enhanced performance across multiple classical algorithms when tested on Traveling Salesman Problem instances while maintaining or reducing code complexity through systematic prompt engineering and validation.
Shanghai Jiao Tong University researchers introduce BRILLM, a brain-inspired language model architecture that replaces traditional transformer attention with a Signal Fully-connected Flowing (SiFu) mechanism, enabling node-level interpretability and sequence-length independence while achieving performance comparable to GPT-1 on Chinese language tasks.
Researchers from Zhejiang University and Kuaishou Technology introduce ReCamMaster, a framework that enables camera-controlled re-rendering of videos by leveraging pre-trained text-to-video diffusion models with a novel frame-dimension conditioning mechanism, allowing users to modify camera trajectories while preserving the original video's content and dynamics.
Johannes Kepler University and NXAI researchers present xLSTM 7B, a recurrent language model architecture that achieves comparable performance to 7B-parameter Transformer models while delivering 50% faster inference than Mamba and maintaining constant memory usage through optimized matrix LSTM cells and custom GPU kernels.









