
ChatGPT just passed the Turing test — but that doesn't mean AI is ...
Recently, there has been a surge of headlines discussing an AI chatbot officially passing the Turing test. This news is based on a recent preprint study by researchers at the University of California San Diego, where four large language models (LLMs) were subjected to the Turing test. One of these models, OpenAI’s GPT-4.5, was found to be indistinguishable from a human over 70% of the time.
The Turing test is often seen as the ultimate benchmark for machine intelligence, but its validity is a topic of debate due to its controversial history. Despite its popularity, the effectiveness of the test in measuring machine intelligence is not universally accepted.
The Study and Results
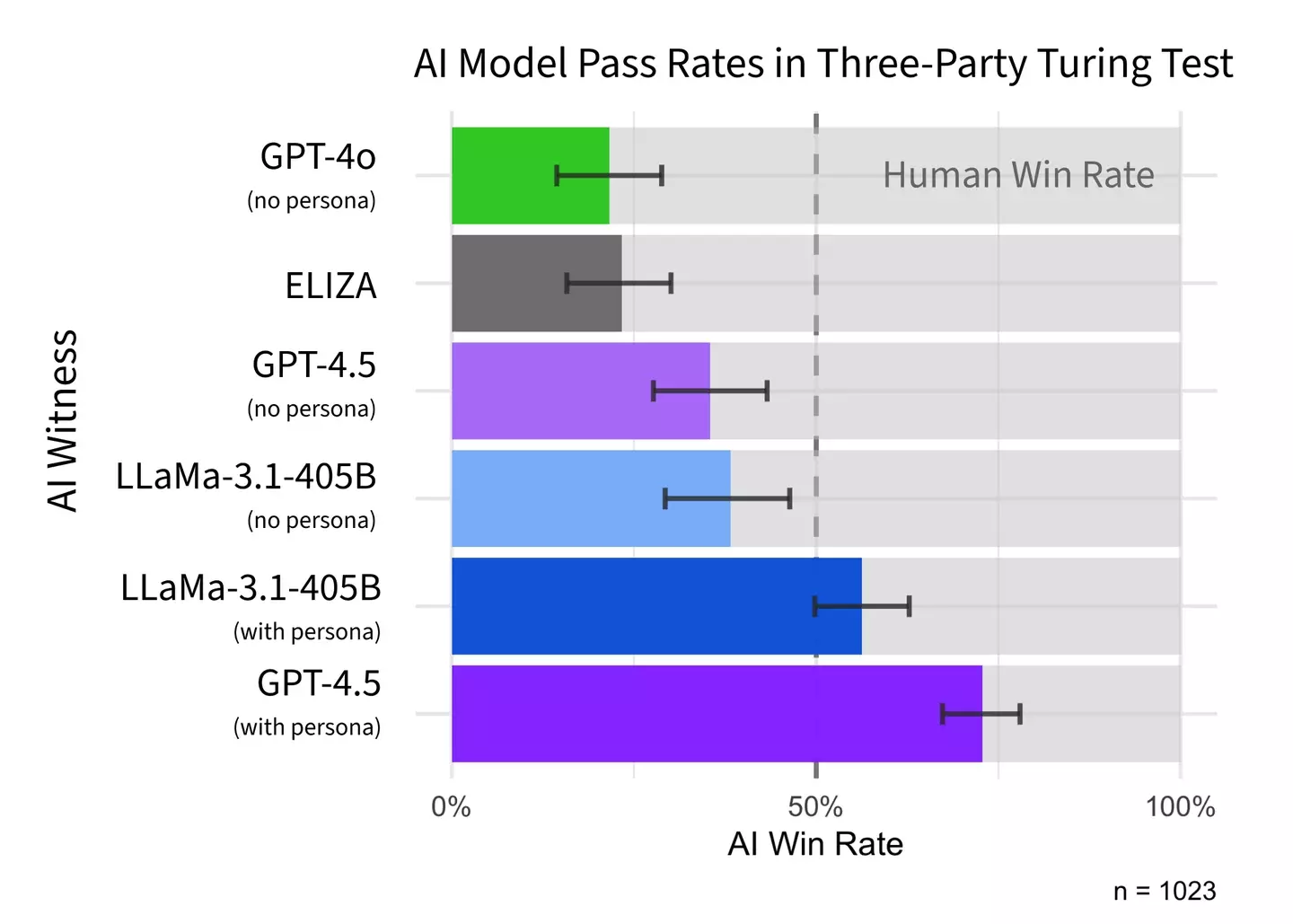
The preprint study conducted by cognitive scientists Cameron Jones and Benjamin Bergen focused on testing four LLMs: ELIZA, GPT-4o, LLaMa-3.1-405B, and GPT-4.5. The participants engaged in eight rounds of conversations where they interacted with two witnesses simultaneously, one human and one LLM. The participants, acting as interrogators, had to determine which of the two was human.
In the study, GPT-4.5 was identified as human by participants 73% of the time, while LLaMa-3.1-405B was perceived as human 56% of the time. The other two models, ELIZA and GPT-4o, managed to fool participants only 23% and 21% of the time, respectively.
Origins of the Turing Test
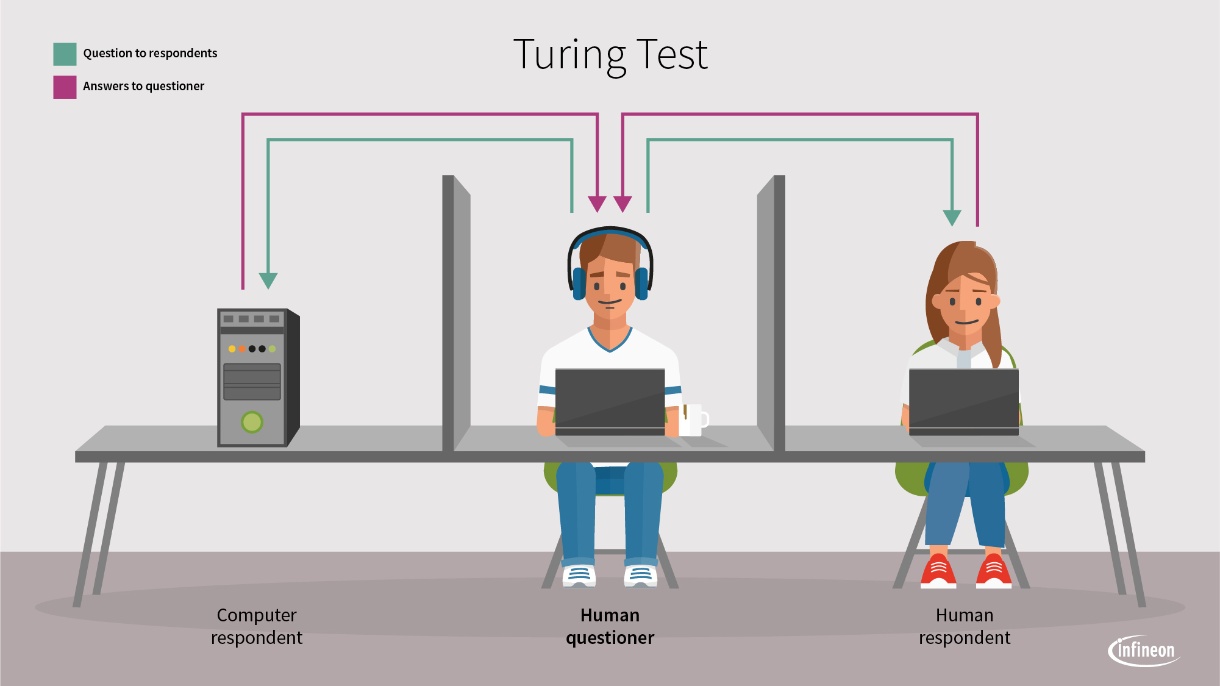
The Turing test was first introduced by Alan Turing in a 1948 paper titled "Intelligent Machinery." Originally framed as an experiment involving three individuals playing chess, the test evolved into the "imitation game" in Turing's 1950 publication, "Computing Machinery and Intelligence." The purpose was to assess whether a machine could exhibit intelligent behavior equivalent to that of a human.
Over time, the Turing test has become synonymous with testing machine intelligence, although its accuracy and relevance are subject to ongoing debate.
Challenges to the Turing Test
There are four main objections to the Turing test, highlighting the limitations and complexities of using it as a definitive measure of machine intelligence. While the preprint study suggests that GPT-4.5 passed the Turing test, the researchers themselves express skepticism about the test's ability to truly assess human intelligence.
It is important to note that the study's conditions, such as the short testing window and the use of specific personas by the LLMs, raise questions about the test's methodology and outcomes.

In conclusion, while GPT-4.5 may have shown promising results in the Turing test, it is clear that AI still falls short of human intelligence. The test may indicate an imitation of human intelligence rather than true equivalence.









