
Adversarial Attacks in AI: How ChatGPT Can Be Hacked
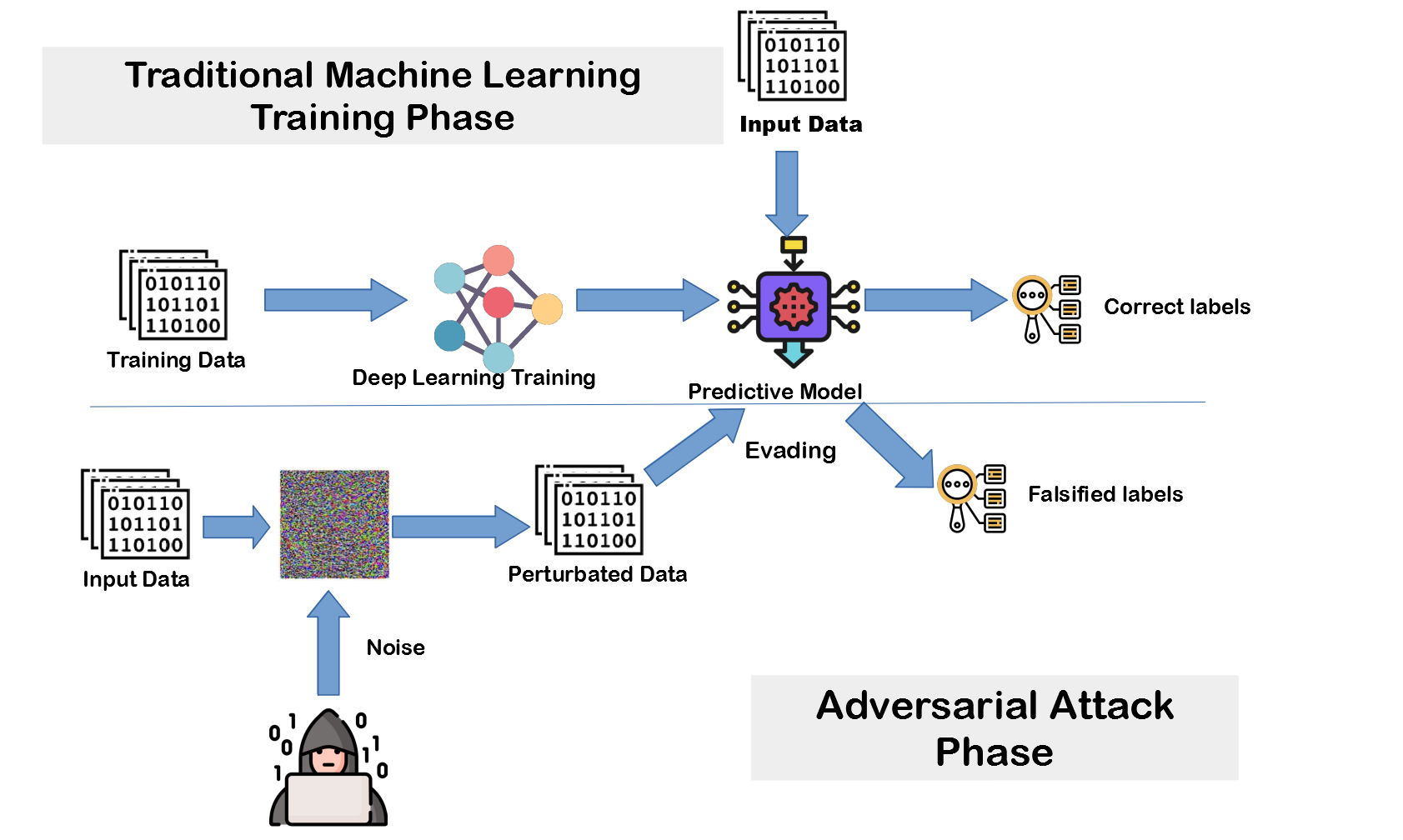
Adversarial attacks are very subtle manipulations of input data that can deceive AI into making wrong predictions or outputs. These manipulations are usually imperceptible to humans and take advantage of weaknesses in AI models by adding carefully crafted noise or deviations to data (like text, images, and sound), which causes the models to interpret the data differently, leading to misclassifications or incorrect outputs.

Explaining Adversarial Attacks Simply
An adversarial attack is when someone tricks an AI by changing something in a way that people can’t notice, but the computer does. It’s like changing a few tiny pixels in a picture of a dog, and suddenly the AI thinks it’s a cat. The changes are so small that you wouldn’t see them, but the AI gets confused.
This is a huge issue because adversarial attacks can undermine the reliability and security of AI systems that are becoming more prominent, especially those deployed in sensitive environments like medicine, autonomous driving, and cybersecurity, where they can put people’s privacy, security, and physical safety at risk.
Types of Adversarial Attacks
Perturbation Attacks: These are the most common attacks and involve making very subtle, usually imperceptible changes to the input data, like tweaking a few words in ChatGPT or modifying images slightly so the AI makes wrong predictions.
Poisoning Attacks: Poisoning attacks manipulate the training data of AI models. By adding malicious or misleading data into the training set, attackers can change the entire model’s behavior during deployment.
Evasion Attacks: Evasion attacks happen during the model’s inference stage. Attackers change input data so the model doesn’t detect it as malicious.
Challenges Faced by AI Models
ChatGPT and other large language models are very sophisticated but are still vulnerable to adversarial attacks. These models rely heavily on probabilistic models and pattern recognition, making them susceptible to manipulation.
One common vulnerability is bypassing ethical safeguards. For example, ChatGPT can be manipulated to provide responses that were meant to be restricted.
Protecting Against Adversarial Attacks
Adversarial Training: Exposing the model to adversarial data during the training process can improve its robustness.
Gradient Masking: Making it difficult for attackers to generate effective perturbations by altering the gradient landscape.
Regularization Techniques: Preventing overfitting to adversarial examples by adding penalty terms to the model’s objective function during training.
By strengthening defenses through techniques like adversarial training, gradient masking, and human oversight, we can create AI models that serve society safely.
The Future of AI and Adversarial Attacks
As AI continues to grow in popularity and complexity, it is crucial to address the robustness of these models to prevent intentional or accidental mistakes from shaping society in dangerous ways.









