
How to Summarize the Text from Audio Using Gemini Pro Multimodal
In this blog, we will discuss how to summarize the content from audio files using Gemini Pro Multimodal. Gemini Pro Multimodal is a powerful tool that utilizes Multimodal LLMs to summarize various data types, including audio-to-text summarization.
The Power of Gemini Pro Multimodal
The Gemini Pro 1.5, developed by Google's Deep Mind, is the latest multimodal model that can handle a wide range of tasks and different types of data, such as text, audio, images, and video. It has an extended context window, supporting up to 2 million tokens, making it the largest context window of any large-scale foundation model.
With a near-perfect recall score on long-context retrieval tasks across modalities, Gemini Pro excels in processing large-scale documents, code, audio, video, and more.
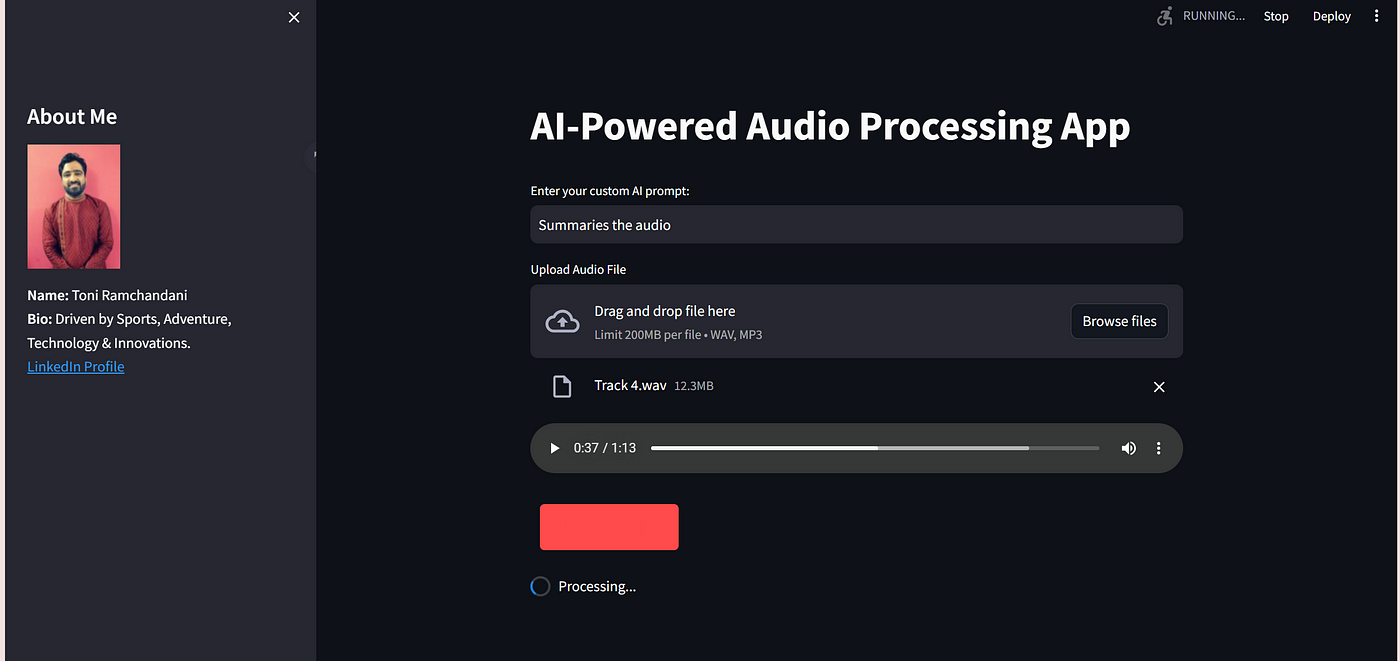
How It Works
When summarizing audio, two types of audio files (WAV & MP3) are used and processed by the Gemini model. The audio is converted into text, and a summary is generated based on the text's context.
Before starting the summarization process, you need to generate a Gemini API key. You can do this by visiting https://aistudio.google.com/.
Workflow Overview
The workflow involves installing required packages, configuring the Gemini API key, defining functions to process audio files, and creating a user interface using Streamlit.

After launching the Python file with the specified commands, the Gemini Pro Multimodal summarizes the content from the audio file, making it a convenient tool for text summarization.

Thank you for reading!









