
Ilya Sutskever | OPEN AI has already achieved AGI through large ...
The advancements in reinforcement learning, meta-learning, and self-play at OpenAI have paved the way for achieving Artificial General Intelligence (AGI). These innovations have revolutionized the field of deep learning, setting new benchmarks for optimal generalization and decision-making capabilities.
Introduction to Meta Learning and Self Play at OpenAI
At OpenAI, meta learning and self-play have become integral components in the pursuit of AGI. Through the exploration of short programs and small circuits, researchers have unlocked the potential for enhanced generalization in deep learning models. This strategic approach has redefined the boundaries of AI capabilities and opened up new possibilities for intelligent systems.
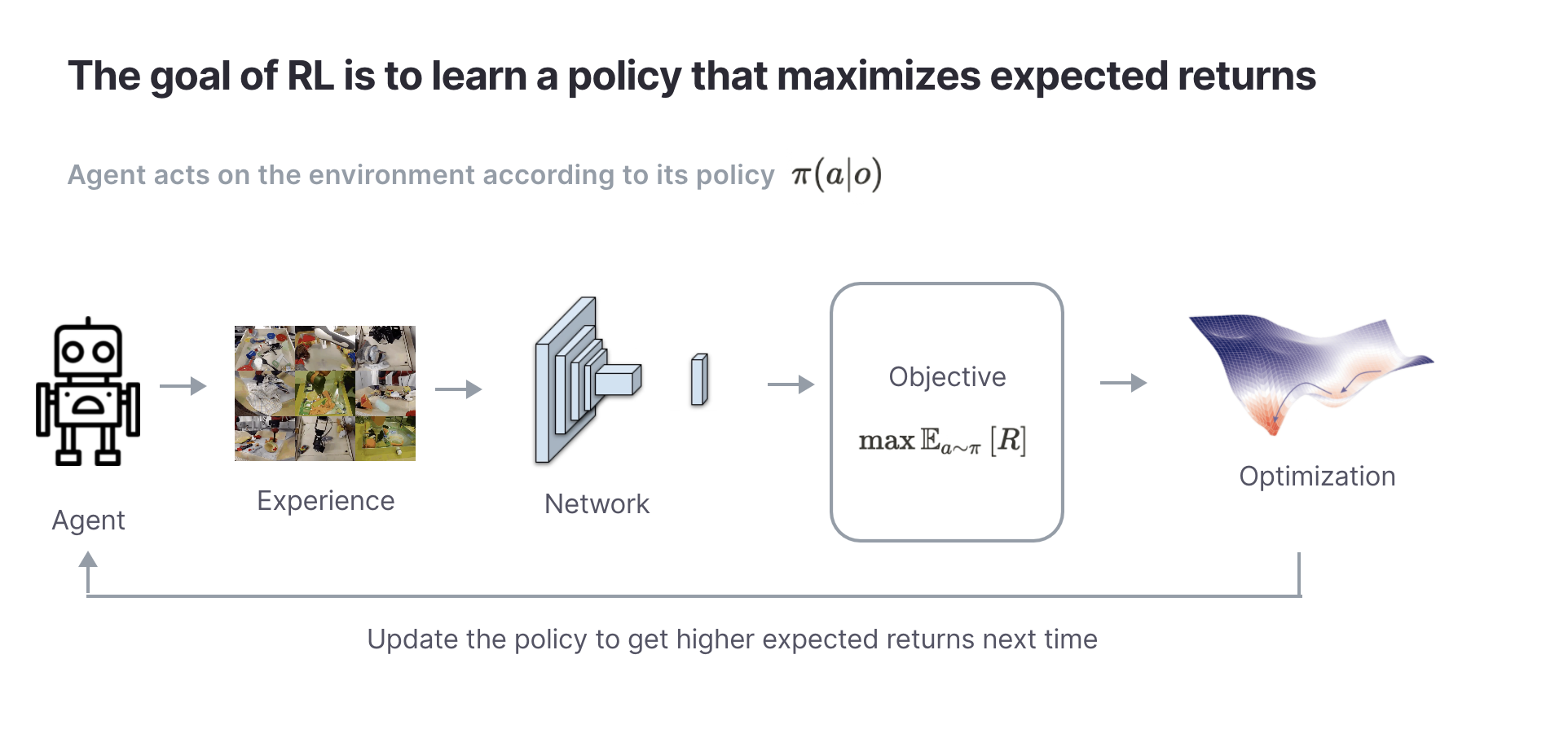
Reinforcement Learning Framework
The reinforcement learning framework is at the core of training agents to interact with their environment, learn from rewards, and make informed decisions. Concepts such as policy gradients, Q-learning, and hindsight experience replay have been instrumental in pushing the boundaries of AI performance and advancing the field towards AGI.
Transfer Learning and Hierarchical Reinforcement Learning
Transfer learning from simulated environments to real-world applications has demonstrated the power of meta learning in improving generalization. Additionally, hierarchical reinforcement learning has proven to be a game-changer in addressing challenges related to long horizons and exploration, laying the groundwork for more efficient learning processes.
As AI continues to evolve, the need for competent agents in complex environments becomes more apparent. Training strategies based on hindsight experience policies and task continuity are poised to shape the future of AI development. Furthermore, the role of self-play environments and new architectures in driving cognitive advancements underscores the transformative potential of AI technologies.
FAQ
Q: What is meta learning and how is it used at OpenAI?
A: Meta learning involves training models on a variety of tasks to improve generalization. At OpenAI, it enhances agent adaptability to new tasks efficiently.
Q: Why are short programs and small circuits important in the context of deep learning and generalization?
A: Short programs and small circuits play a crucial role in achieving optimal generalization in deep learning by simplifying processes and promoting efficiency.
Q: What is reinforcement learning and how does it work?
A: Reinforcement learning is a framework for training agents to interact with environments, receive rewards, and make decisions based on optimized algorithms.

Q: What are policy gradients and Q-learning algorithms in reinforcement learning?
A: Policy gradients and Q-learning algorithms enhance agent decision-making by adjusting policies based on rewards and value functions.
Q: What is hierarchical reinforcement learning and how does it address challenges in long horizons and exploration?
A: Hierarchical reinforcement learning breaks down complex tasks into subtasks, improving learning efficiency in scenarios with lengthy horizons and exploration challenges.
Q: Why is curriculum learning important in neural networks and how does it relate to human learning?
A: Curriculum learning mirrors the human learning process of gradually increasing difficulty levels, aiding in better learning outcomes and generalization.









