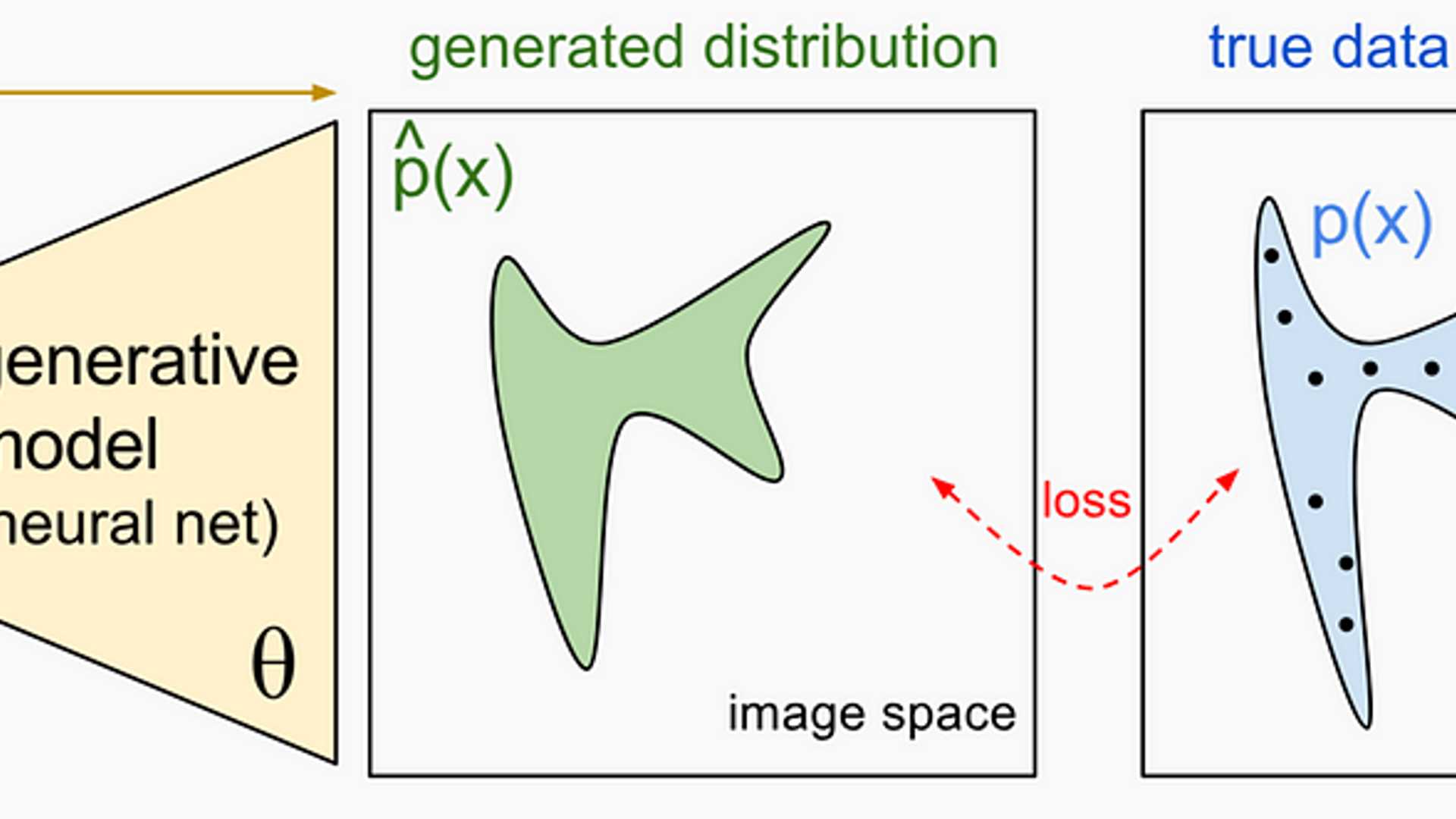
Generative Modeling
Generative modeling (GM) are designed to learn the underlying distribution of data and generate new data samples that resemble the original data. Since the goal in GM is to learn the underlying distribution of the data itself without the need for labels or specific output variables, GM is primarily associated with unsupervised learning for sequentially ordered data.
Learning the Data Distribution
Suppose x0, x1, x2, …, xT represents a sequence of observed data, GM aims to learn the underlying distribution of this sequence, specifically the joint probability distribution p(x0, x1, x2, …, xT). By learning this full distribution, the model can generate new samples that reflect the structure, patterns, and dependencies of the observed data, enabling the creation of similar sequences.
The goal is to approximate the true data distribution p(x0, x1, x2, …, xT) with a model distribution pθ(x0, x1, x2, …, xT), where θ represents the model parameters. The parameters are estimated using Maximum Likelihood Estimation (MLE).
Introduction of Latent Variables
Generative models often introduce a set of latent variables z (or z0, z1, … in sequence-based models) that represent hidden or underlying unobserved factors driving the observed data x. These latent variables can capture complex patterns, such as trends, seasonality, or dependencies.
For instance, in VAEs or GANs, z could be a random vector sampled from a prior distribution (such as a Gaussian distribution), which is then used to generate the data.
Conditional Distribution
Given the latent variables, GM is interested in learning the conditional distribution of the entire data point p(x|z). Depending on the model’s structure and task, we may use:
- p(xi|z) for a single xi in a sequence, e.g., one word in a text or one observation in a time series,
- p(x0, x1, …, xT|z) for the entire sequence.
Case (a) occurs in language models, such as autoregressive models or RNN-based models, where the model is trained to maximize the likelihood of predicting each word based on its preceding context. In this setup, the model maximizes the likelihood of observing each word xi given the previous words in the sequence.

Case (b) occurs in GMs like Variational Autoencoders (VAEs) applied to sentence generation, xi is typically treated as a complete sentence, and the goal is to learn the distribution over entire sequences.
Generating New Data Points
Once the model is trained, we can generate new data points xnew by:
For models like Variational Autoencoders (VAEs), we use an approximate inference technique to estimate p(x) by introducing an auxiliary distribution q(z|x), which approximates the posterior p(z|x).
GM.1943-5622.0000481/asset/986280a0-f8df-43de-933b-8444243056bb/assets/images/large/figure1.jpg)
The model maximizes a quantity known as the Evidence Lower Bound (ELBO), which is given by:
where KL denotes the Kullback-Leibler divergence, which measures the difference between the approximate posterior q(z|x) and the prior p(z).
When talking about methods or approaches (e.g., GANs, VAEs, diffusion models), “generative modeling” is appropriate.









