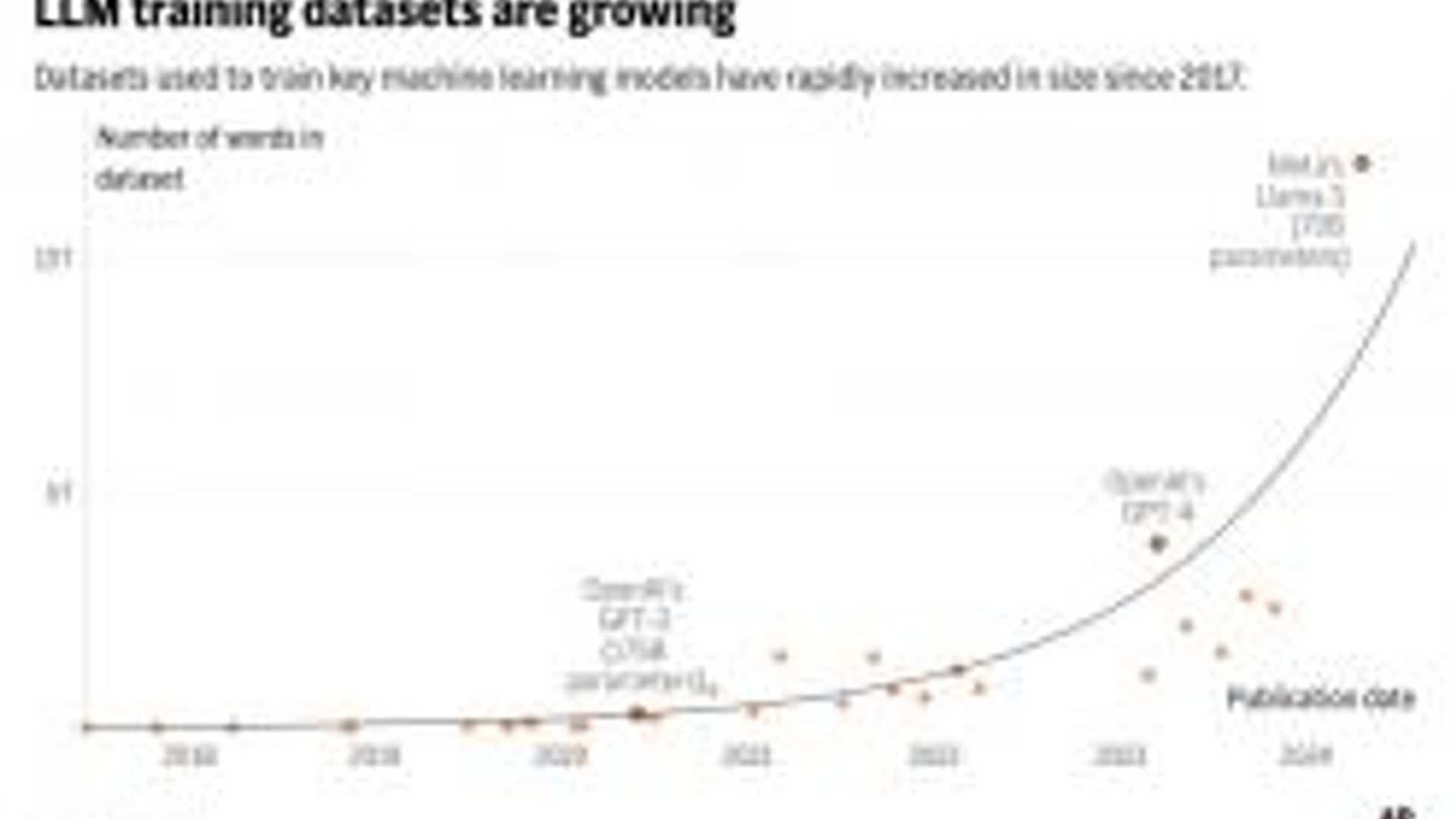
AI chatbot training data could run out of human-written text...
Artificial intelligence systems, such as ChatGPT, are facing a potential challenge in the near future. The vast amount of human-generated text that has been fueling the development of AI language models is projected to run out by the turn of the decade. A recent study by research group Epoch AI suggests that tech companies may deplete the available training data for AI language models between 2026 and 2032.

The Impact of Data Depletion
Described as a "literal gold rush" of finite natural resources, the depletion of human-generated text could slow down the pace of AI progress. Companies like OpenAI and Google are currently racing to secure high-quality data sources, such as content from Reddit forums and news media outlets, to train their AI models.
Challenges and Bottlenecks
Tamay Besiroglu, a researcher involved in the study, highlighted the bottleneck that could arise from the diminishing availability of training data. Scaling up AI models efficiently relies heavily on the volume and quality of the data fed into them.
![]()
While recent advancements have enabled AI models to make better use of existing data, there are limits to how much they can rely on the same sources. The study predicts that the supply of public text data may be exhausted within the next few years, leading to a potential slowdown in AI development.
Considerations for the Future
As the AI community grapples with this impending data shortage, questions arise about the necessity of training ever-larger models. Some experts suggest that focusing on specialized models for specific tasks could be a viable alternative to constantly expanding general AI systems.
Ensuring Data Sustainability
Organizations like Wikipedia, which serve as critical sources of human-generated data, are considering the implications of AI training on their content. While some platforms restrict AI access to their data, others, like Wikipedia, maintain an open approach to AI utilization.
It is essential for AI companies to prioritize the preservation of human-generated content and incentivize ongoing contributions to ensure the availability of high-quality data for AI training. While exploring new methods like synthetic data generation, striking a balance between different data sources is crucial for driving technical advancements in AI.
Ultimately, the future of AI development hinges on the sustainable management of training data and the responsible utilization of evolving technologies.









