Meta AI Introduces Thought Preference Optimization Enabling AI Models to Think Before Responding
A team of researchers from Meta FAIR, the University of California, Berkeley, and New York University has introduced a groundbreaking new method known as Thought Preference Optimization (TPO). This innovative approach aims to enhance the response quality of instruction-fine tuned Large Language Models (LLMs) by enabling them to generate and refine internal thought processes to produce more accurate and coherent responses.
Enhancing AI Models with Thought Preference Optimization
Unlike traditional models that focus solely on final answers, TPO encourages LLMs to "think before responding" during training. By implementing a modified Chain-of-Thought (CoT) reasoning method, models are guided to prepare structured internal thoughts before delivering a final answer. This strategic approach helps in optimizing and streamlining the thought processes of the models without exposing intermediate steps to users.
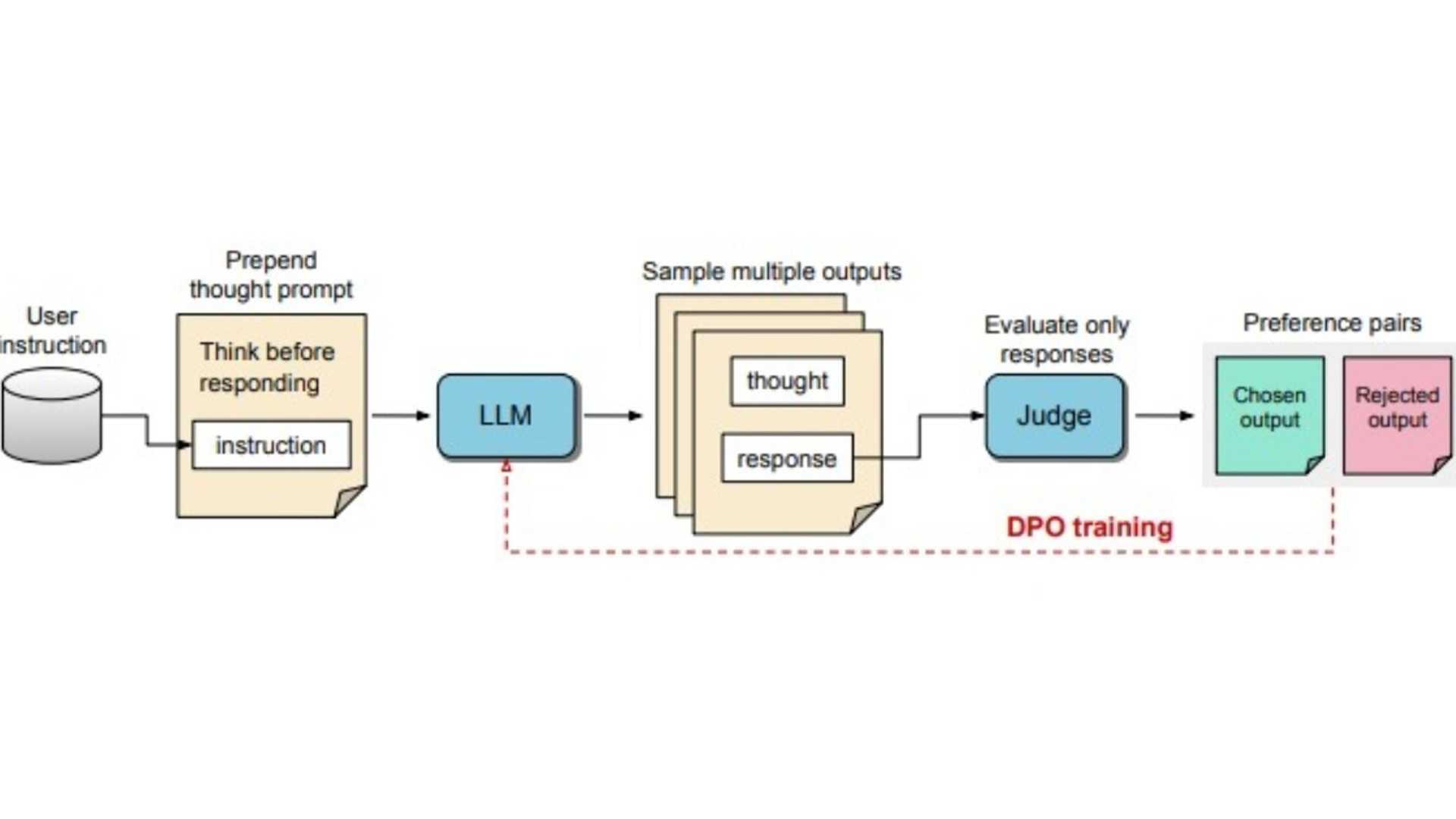
 The diagram illustrates the Thought Preference Optimization (TPO) process, where LLMs are prompted to generate various thoughts before formulating a response. These outputs are then evaluated to identify the best responses, which are further used to enhance the model's response quality using Direct Preference Optimization (DPO). Through iterative training, this method significantly improves the model's ability to produce relevant and high-quality responses, thereby increasing its overall effectiveness.
The diagram illustrates the Thought Preference Optimization (TPO) process, where LLMs are prompted to generate various thoughts before formulating a response. These outputs are then evaluated to identify the best responses, which are further used to enhance the model's response quality using Direct Preference Optimization (DPO). Through iterative training, this method significantly improves the model's ability to produce relevant and high-quality responses, thereby increasing its overall effectiveness.
Optimizing Thought Generation for AI Models
During the training process, prompts are adjusted to guide LLMs to think internally before responding. This sequence helps in refining responses for improved clarity and relevance. By evaluating only the final answers, an LLM-based judge model scores response quality independently of hidden thought steps, allowing models to enhance their response quality effectively.
 Benchmark win rates for AlpacaEval and Arena-Hard are compared, showcasing the effectiveness of Thought Preference Optimization (TPO) over baseline models.
Benchmark win rates for AlpacaEval and Arena-Hard are compared, showcasing the effectiveness of Thought Preference Optimization (TPO) over baseline models.
Revolutionizing AI Technology with TPO
 The TPO method extends the capabilities of AI models by enabling them to handle complex instructions more effectively. This research suggests that TPO could make LLMs more adaptable and effective across various fields, with applications in industries that demand flexibility and depth in response generation.
The TPO method extends the capabilities of AI models by enabling them to handle complex instructions more effectively. This research suggests that TPO could make LLMs more adaptable and effective across various fields, with applications in industries that demand flexibility and depth in response generation.
By embracing Thought Preference Optimization,  the future of AI models looks promising in terms of enhanced adaptability and effectiveness in diverse contexts.
the future of AI models looks promising in terms of enhanced adaptability and effectiveness in diverse contexts.









