
Today we’re excited to launch our next era of models built for this new agentic era: introducing Gemini 2.0, our most capable model yet. With new advances in multimodality — like native image and audio output — and native tool use, it will enable us to build new AI agents that bring us closer to our vision of a universal assistant.
Google has launched Gemini 2.0, its most advanced AI model yet. Normally, it’s OpenAI upstaging a Google AI launch with their own release news, but this week, Google upstaged OpenAI’s 12 days of releases with the biggest release in a huge week in new releases. Google announced both a new foundation AI model, Gemini 2.0 Flash experimental, as well as AI personal assistant features and tools: Deep Research, Project Astra, and Project Mariner.
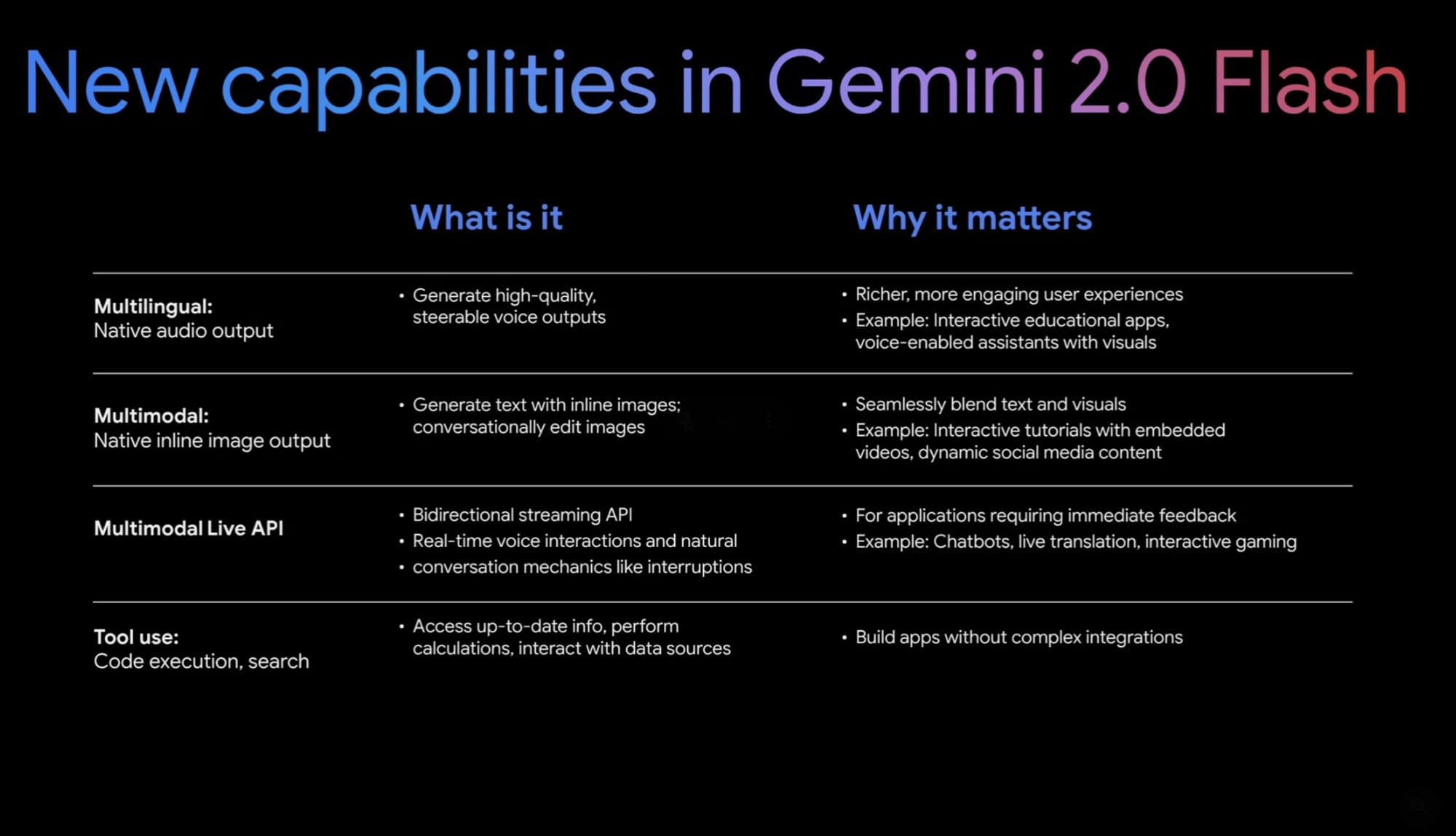
Gemini 2.0 Flash can generate images, audio, and text, use third-party apps, and interact via Google Search
It features new native output modalities – multilingual native audio output and image output - as well as native tool use. It also has a Multimodal Live API that can detect what’s happening on your screen or camera in real-time and interact:Developers can now build real-time, multimodal applications with audio and video-streaming inputs from cameras or screens. Natural conversational patterns like interruptions and voice activity detection are supported.
Gemini 2.0 Flash not only brings a new level of native multimodality but also higher performance; it beats out Gemini 1.5 Pro and other leading AI models on benchmarks in reasoning (coding and math), factuality, and visual / spatial reasoning. Gemini 2.0 Flash is also two times faster than 1.5 Flash. Combining its new features and performance together, Gemini 2.0 Flash is the biggest step-up in foundation AI model capabilities since GPT-4.
Gemini 2.0 Flash experimental is available for Gemini Advanced users. It’s also available to developers through the vertex Gemini API as well as on Google AI Studio today (usage is free for now), with wider rollout of image and audio features in January. What can developers build with Gemini 2.0 Flash? Google presented several demos:
Using real-time voice interaction and image understanding to have the AI explain a tourist site captured on camera, sharing the info in voice in many languages. Using Multimodal Live API and web search to function as a real-time in-game AI advisor for playing a video game. Using native image output to restyle pictures on command.
Deep Research: Deep Research is an AI assistant for research tasks
that builds detailed research briefs by analyzing and synthesizing information from the web. It generates complex multi-page research reports in minutes, with complexity and depth beyond Perplexity or ChatGPT Search.
Project Astra: Project Astra aims to provide real-time, multimodal understanding
, by processing live video and audio simultaneously. Google has released a prototype of Project Astra’s AR glasses for real-world testing with a limited number of users. There are plans to integrate Project Astra into smart augmented reality (AR) glasses, running on the new Android XR operating system designed for XR hardware like glasses and headsets, but there is no definite product release timeline.
Project Mariner: Project Mariner is Google’s first AI agent that can take actions on the web
. The Gemini-powered agent navigates websites through a Chrome browser extension, performing tasks like filling out forms or shopping online as directed by users. Project Mariner achieved a state-of-the-art result of 83.5% on the WebVoyager benchmark, working as a single agent setup.
Jules: Jules is a coding assistant powered by Gemini 2.0 Flash that sits within GitHub and can write code, fix bugs, and create and execute multi-step plans. Jules is available to a limited pool of testers today.
The bottom line is Gemini 2.0 is a significant update to Google’s AI models, with Gemini 2.0 flash with enhanced multi-modality, tool-use, and performance, and presenting powerful agentic AI applications built on Gemini 2.0.
OpenAI’s "12 Days of OpenAI release announcements continued with releases big and small: Sora, Canvas, ChatGPT in Apple Intelligence, Advanced voice with video, and Projects.
OpenAI officially released the Sora AI video generation model
. Sora is more than just a high-quality AI video generation model but it’s an AI video creation tool with impressive features for video editing and generation: Remix, Re-cut, Storyboard, Loop, Blend and Style pre-sets. We covered Sora in depth in AI Video Generation Soars with Sora. Sora is available to ChatGPT Plus and Pro subscribers and is accessed on its own Sora.com website.

This week OpenAI officially released Canvas for writing and coding, following up on their October beta release of Canvas in ChatGPT. Canvas puts ChatGPT output of artifacts such as writing, drawings, or code into a separate canvas, making an easier workflow for content creation. The new Canvas release also added several powerful features:
Integrated Python execution that runs Python code directly within the canvas interface. Enhanced AI writing collaboration to condense, expand, and refine writing. Canvas for Custom GPTs.Advanced coding tools.OpenAI launched real-time video understanding for ChatGPT, so it can now understand real-time video content and reason on it. Like Project Astra, users can now point their phones at objects or share screen content to ask questions and get near-real-time responses from ChatGPT.

Additionally, OpenAI is making ChatGPT sound like Santa for the holidays with a "Santa Mode" voice feature that makes ChatGPT’s Advanced Voice Mode sound jolly and festive. OpenAI launched Projects for ChatGPT, an interface update to organizing chats and files within ChatGPT, similar to the Claude Projects feature, and with Google Drive-like features.
Apple has rolled out iOS 18.2 to iPhone users
, finally bringing advanced AI capabilities to iPhone end users. AI features in iOS 18.2 include Image Playground, GenMoji, and ChatGPT integration with Apple Intelligence.
Microsoft has released Phi-4, a new SOTA 14B small language model in the Phi family
. Phi-4 specializes in complex reasoning tasks and demonstrates improved performance in areas like solving math problems. With an MMLU of 84.8 and GPQA of 56, Phi-4 outperforms Qwen 2.5 14B and competes with other small models like GPT-4o mini and Claude 3.5 Haiku. Microsoft wrote and shared a technical report on Phi-4 here. Phi-4 is available for research use on Azure AI Foundry and can be downloaded from HuggingFace.
xAI announced a new version of Grok-2 that is now free for all
and is “three times faster and offers improved accuracy, instruction-following, and multi-lingual capabilities.” xAI has added API access to grok-2 and has added two features: “draw me” which generates reimagined versions of users based on their X profile, and a "Grok button" in X for better context discovery and event understanding.
Cognition launched the Devin AI developer assistant
, priced at $500 a month. Devin is an AI agent that plans and implements coding tasks. Reviews are mixed: Devin works via a slack interface in a fully automated fashion; this doesn’t match useful AI coding assistant workflows right now, which aren’t ready for full automation.
Anthropic has released Claude 3.5 Haiku for its Claude AI chatbot platform
. The new Haiku model is particularly adept at coding recommendations, data extraction, and content moderation.









