
Google's Gemini is the world's most capable multimodal AI yet
Earlier this year, Google AI's Brain division merged with DeepMind, a British-American artificial intelligence research lab that Google acquired in 2014. The first 'big' thing to come from this newly formed team, dubbed Google DeepMind, is the 'GPT-4 killer' Gemini.
Google's Gemini is a multimodal large language model (LLM) that is built on the PaLM 2 architecture, with improvements in efficiency, multimodal capabilities, and future-proofing for memory and planning.
The Power of Gemini
In almost every standardised benchmark, Gemini knocks its contemporaries, including the widely praised GPT-4 from OpenAI, out of the equation. But what surprised everyone the most during its 6 December announcement was the fact that Gemini was the first AI model that outperformed human experts on Massive Multitask Language Understanding (MMLU).
That means, in this standardised method of testing an AI model's capabilities, Gemini is better at understanding, answering, and solving problems than humans who are considered the definitive experts in their respective fields.

Multimodal Capabilities
But the initial shock of the 'Gemini Era' came from its monumental multimodal capabilities. With a dataset of 540 billion words and code, 14 million images, and access to Google Search, Gemini, unlike other AI language models, can understand video and audio on top of text, pictures, and code.
Applications in Various Fields
From that interaction, Gemini could understand what is happening in a video, what is being said by the person on the video, or even nonverbal motions or cues like hand gestures to understand the context of that interaction.
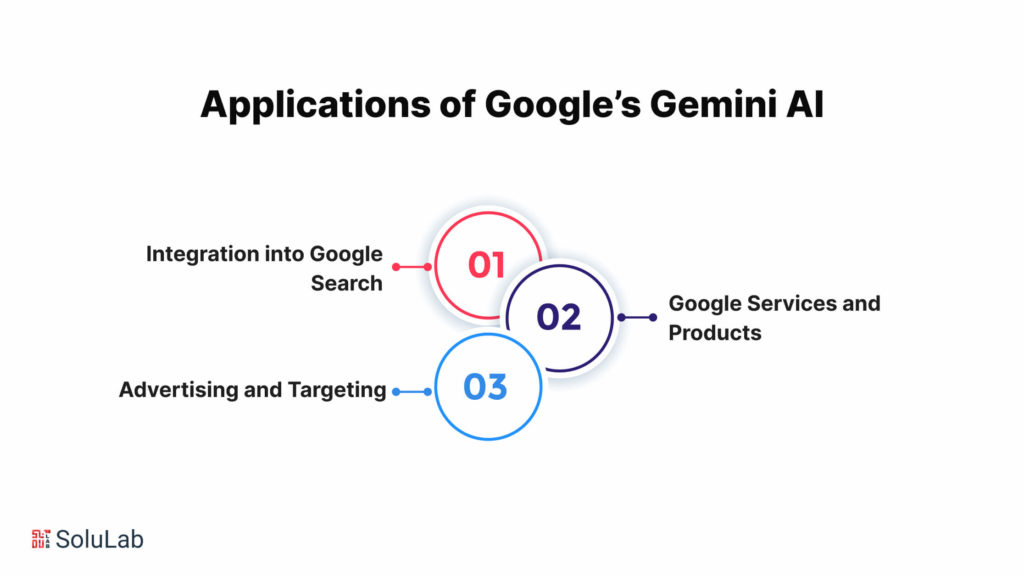
Due to its ability to understand nuanced information, it can solve or offer answers to questions that were previously impossible to have machine-solved without giving it more context or adding metadata.
Code Generation and Adaptability
The first version of Gemini also knows, understands, and can generate code in programming languages like Python, C++, and Java. Since it uses AlphaCode 2, it has the ability to associate complex data to work simultaneously across different programming languages to generate high-quality code, making it the best AI model for coding.
In fact, its generated code is better than 85% human programs, not to mention the fact that it can write a monolith of code in a few seconds, which would take a human hours or even days to finish.
Variants of Gemini
To accommodate everyone and every environment, Google Gemini comes in three sizes.
- Gemini Nano: Google's most efficient model for smaller on-device tasks.
- Gemini Pro: Suitable for large-scale on-device executions and other tasks. A fine-tuned version of it has already been integrated into Bard for more advanced reasoning, understanding, and execution.
- Gemini Ultra: The largest and most capable of the three, handling highly complex tasks that require advanced AI capabilities.
Future-Proofing and Open-Source Collaboration
Gemini is designed in a way that newer technologies like memory and planning can be easily integrated within the architecture of the model. This future-proofing and Google's plan to make parts of Gemini open-source for more collaborative innovation across the board makes it clear that Google wants Gemini to be an integral part of their decades in the future.
For more information on Gemini AI, visit the Gemini AI, gemini, or AI tags.









