Erwin H. on LinkedIn: #llms #finetuning #gemini #google #cloudai #ai
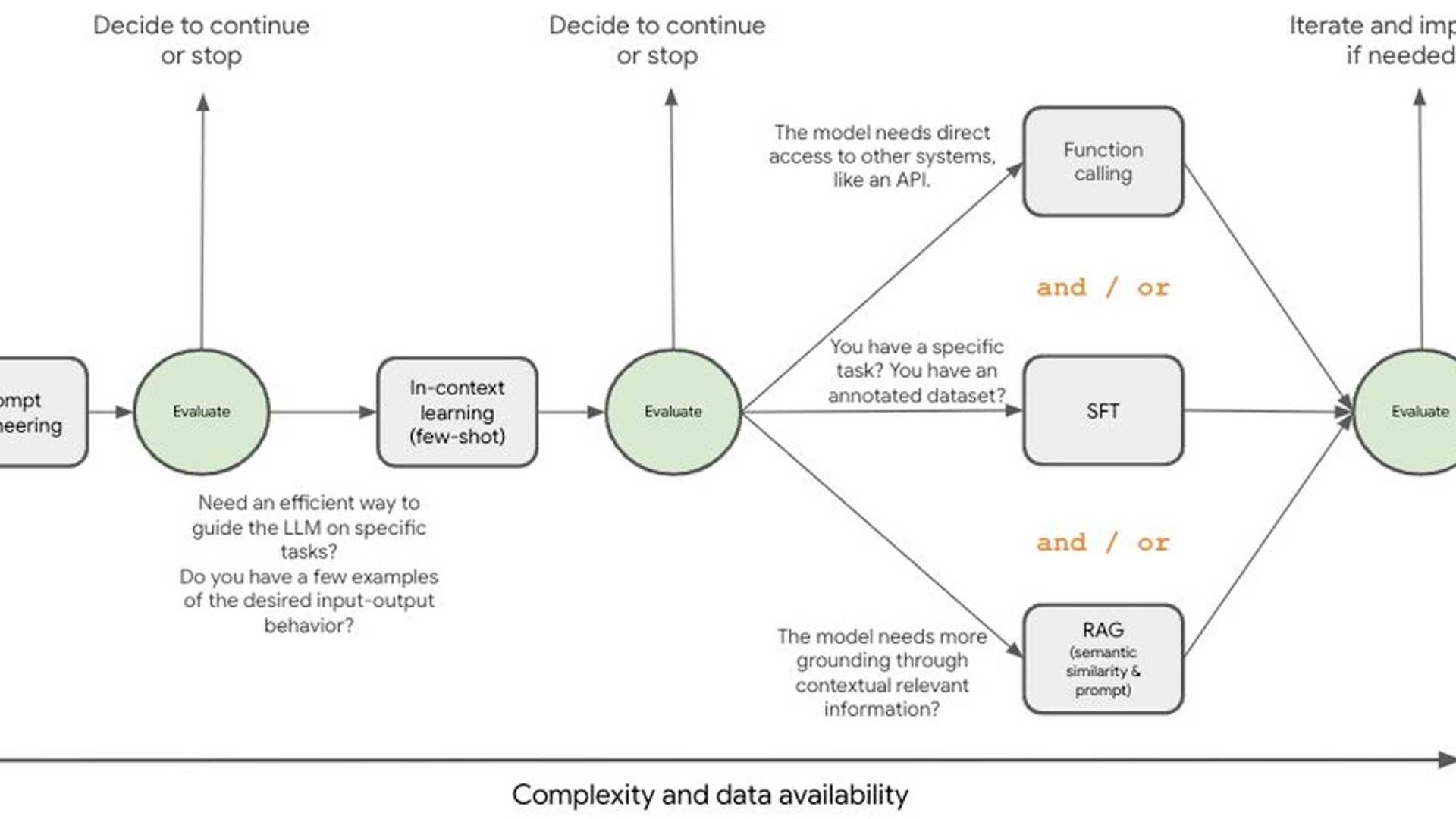
Wondering when to use supervised fine-tuning for Gemini vs relying on prompt engineering or RAG? In our latest blog post with Sihui (May) Hu, we explore when it makes sense to fine-tune Gemini. We'll help you understand supervised fine-tuning and its tradeoffs compared to other techniques, so you can make the right call for your project.
Check out the blog post here.
Excited to be speaking at Big Data & AI World Asia this week (Oct 9-10) 🚀
Join me for a deep dive into fine-tuning Gemini and learn how to adapt this powerful model to your specific needs. I'll be sharing best practices and lessons learned on using parameter-efficient fine-tuning techniques to achieve better performance.
Secure your free spot today by clicking here.
Is the long context window the RAG killer? 🤔
I'm seeing a lot of talk about RAG vs long context windows as if they're competing forces. But we're missing the bigger picture. They're often complementary tools in the LLM toolkit! The key is knowing when to use each.
RAG excels at retrieving up-to-date, contextually relevant information, improving efficiency by focusing on what's most relevant to the query.
Long context windows, on the other hand, allow for deeper contextual understanding and enable more complex reasoning by providing a wider view of the information. It also lets you leverage many-shot in-context learning.
Just like with other tools in the LLM toolkit, it's about stacking them to improve accuracy.
Calling all Asia Pacific innovators! 👋
Want to learn more about building GenAI applications? Join us for Gemini at Work tomorrow and connect with fellow AI enthusiasts, learn from experts, and explore the latest breakthroughs.
Register for the event here.
Join Catherine Wang, Lakshmy Chandran, Subhash Guddad, and Paris Tran at the event.
This is an easy use case. We only need to integrate a good model.
Production is easy!
Production is easy!
Production is easy!









