Malayali researchers find bug in speech recognition AI Indic script evaluation
In a significant development in the field of multilingual automatic speech recognition (ASR), three researchers from Kerala have identified a flaw in the evaluation suite of AI models used by various multinational companies for transcribing texts from Indic scripts.
The team, led by Elizabeth Sherly from the Virtual Resource Centre for Language Computing (VRCLC) at the Digital University Kerala, along with computational linguist Kavya Manohar and research scientist Leena G Pillai, discovered that AI systems faced challenges in accurately evaluating Indian languages such as Malayalam, Hindi, and Tamil.

Issues with Indic languages
Elizabeth explained, "In Google translator, errors are noticeable when Malayalam, a language with multiple vowel signs, is utilized. The ASR models we tested failed to recognize these vowel signs accurately, leading to a low accuracy level during the evaluation stage."
The team found inaccuracies in ASR models developed by companies like Open AI, Meta, Seamless, and Assembly AI. Kavya highlighted that while these companies claim high accuracy for their AI-based ASR models, they often struggle with Indic languages due to the omission of vowel signs in the evaluation process.
Implications of the flaw
When evaluating a Malayalam speech, the AI systems processed the text without considering vowel signs, resulting in distorted transcriptions like 'DAJATTAL YANAVAZHASATTA' instead of 'Digital University'. This issue was also observed in Thai language evaluations.
The research team presented their findings in a paper titled 'What is lost in Normalisation? Exploring Pitfalls in Multilingual ASR Model Evaluation' at the EMNLP 2024 conference. Their work garnered international interest, and the Association of Computational Linguistics (ACL) recognized their efforts by awarding a grant to support the presentation.
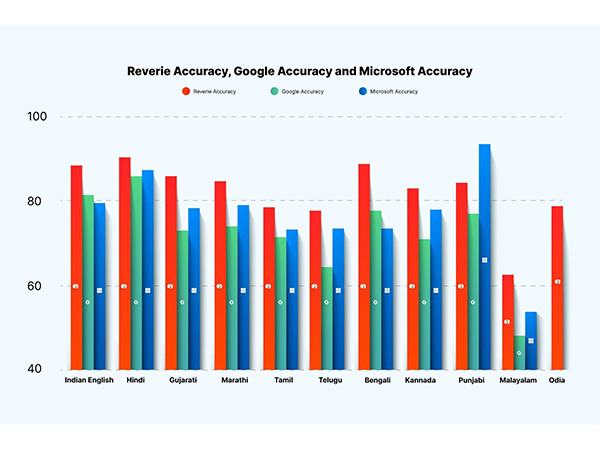
Overall, the discovery by these Malayali researchers sheds light on the need for enhanced accuracy and inclusivity in AI models for multilingual speech recognition.
Follow The New Indian Express channel on WhatsApp