Meta AI releases V-JEPA model: Innovate video understanding and ...
Recently, the Meta AI team launched the video joint embedding prediction architecture (V-JEPA) model, an innovative move aimed at promoting the development of machine intelligence. Humans can naturally process information from visual signals, thereby identifying surrounding objects and motion patterns. An important goal of machine learning is to reveal the basic principles that drive humans to perform unsupervised learning.
The researchers proposed a key hypothesis—the principle of predictive features, which argues that representations of continuous sensory inputs should be able to predict each other. Early research methods used slow feature analysis and spectral techniques to maintain time consistency to prevent representation crashes. Many new approaches now combine contrast learning and masking modeling to ensure representations can evolve over time. Modern technologies not only focus on time invariance but also map characteristic relationships at different time steps by training prediction networks, thereby improving performance.
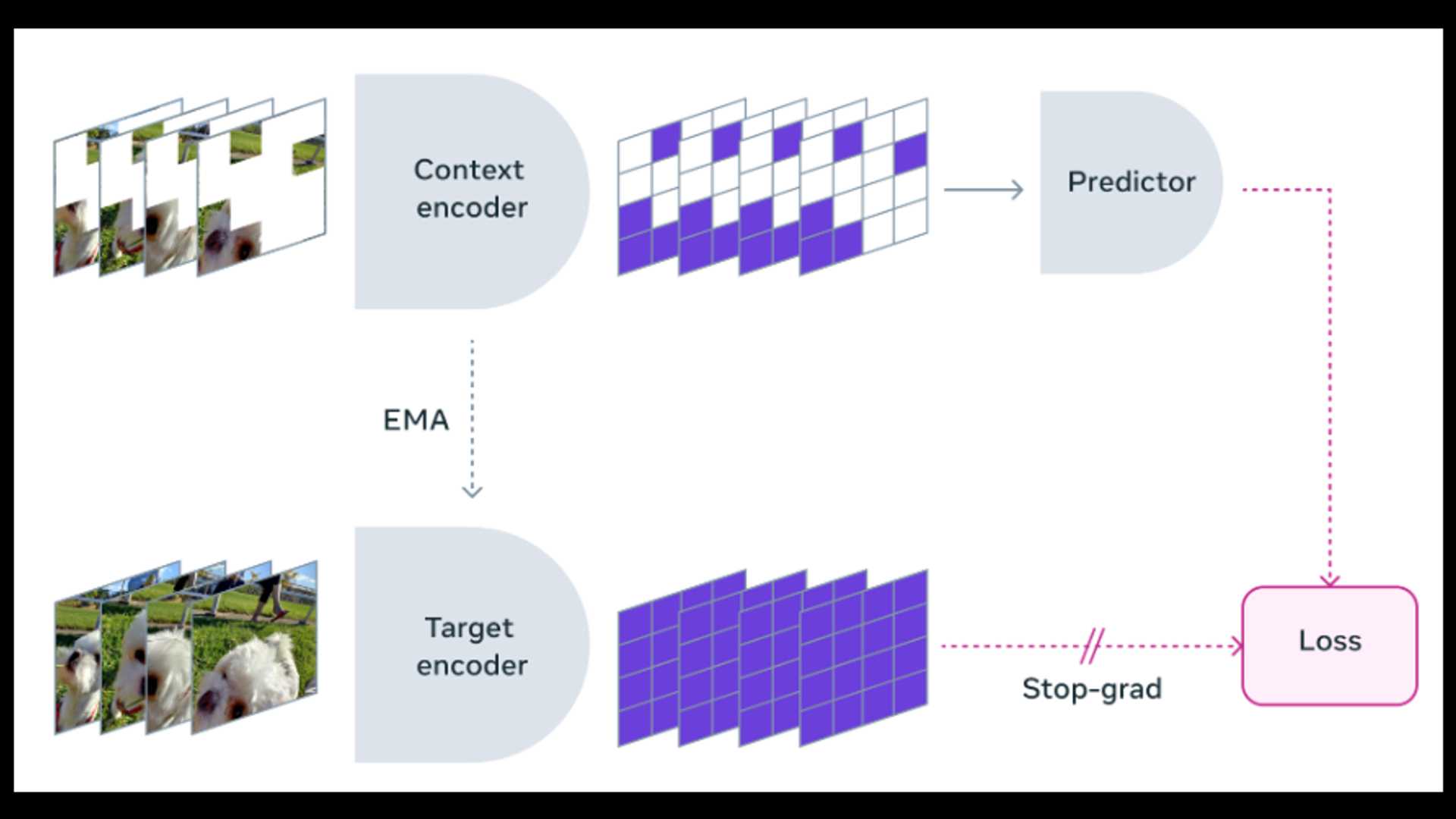
For video data, the application of space-time masking further improves the quality of learning representations. Meta's research team has developed the V-JEPA model in collaboration with several well-known institutions. This model focuses on feature prediction and unsupervised video learning. Unlike traditional methods, it does not rely on pre-trained encoders, negative samples, reconstruction, or text supervision. V-JEPA used two million public videos during training and achieved significant performance on sports and appearance tasks without fine-tuning.

Object-Centered Learning Model
The training method of V-JEPA is to build an object-centered learning model through video data. First, the neural network extracts the representation of the object center from the video frame, capturing motion and appearance features. These representations are further enhanced through comparative learning to improve the separability of objects. Next, the transformer-based architecture processes these representations to simulate temporal interactions between objects. The entire framework is trained on large-scale datasets to optimize reconstruction accuracy and cross-frame consistency.
-min%2525202.jpeg)
Performance and Advantages
V-JEPA performs superiorly in comparison with pixel prediction methods, especially in freezing evaluation, except slightly under-sufficient in ImageNet classification tasks. After fine-tuning, V-JEPA surpasses other methods based on ViT-L/16 models with fewer training samples. V-JEPA performs excellently in motion comprehension and video tasks, is more efficient in training, and is still able to maintain accuracy at low sample settings. This study demonstrates the effectiveness of feature prediction as an independent goal of unsupervised video learning.
V-JEPA performs well in various image and video tasks and surpasses previous video representation methods without parameter adaptation. V-JEPA has advantages in capturing subtle motion details, showing its potential in video comprehension.

If you are interested in artificial intelligence technology, including students, engineers, data scientists, developers, and professionals in AI technology, AI courses are suitable for you. The course content ranges from basic to advanced, catering to beginners and those looking to delve into more complex algorithms and applications.
Learning AI requires a certain mathematical foundation (such as linear algebra, probability theory, calculus, etc.), as well as programming knowledge (Python is the most commonly used programming language). By taking AI courses, you will learn the core concepts and technologies in natural language processing, computer vision, data analysis, and master the use of AI tools and frameworks for practical development.

AI professionals can work as data scientists, machine learning engineers, AI researchers, or apply AI technology to innovate in various industries.
For further reading, you can access the research paper here. Additionally, you can find more insights on V-JEPA in the Meta AI blog here.









